
You can not select more than 25 topics
Topics must start with a letter or number, can include dashes ('-') and can be up to 35 characters long.
 VirgilZhu
1f1a6de7b2
VirgilZhu
1f1a6de7b2
|
8 months ago | ||
|---|---|---|---|
| .github/workflows | 删除 | 2 years ago | |
| benchmarks | 删除 | 2 years ago | |
| cmake | 删除 | 5 years ago | |
| db | 删除 | 8 months ago | |
| doc | 删除 | 3 years ago | |
| helpers/memenv | 删除 | 8 months ago | |
| image | 删除 | 10 months ago | |
| include/leveldb | 删除 | 8 months ago | |
| issues | 删除 | 3 years ago | |
| port | 删除 | 2 years ago | |
| table | 删除 | 8 months ago | |
| test | 删除 | 9 months ago | |
| third_party | 删除 | 2 years ago | |
| util | 删除 | 8 months ago | |
| .clang-format | 6 years ago | ||
| .gitignore | 11 months ago | ||
| .gitmodules | 4 years ago | ||
| AUTHORS | 12 years ago | ||
| CMakeLists.txt | 9 months ago | ||
| CONTRIBUTING.md | 3 years ago | ||
| LICENSE | 14 years ago | ||
| NEWS | 14 years ago | ||
| README.md | 9 months ago | ||
| TODO | 13 years ago | ||
README.md
LevelDB: Value Field & KV Separation 设计文档
项目概述
**项目背景:**LevelDB 项目的 KV 键值对存储信息单一;LSM-Tree 读写放大开销大,导致 LevelDB 顺序范围查询时的数据吞吐量随 Value 大小增加而急剧下降。
项目目标 & 实现目的
- 实现 LevelDB 的 value 字段功能:
- 实现类似 关系数据库-表格-列 和 文档数据库-文档-字段 的多字段功能设计;
- 提供高效的接口来读写 value、通过 value 查询多个匹配的 Key;
- 使 LevelDB 同时具有 高性能读写大量键值对 和 多字段数据存储 的功能。
- 实现类似 关系数据库-表格-列 和 文档数据库-文档-字段 的多字段功能设计;
- 实现 KV 分离(分离存储、点查、范围查询、GC 机制):
- 减小 LevelDB 的读写放大;
- 减小 LSM-Tree 的层级;
- Compaction 不需重写 value;
- 一个 SSTable 的 Block 能存更多 Key,有利于减少读 LSM-Tree 的开销;
- Cache 能储存更多 SSTable,减少磁盘 I/O 开销。
- 实现 Benchmark,测试并分析性能:
- 验证功能扩展(value 多字段设计 & KV 分离)的有效性;
- 评估性能提升(读写 Throughput 性能、读写放大、LSM-Tree 层级、随机点查/顺序范围查询效率(延迟)、GC 开销与性能影响、各读写阶段耗时占比 (Wait / Log / Memtable / Other));
- 分析资源利用率(硬盘 I/O 、内存负载);
- 比较大/小数据集、高并发场景的表现;
- 找到性能瓶颈并针对优化。
功能设计
2.1 字段设计
- 设计目标:
- 将 value 设计为一个字段数组,每个元素对应一个字段
Field:field_name: field_value; - 对于 value 存储时的字符串类型值与真实含义的字段数组,采用字段数组的序列化与字符串的解析实现两者的转化;
- 允许在存储 KV 键值对前修改字段内容;
- 允许通过字段值查询所有对应的 key。
- 将 value 设计为一个字段数组,每个元素对应一个字段
- 实现思路:
- 定义一个
Fields类来管理LevelDB中的字段。其中Field是使用标准库中的std::pair<std::string, std::string>定义了单个字段的格式,而FieldArray则是使用了std::vector<Field>来定义一组字段。 - 定义
fields_这一私有成员变量,它是一个FieldArray类型的向量,用来存储一组字段。 - 定义一系列的构造函数来支持从不同类型的参数创建
Fields对象。 - 定义了
SortFields方法来确保在创建Fields对象时,各个字段会根据field_name从小到大进行排序,进而减少后续更新删除操作中会出现的通过field_name遍历Fields的耗时。 - 定义了
UpdateField和UpdateFields方法允许用户更新或插入单个或多个字段,以及DeleteField和DeleteFields方法允许用户删除单个或多个字段。实现思路是通过遍历fields_来查找匹配的field_name并对其进行更新(若不存在则插入)以及删除操作(⭐在上述操作的实现中,由于字段列表的有序性,遍历时可通过比较field_name大小来提前判断该字段是否存在,对于小字段的查找尤其明显,进而有效减少搜索时间,提高搜索效率。) - 定义
SerializeValue和ParseValue方法分别用于将字段序列化为字符串或将字符串反序列化为字段对象。实现时是调用了conding.h文件中的PutLengthPrefixedSlice函数以及GetLengthPrefixedSlice函数,它们的作用分别是对一个string进行编码并在其前面加入长度信息和将编码后的string中的长度信息去除,提取出原始string。这两个函数不仅可以完美实现我们对字段编码的最初设计,同时也和lsm-tree里原来所有的kv数据对的编码保持一致。 - 定义
GetField和HasField方法用于访问特定字段和检查字段是否存在,实现思路与更新删除操作类似,也是对fields_进行遍历。 - 重载
[]运算符,以提供类似字典的字段访问方式。对于常量对象,operator[]返回字段值的副本,如果给定的字段名不存在,则返回一个空字符串,并输出错误信息。而对于非常量对象,operator[]返回字段值的引用,并允许修改该字段值。如果给定的字段名不存在,则会插入一个新的字段,并返回新字段值的引用。 - 定义了一个静态方法
FindKeysByFields用于根据若干个字段在数据库中查找对应的键。实现上是使用LevelDB提供的API创建一个NewIterator,从数据库的第一个条目遍历到最后一个条目。事先定义了find_keys来存储找到的键,在遍历过程中,为了避免重复处理同一个键,会先检查当前键是否已经存在于find_keys中。如果存在,则跳过此条目。若不存在,则提取其value部分,利用ParseValue方法将字符串形式的值解析为Fields对象,进而获得该条目对应的字段数组。再对解析后的字段数组与search_fields_进行匹配,这里支持完全匹配和部分匹配,将匹配的key存入find_keys中,最后返回find_keys。(💡Tips:在使用Iterator进行遍历时,it.key()和it.value()获取的其实是kv字符串本身,不需要我们再解码kv length和考虑tag(ktypevalue、ktypedeletion)。我们在设计之初并未考虑到这一点,是在后续测试的debug中发现了这一情况)
- 定义一个
2.2 KV 分离
- 设计目标:
-
- 对于大 value,分离 KV 存储,减小 LevelDB 的读写放大;
- 对于小 value,以 KV 键值对的正常形式存入 LSM-Tree;
- 对于 vLog 有 GC 机制,可以定期和在 vLog 超出限制大小时触发,回收 vLog 中的失效 value 并更新 vLog 与 LSM-Tree;
- 确保操作的原子性。
-
- 实现思路:
- vLog 有若干个,仅保存大于阈值的大 value 对应的 KV 数据对,且为 Append-Only,仅有一个 vLog 是活跃的(可插入新 value 与 key),具有一个垃圾计数器,当计数器超过阈值,触发 GC,并被重写;
- 原 LSM-Tree 中的 KV 键值对,大 value(value 存入 vLog 的情况)改为
<key, <fileno, offset>>的形式;小 value 则与原 LevelDB SSTable 中 KV 键值对存储格式相同; - 当前活跃的 vLog 超过限制大小后,新建一个文件作为新的活跃 vLog;
- 将大 value 写入当前活跃 vLog 后,获得该 value 在 vLog 的
offset和 vLog 的编号fileno,将<key, <fileno, offset>>写入 WAL 和 Memtable 中; - GC 的触发时机为某个 vLog 的垃圾计数器到达阈值时,GC 过程重写目标 vLog 时,若当前处理的 KV 键值对的 key 在 LSM-Tree 中不存在或已更新,则忽略这个 KV 键值对;
- 新的 vLog 被重写完毕后,更新 vLog 中 KV 的新
<fileno, offset>到 LSM-Tree 中; - 为了避免以下情况:用户在之前的时间戳删除了 LSM-Tree 中的某个 key,但当前时间戳 GC 导致重写后的 vLog 中的 KV 键值对被回写到 LSM-Tree 中更高层的 SSTable,相当于该 key 对应的 KV 键值对被额外重新插入了,新写入数据在旧写入数据下层的问题——每次读取数据需要遍历查找每一层的所有 SSTable。
- 新的 vLog 被重写完毕后,更新 vLog 中 KV 的新
数据结构设计
3.1 字段功能
Field&FieldArray:using Field = std::pair<std::string, std::string>;using FieldArray = std::vector<std::pair<std::string, std::string>>;class Fields,用于操作字段数组。
3.2 KV 分离
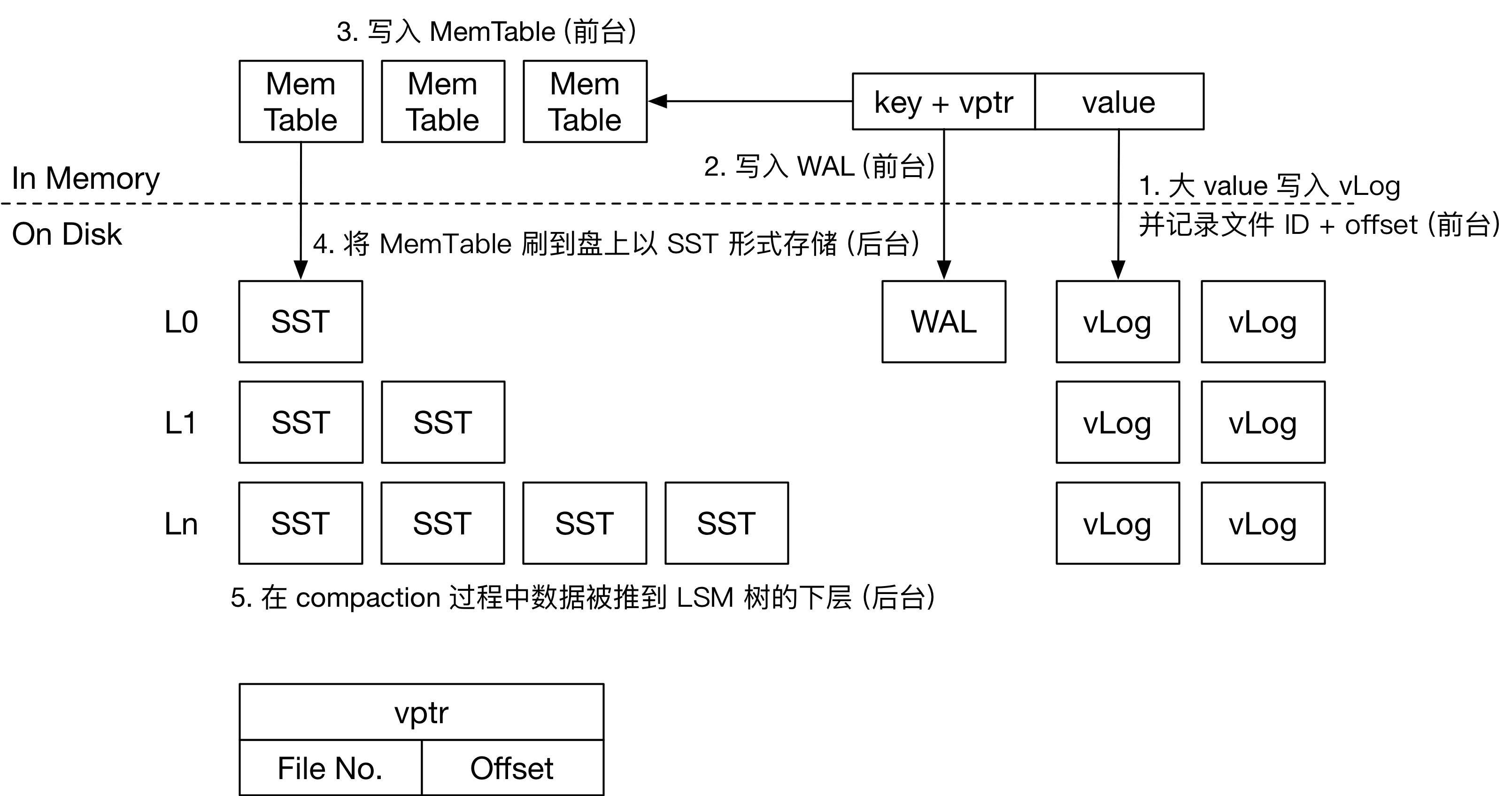
接口/函数设计
4.1 字段功能
-
class Fieldsclass Fields { private: FieldArray fields_; public: /* 从 FieldArray 构造 */ explicit Fields(const FieldArray& fields); /* 从单个 Field 构造 */ explicit Fields(const Field& field); /* 只传参 field_name 数组的构造 */ explicit Fields(const std::vector<std::string>& field_names); Fields() = default; ~Fields() = default; /* 根据 field_name 从小到大进行排序,减少通过 field_name 遍历 Fields 的耗时 */ void SortFields(); /* 更新/插入单个字段值,插入后会进行 Fields 排序,减少通过 field_name 遍历 Fields 的耗时 */ void UpdateField(const std::string& field_name, const std::string& field_value); void UpdateField(const Field& field); /* 更新/插入多个字段值 */ void UpdateFields(const std::vector<std::string>& field_names, const std::vector<std::string>& field_values); void UpdateFields(const FieldArray& fields); /* 删除单个字段 */ void DeleteField(const std::string& field_name); /* 删除多个字段 */ void DeleteFields(const std::vector<std::string>& field_names); /* 序列化 Field 或 FieldArray 为 value 字符串 */ /* static 修饰的函数序列化/反序列化无需访问一个 Fields 对象的 fields_ */ static std::string SerializeValue(const FieldArray& fields); static std::string SerializeValue(const Field& field); std::string SerializeValue() const; /* 反序列化 value 字符串为 Fields */ static Fields ParseValue(const std::string& value_str); /* 获取字段 */ Field GetField(const std::string& field_name) const; /* 检查字段是否存在 */ bool HasField(const std::string& field_name) const; /* 重载运算符 [] 用于访问字段值 */ std::string operator[](const std::string& field_name) const; /* 重载运算符 [] 用于修改字段值 */ std::string& operator[](const std::string& field_name); /* 通过若干个字段查询 Key */ static std::vector<std::string> FindKeysByFields(leveldb::DB* db, const FieldArray& fields); };
4.2 KV 分离
-
大 value 的 key 对应的 value 存储位置:
VPtrstruct VPtr { int fileno; // VLog 文件号 uint64_t offset; // 偏移量 }; -
class VLogclass VLog { private: // 该 VLog 是否活跃,即可插值 bool activate_; // 最大 VLog 大小 std::size_t maxSize_; // GC 计数器 std::size_t deadkeyCount; public: // 构造函数,默认赋值 GC 计数器为 GC 触发的最大阈值 VLog(bool activate, std::size_t maxSize, std::size_t gcThreshold) : activate_(activate), maxSize_(maxSize), deadkeyCount(gcThreshold) {} // 向 VLog 中添加一个新的键值对 virtual void append(const std::string& key, const std::string& value) = 0; // 查找给定键对应的值 virtual VPtr lookup(const std::string& key) const = 0; // 执行垃圾回收操作 virtual void GarbageCollection() = 0; virtual ~VLog() {} };
功能测试
单元测试(测试用例)
- 字段功能:
- (测试是否能序列化
FieldArray、反序列化解析 value ;) - 测试是否能成功写入、点查与范围查询;
- 测试是否能通过 value 查询所有匹配的 Key。
- (测试是否能序列化
- KV 分离:
- 测试大小 value 与对应 key 是否按规则存入 LSM-Tree 或 VLog;
- 测试是否能通过 key 与
VPtr找到 VLog 中正确的 value; - 测试 GC 流程是否正确,包括是否成功触发、重写 VLog、回写 LSM-Tree 的 key 对应的
VPtr。
性能测试(Benchmark)
- 测试不同 value 大小的 Throughput;
- 测试读写放大的减小程度;
- 测试随着插入数据量,LSM-Tree 层级的减小程度;
- 测试随机点查 / 顺序范围查询效率;
- 测试 GC 开销;
- 测试各读写阶段耗时占比(Wait / Log / Memtable / Other);
- 比较大/小数据集、高并发场景的表现;
- (比较资源利用率(硬盘 I/O 、内存负载);)
可能遇到的挑战与解决方案
- KV 分离中 VLog 的 GC 开销可能较大:GC 过程中需要扫描和重写 vLog,以及回写 LSM-Tree,需要遍历所有 SSTable,开销较大;
- 数据一致性问题:若程序突然停止运行,可能导致数据不一致的情况,目前暂时没想到恢复机制;
- 读、写、GC 等流程的持锁处理;
- 由于每次读取需要遍历整个 LSM-Tree 且由于 vLog 是 Append-Only 的无序存储,导致顺序读取的效率可能不比随机读取高多少,开销大,需要实现 value 预读机制,提前预读取下一个 value。
分工和进度安排
| 功能 | 预计完成日期 | 分工 |
|---|---|---|
| Fields 类和相关接口实现 | 12月3日 | 朱维清、谷杰 |
| 测试实现字段功能 | 12月5日 | 谷杰 |
| VLog 类和相关接口实现 | 12月15日 | 朱维清、谷杰 |
| 测试实现 KV 分离 | 12月19日 | 朱维清 |
| Benchmark 测试(吞吐量、写放大、点查范围查) | 12月26日 | 谷杰 |
| Benchmark 测试(GC 开销、大小数据集、并发) | 12月26日 | 朱维清 |