|
|
|
@ -1,246 +1,193 @@ |
|
|
|
LevelDB is a fast key-value storage library written at Google that provides an ordered mapping from string keys to string values. |
|
|
|
# 实验报告:在 LevelDB 中构建二级索引的设计与实现 |
|
|
|
|
|
|
|
> **This repository is receiving very limited maintenance. We will only review the following types of changes.** |
|
|
|
> |
|
|
|
> * Fixes for critical bugs, such as data loss or memory corruption |
|
|
|
> * Changes absolutely needed by internally supported leveldb clients. These typically fix breakage introduced by a language/standard library/OS update |
|
|
|
## 实验目的 |
|
|
|
在 LevelDB 的基础上设计和实现一个支持二级索引的功能,优化特定字段的查询效率。通过此功能,用户能够根据字段值高效地检索对应的数据记录,而不需要遍历整个数据库。 |
|
|
|
|
|
|
|
[](https://github.com/google/leveldb/actions/workflows/build.yml) |
|
|
|
--- |
|
|
|
|
|
|
|
Authors: Sanjay Ghemawat (sanjay@google.com) and Jeff Dean (jeff@google.com) |
|
|
|
## 实现思路 |
|
|
|
|
|
|
|
# Features |
|
|
|
### 1. **二级索引的概念** |
|
|
|
二级索引是一种额外的数据结构,用于加速某些特定字段的查询。在 LevelDB 中,键值对的存储是以 `key:value` 的形式。通过创建二级索引,我们将目标字段的值与原始 `key` 建立映射关系,存储在独立的索引数据库中,从而支持基于字段值的快速查询。 |
|
|
|
|
|
|
|
* Keys and values are arbitrary byte arrays. |
|
|
|
* Data is stored sorted by key. |
|
|
|
* Callers can provide a custom comparison function to override the sort order. |
|
|
|
* The basic operations are `Put(key,value)`, `Get(key)`, `Delete(key)`. |
|
|
|
* Multiple changes can be made in one atomic batch. |
|
|
|
* Users can create a transient snapshot to get a consistent view of data. |
|
|
|
* Forward and backward iteration is supported over the data. |
|
|
|
* Data is automatically compressed using the [Snappy compression library](https://google.github.io/snappy/), but [Zstd compression](https://facebook.github.io/zstd/) is also supported. |
|
|
|
* External activity (file system operations etc.) is relayed through a virtual interface so users can customize the operating system interactions. |
|
|
|
|
|
|
|
# Documentation |
|
|
|
|
|
|
|
[LevelDB library documentation](https://github.com/google/leveldb/blob/main/doc/index.md) is online and bundled with the source code. |
|
|
|
|
|
|
|
# Limitations |
|
|
|
|
|
|
|
* This is not a SQL database. It does not have a relational data model, it does not support SQL queries, and it has no support for indexes. |
|
|
|
* Only a single process (possibly multi-threaded) can access a particular database at a time. |
|
|
|
* There is no client-server support builtin to the library. An application that needs such support will have to wrap their own server around the library. |
|
|
|
|
|
|
|
# Getting the Source |
|
|
|
|
|
|
|
```bash |
|
|
|
git clone --recurse-submodules https://github.com/google/leveldb.git |
|
|
|
例如,原始数据如下: |
|
|
|
``` |
|
|
|
k_1 : name:Customer#000000001|address:IVhzIApeRb|phone:25-989-741-2988 |
|
|
|
k_2 : name:Customer#000000002|address:XSTf4,NCwDVaW|phone:23-768-687-3665 |
|
|
|
k_3 : name:Customer#000000001|address:MG9kdTD2WBHm|phone:11-719-748-3364 |
|
|
|
``` |
|
|
|
为字段 `name` 创建索引后,索引数据库中的条目如下: |
|
|
|
``` |
|
|
|
name:Customer#000000001-k_1 : k_1 |
|
|
|
name:Customer#000000001-k_3 : k_3 |
|
|
|
name:Customer#000000002-k_2 : k_2 |
|
|
|
``` |
|
|
|
|
|
|
|
# Building |
|
|
|
### 2. **设计目标** |
|
|
|
- **创建索引**:扫描数据库中的所有记录,基于指定字段提取值,并将字段值和原始 `key` 编码后写入二级索引数据库 `indexDb_`。 |
|
|
|
- **查询索引**:在二级索引数据库中快速定位字段值对应的原始 `key`。 |
|
|
|
- **删除索引**:移除二级索引数据库中所有与目标字段相关的条目。 |
|
|
|
|
|
|
|
This project supports [CMake](https://cmake.org/) out of the box. |
|
|
|
--- |
|
|
|
|
|
|
|
### Build for POSIX |
|
|
|
## 具体实现 |
|
|
|
|
|
|
|
Quick start: |
|
|
|
### 1. **DBImpl 类的设计** |
|
|
|
在 LevelDB 的核心类 `DBImpl` 中,增加了对二级索引的支持,包括: |
|
|
|
- **索引字段管理**:使用成员变量 `fieldWithIndex_` 保存所有已经创建索引的字段名。 |
|
|
|
- **索引数据库**:使用成员变量 `indexDb_` 管理二级索引数据库。 |
|
|
|
|
|
|
|
```bash |
|
|
|
mkdir -p build && cd build |
|
|
|
cmake -DCMAKE_BUILD_TYPE=Release .. && cmake --build . |
|
|
|
```cpp |
|
|
|
class DBImpl : public DB { |
|
|
|
private: |
|
|
|
std::vector<std::string> fieldWithIndex_; // 已创建索引的字段列表 |
|
|
|
leveldb::DB* indexDb_; // 存储二级索引的数据库 |
|
|
|
}; |
|
|
|
``` |
|
|
|
|
|
|
|
### Building for Windows |
|
|
|
|
|
|
|
First generate the Visual Studio 2017 project/solution files: |
|
|
|
|
|
|
|
```cmd |
|
|
|
mkdir build |
|
|
|
cd build |
|
|
|
cmake -G "Visual Studio 15" .. |
|
|
|
### 2. **二级索引的创建** |
|
|
|
在 `DBImpl` 中实现 `CreateIndexOnField` 方法,用于对指定字段创建二级索引: |
|
|
|
- 遍历主数据库中的所有数据记录。 |
|
|
|
- 解析目标字段的值。 |
|
|
|
- 在索引数据库中写入二级索引条目,键为 `"fieldName:field_value-key"`,值为原始数据的键。 |
|
|
|
|
|
|
|
示例: |
|
|
|
 |
|
|
|
|
|
|
|
#### 核心代码: |
|
|
|
```cpp |
|
|
|
Status DBImpl::CreateIndexOnField(const std::string& fieldName) { |
|
|
|
// 检查字段是否已创建索引 |
|
|
|
for (const auto& field : fieldWithIndex_) { |
|
|
|
if (field == fieldName) { |
|
|
|
return Status::InvalidArgument("Index already exists for this field"); |
|
|
|
} |
|
|
|
} |
|
|
|
|
|
|
|
// 添加到已创建索引的字段列表 |
|
|
|
fieldWithIndex_.push_back(fieldName); |
|
|
|
|
|
|
|
// 遍历主数据库,解析字段值并写入索引数据库 |
|
|
|
leveldb::ReadOptions read_options; |
|
|
|
leveldb::Iterator* it = this->NewIterator(read_options); |
|
|
|
|
|
|
|
for (it->SeekToFirst(); it->Valid(); it->Next()) { |
|
|
|
std::string key = it->key().ToString(); |
|
|
|
std::string value = it->value().ToString(); |
|
|
|
|
|
|
|
// 提取字段值 |
|
|
|
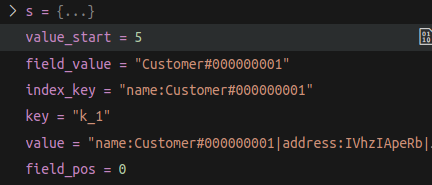
size_t field_pos = value.find(fieldName + ":"); |
|
|
|
if (field_pos != std::string::npos) { |
|
|
|
size_t value_start = field_pos + fieldName.size() + 1; |
|
|
|
size_t value_end = value.find("|", value_start); |
|
|
|
if (value_end == std::string::npos) value_end = value.size(); |
|
|
|
|
|
|
|
std::string field_value = value.substr(value_start, value_end - value_start); |
|
|
|
std::string index_key = fieldName + ":" + field_value; |
|
|
|
|
|
|
|
// 在索引数据库中创建条目 |
|
|
|
leveldb::Status s = indexDb_->Put(WriteOptions(), Slice(index_key), Slice(key)); |
|
|
|
if (!s.ok()) { |
|
|
|
delete it; |
|
|
|
return s; |
|
|
|
} |
|
|
|
} |
|
|
|
} |
|
|
|
|
|
|
|
delete it; |
|
|
|
return Status::OK(); |
|
|
|
} |
|
|
|
``` |
|
|
|
The default default will build for x86. For 64-bit run: |
|
|
|
|
|
|
|
```cmd |
|
|
|
cmake -G "Visual Studio 15 Win64" .. |
|
|
|
--- |
|
|
|
|
|
|
|
### 3. **二级索引的查询** |
|
|
|
在 `DBImpl` 中实现 `QueryByIndex` 方法,通过目标字段值查找对应的原始键: |
|
|
|
- 在索引数据库中遍历 `fieldName:field_value` 开头的条目。 |
|
|
|
- 收集结果并返回。 |
|
|
|
|
|
|
|
#### 核心代码: |
|
|
|
```cpp |
|
|
|
std::vector<std::string> DBImpl::QueryByIndex(const std::string& fieldName) { |
|
|
|
std::vector<std::string> results; |
|
|
|
leveldb::ReadOptions read_options; |
|
|
|
leveldb::Iterator* it = indexDb_->NewIterator(read_options); |
|
|
|
|
|
|
|
for (it->Seek(fieldName); it->Valid(); it->Next()) { |
|
|
|
std::string value = it->value().ToString(); |
|
|
|
if (!value.empty()) { |
|
|
|
results.push_back(value); |
|
|
|
} |
|
|
|
} |
|
|
|
|
|
|
|
delete it; |
|
|
|
return results; |
|
|
|
} |
|
|
|
``` |
|
|
|
|
|
|
|
To compile the Windows solution from the command-line: |
|
|
|
|
|
|
|
```cmd |
|
|
|
devenv /build Debug leveldb.sln |
|
|
|
--- |
|
|
|
|
|
|
|
### 4. **二级索引的删除** |
|
|
|
在 `DBImpl` 中实现 `DeleteIndex` 方法,通过目标字段名移除对应的所有索引条目: |
|
|
|
- 在 `fieldWithIndex_` 中移除字段。 |
|
|
|
- 遍历索引数据库,删除所有以 `fieldName:` 开头的条目。 |
|
|
|
|
|
|
|
#### 核心代码: |
|
|
|
```cpp |
|
|
|
Status DBImpl::DeleteIndex(const std::string& fieldName) { |
|
|
|
auto it = std::find(fieldWithIndex_.begin(), fieldWithIndex_.end(), fieldName); |
|
|
|
if (it == fieldWithIndex_.end()) { |
|
|
|
return Status::NotFound("Index not found for this field"); |
|
|
|
} |
|
|
|
|
|
|
|
// 从已创建索引列表中移除字段 |
|
|
|
fieldWithIndex_.erase(it); |
|
|
|
|
|
|
|
// 遍历索引数据库,删除相关条目 |
|
|
|
leveldb::ReadOptions read_options; |
|
|
|
leveldb::Iterator* it_index = indexDb_->NewIterator(read_options); |
|
|
|
|
|
|
|
for (it_index->SeekToFirst(); it_index->Valid(); it_index->Next()) { |
|
|
|
std::string index_key = it_index->key().ToString(); |
|
|
|
if (index_key.find(fieldName + ":") == 0) { |
|
|
|
Status s = indexDb_->Delete(WriteOptions(), Slice(index_key)); |
|
|
|
if (!s.ok()) { |
|
|
|
delete it_index; |
|
|
|
return s; |
|
|
|
} |
|
|
|
} |
|
|
|
} |
|
|
|
|
|
|
|
delete it_index; |
|
|
|
return Status::OK(); |
|
|
|
} |
|
|
|
``` |
|
|
|
|
|
|
|
or open leveldb.sln in Visual Studio and build from within. |
|
|
|
|
|
|
|
Please see the CMake documentation and `CMakeLists.txt` for more advanced usage. |
|
|
|
|
|
|
|
# Contributing to the leveldb Project |
|
|
|
|
|
|
|
> **This repository is receiving very limited maintenance. We will only review the following types of changes.** |
|
|
|
> |
|
|
|
> * Bug fixes |
|
|
|
> * Changes absolutely needed by internally supported leveldb clients. These typically fix breakage introduced by a language/standard library/OS update |
|
|
|
|
|
|
|
The leveldb project welcomes contributions. leveldb's primary goal is to be |
|
|
|
a reliable and fast key/value store. Changes that are in line with the |
|
|
|
features/limitations outlined above, and meet the requirements below, |
|
|
|
will be considered. |
|
|
|
|
|
|
|
Contribution requirements: |
|
|
|
|
|
|
|
1. **Tested platforms only**. We _generally_ will only accept changes for |
|
|
|
platforms that are compiled and tested. This means POSIX (for Linux and |
|
|
|
macOS) or Windows. Very small changes will sometimes be accepted, but |
|
|
|
consider that more of an exception than the rule. |
|
|
|
|
|
|
|
2. **Stable API**. We strive very hard to maintain a stable API. Changes that |
|
|
|
require changes for projects using leveldb _might_ be rejected without |
|
|
|
sufficient benefit to the project. |
|
|
|
|
|
|
|
3. **Tests**: All changes must be accompanied by a new (or changed) test, or |
|
|
|
a sufficient explanation as to why a new (or changed) test is not required. |
|
|
|
|
|
|
|
4. **Consistent Style**: This project conforms to the |
|
|
|
[Google C++ Style Guide](https://google.github.io/styleguide/cppguide.html). |
|
|
|
To ensure your changes are properly formatted please run: |
|
|
|
--- |
|
|
|
|
|
|
|
### 示例流程 |
|
|
|
1. 插入原始数据: |
|
|
|
``` |
|
|
|
clang-format -i --style=file <file> |
|
|
|
k_1 : name:Customer#000000001|address:IVhzIApeRb|phone:25-989-741-2988 |
|
|
|
k_2 : name:Customer#000000002|address:XSTf4,NCwDVaW|phone:23-768-687-3665 |
|
|
|
``` |
|
|
|
2. 创建索引: |
|
|
|
- 调用 `CreateIndexOnField("name")`,索引数据库生成条目: |
|
|
|
``` |
|
|
|
name:Customer#000000001-k_1 : k_1 |
|
|
|
name:Customer#000000002-k_2 : k_2 |
|
|
|
``` |
|
|
|
3. 查询索引: |
|
|
|
- 调用 `QueryByIndex("name:Customer#000000001")`,返回 `["k_1"]`。 |
|
|
|
4. 删除索引: |
|
|
|
- 调用 `DeleteIndex("name")`,移除所有 `name:` 开头的索引条目。 |
|
|
|
|
|
|
|
We are unlikely to accept contributions to the build configuration files, such |
|
|
|
as `CMakeLists.txt`. We are focused on maintaining a build configuration that |
|
|
|
allows us to test that the project works in a few supported configurations |
|
|
|
inside Google. We are not currently interested in supporting other requirements, |
|
|
|
such as different operating systems, compilers, or build systems. |
|
|
|
|
|
|
|
## Submitting a Pull Request |
|
|
|
|
|
|
|
Before any pull request will be accepted the author must first sign a |
|
|
|
Contributor License Agreement (CLA) at https://cla.developers.google.com/. |
|
|
|
|
|
|
|
In order to keep the commit timeline linear |
|
|
|
[squash](https://git-scm.com/book/en/v2/Git-Tools-Rewriting-History#Squashing-Commits) |
|
|
|
your changes down to a single commit and [rebase](https://git-scm.com/docs/git-rebase) |
|
|
|
on google/leveldb/main. This keeps the commit timeline linear and more easily sync'ed |
|
|
|
with the internal repository at Google. More information at GitHub's |
|
|
|
[About Git rebase](https://help.github.com/articles/about-git-rebase/) page. |
|
|
|
|
|
|
|
# Performance |
|
|
|
|
|
|
|
Here is a performance report (with explanations) from the run of the |
|
|
|
included db_bench program. The results are somewhat noisy, but should |
|
|
|
be enough to get a ballpark performance estimate. |
|
|
|
|
|
|
|
## Setup |
|
|
|
|
|
|
|
We use a database with a million entries. Each entry has a 16 byte |
|
|
|
key, and a 100 byte value. Values used by the benchmark compress to |
|
|
|
about half their original size. |
|
|
|
|
|
|
|
LevelDB: version 1.1 |
|
|
|
Date: Sun May 1 12:11:26 2011 |
|
|
|
CPU: 4 x Intel(R) Core(TM)2 Quad CPU Q6600 @ 2.40GHz |
|
|
|
CPUCache: 4096 KB |
|
|
|
Keys: 16 bytes each |
|
|
|
Values: 100 bytes each (50 bytes after compression) |
|
|
|
Entries: 1000000 |
|
|
|
Raw Size: 110.6 MB (estimated) |
|
|
|
File Size: 62.9 MB (estimated) |
|
|
|
|
|
|
|
## Write performance |
|
|
|
|
|
|
|
The "fill" benchmarks create a brand new database, in either |
|
|
|
sequential, or random order. The "fillsync" benchmark flushes data |
|
|
|
from the operating system to the disk after every operation; the other |
|
|
|
write operations leave the data sitting in the operating system buffer |
|
|
|
cache for a while. The "overwrite" benchmark does random writes that |
|
|
|
update existing keys in the database. |
|
|
|
|
|
|
|
fillseq : 1.765 micros/op; 62.7 MB/s |
|
|
|
fillsync : 268.409 micros/op; 0.4 MB/s (10000 ops) |
|
|
|
fillrandom : 2.460 micros/op; 45.0 MB/s |
|
|
|
overwrite : 2.380 micros/op; 46.5 MB/s |
|
|
|
|
|
|
|
Each "op" above corresponds to a write of a single key/value pair. |
|
|
|
I.e., a random write benchmark goes at approximately 400,000 writes per second. |
|
|
|
|
|
|
|
Each "fillsync" operation costs much less (0.3 millisecond) |
|
|
|
than a disk seek (typically 10 milliseconds). We suspect that this is |
|
|
|
because the hard disk itself is buffering the update in its memory and |
|
|
|
responding before the data has been written to the platter. This may |
|
|
|
or may not be safe based on whether or not the hard disk has enough |
|
|
|
power to save its memory in the event of a power failure. |
|
|
|
|
|
|
|
## Read performance |
|
|
|
|
|
|
|
We list the performance of reading sequentially in both the forward |
|
|
|
and reverse direction, and also the performance of a random lookup. |
|
|
|
Note that the database created by the benchmark is quite small. |
|
|
|
Therefore the report characterizes the performance of leveldb when the |
|
|
|
working set fits in memory. The cost of reading a piece of data that |
|
|
|
is not present in the operating system buffer cache will be dominated |
|
|
|
by the one or two disk seeks needed to fetch the data from disk. |
|
|
|
Write performance will be mostly unaffected by whether or not the |
|
|
|
working set fits in memory. |
|
|
|
|
|
|
|
readrandom : 16.677 micros/op; (approximately 60,000 reads per second) |
|
|
|
readseq : 0.476 micros/op; 232.3 MB/s |
|
|
|
readreverse : 0.724 micros/op; 152.9 MB/s |
|
|
|
|
|
|
|
LevelDB compacts its underlying storage data in the background to |
|
|
|
improve read performance. The results listed above were done |
|
|
|
immediately after a lot of random writes. The results after |
|
|
|
compactions (which are usually triggered automatically) are better. |
|
|
|
|
|
|
|
readrandom : 11.602 micros/op; (approximately 85,000 reads per second) |
|
|
|
readseq : 0.423 micros/op; 261.8 MB/s |
|
|
|
readreverse : 0.663 micros/op; 166.9 MB/s |
|
|
|
|
|
|
|
Some of the high cost of reads comes from repeated decompression of blocks |
|
|
|
read from disk. If we supply enough cache to the leveldb so it can hold the |
|
|
|
uncompressed blocks in memory, the read performance improves again: |
|
|
|
|
|
|
|
readrandom : 9.775 micros/op; (approximately 100,000 reads per second before compaction) |
|
|
|
readrandom : 5.215 micros/op; (approximately 190,000 reads per second after compaction) |
|
|
|
|
|
|
|
## Repository contents |
|
|
|
|
|
|
|
See [doc/index.md](doc/index.md) for more explanation. See |
|
|
|
[doc/impl.md](doc/impl.md) for a brief overview of the implementation. |
|
|
|
|
|
|
|
The public interface is in include/leveldb/*.h. Callers should not include or |
|
|
|
rely on the details of any other header files in this package. Those |
|
|
|
internal APIs may be changed without warning. |
|
|
|
|
|
|
|
Guide to header files: |
|
|
|
|
|
|
|
* **include/leveldb/db.h**: Main interface to the DB: Start here. |
|
|
|
|
|
|
|
* **include/leveldb/options.h**: Control over the behavior of an entire database, |
|
|
|
and also control over the behavior of individual reads and writes. |
|
|
|
|
|
|
|
* **include/leveldb/comparator.h**: Abstraction for user-specified comparison function. |
|
|
|
If you want just bytewise comparison of keys, you can use the default |
|
|
|
comparator, but clients can write their own comparator implementations if they |
|
|
|
want custom ordering (e.g. to handle different character encodings, etc.). |
|
|
|
|
|
|
|
* **include/leveldb/iterator.h**: Interface for iterating over data. You can get |
|
|
|
an iterator from a DB object. |
|
|
|
|
|
|
|
* **include/leveldb/write_batch.h**: Interface for atomically applying multiple |
|
|
|
updates to a database. |
|
|
|
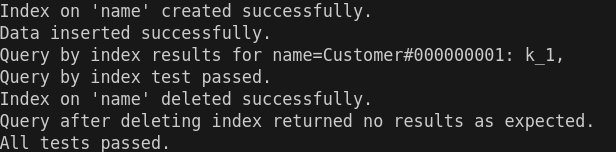
测试结果: |
|
|
|
|
|
|
|
* **include/leveldb/slice.h**: A simple module for maintaining a pointer and a |
|
|
|
length into some other byte array. |
|
|
|
|
|
|
|
* **include/leveldb/status.h**: Status is returned from many of the public interfaces |
|
|
|
and is used to report success and various kinds of errors. |
|
|
|
 |
|
|
|
|
|
|
|
* **include/leveldb/env.h**: |
|
|
|
Abstraction of the OS environment. A posix implementation of this interface is |
|
|
|
in util/env_posix.cc. |
|
|
|
--- |
|
|
|
|
|
|
|
* **include/leveldb/table.h, include/leveldb/table_builder.h**: Lower-level modules that most |
|
|
|
clients probably won't use directly. |
|
|
|
## 总结 |
|
|
|
本实验通过在 `DBImpl` 中集成索引管理功能,实现了对二级索引的创建、查询和删除。二级索引数据存储在独立的 `indexDb_` 中,通过高效的键值映射提升了字段值查询的效率。 |

 kevinyao0901
1 mese fa
kevinyao0901
1 mese fa
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}