
 augurier
f6580e17c2
augurier
f6580e17c2
|
10 달 전 | ||
|---|---|---|---|
| .github/workflows | 删除 | 2 년 전 | |
| benchmarks | 删除 | 2 년 전 | |
| cmake | 删除 | 5 년 전 | |
| db | 删除 | 10 달 전 | |
| doc | 删除 | 3 년 전 | |
| helpers/memenv | 删除 | 3 년 전 | |
| include/leveldb | 删除 | 10 달 전 | |
| issues | 删除 | 3 년 전 | |
| pics | 删除 | 10 달 전 | |
| port | 删除 | 10 달 전 | |
| table | 删除 | 10 달 전 | |
| test | 删除 | 10 달 전 | |
| third_party | 删除 | 2 년 전 | |
| util | 删除 | 2 년 전 | |
| .clang-format | 6 년 전 | ||
| .gitignore | 10 달 전 | ||
| .gitmodules | 4 년 전 | ||
| AUTHORS | 12 년 전 | ||
| CMakeLists.txt | 10 달 전 | ||
| CONTRIBUTING.md | 3 년 전 | ||
| LICENSE | 14 년 전 | ||
| NEWS | 14 년 전 | ||
| README.md | 10 달 전 | ||
| TODO | 13 년 전 | ||
README.md
实验报告
1. 设计思路和实现过程
1.1 实验总体流程介绍
实验总体上分为了两个阶段。第一个阶段修改了key的编码,增加了ttl信息,并只修改memtable中的逻辑,分割简化任务,保证编码、写入与读memtable逻辑的正确性。这可以通过插入少量数据,不触发大小合并进行阶段性测试。
第二个阶段进一步修改sstable中读取与合并的逻辑,并通过最终的测试样例。
1.2 编码
考虑到leveldb中key本身附带有额外的信息(seq和type),我们选择将ttl的信息一并存入key中,也便于读写合并过程中直接对key进行逻辑判断,不涉及获取value的额外操作。编码修改如下:
internal key中末尾的tag,原本是56位的seq加8位的type,但实际type只需要最后一位表示是否是delete,其余7位为0。为节省空间,我们用倒数第二位表示该键是否有ttl,如果有,则在tag前增加一个64位的时间戳deadTime,表示过期时间。(deadTime并不是一定有,要先依靠存储在固定位置的标识确定,所以放在tag前而非后)
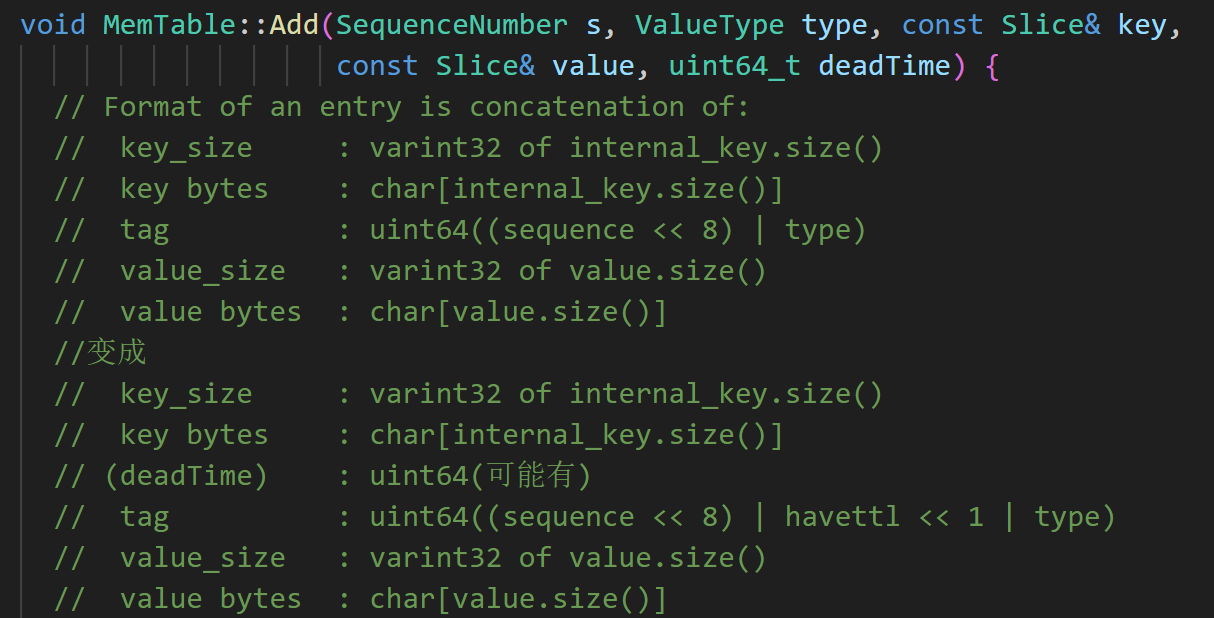 lookup key一定需要一个当前时间在查询中进行比较,因此不再设置标识位,仅在tag前加64位的nowTime。
lookup key一定需要一个当前时间在查询中进行比较,因此不再设置标识位,仅在tag前加64位的nowTime。

1.3 写入
新的put接口多了一个默认参数ttl,当调用时不加这个参数,则这一次写入没有ttl,与原来的leveldb写入逻辑一致。否则需要进行两处的修改:
一是writebatch中信息的记录,这里同样进行编码的修改,8位havettl接可能有的64位deadtime(当前时间+传入的ttl),以及WriteBatch::Iterate中相应的信息解码。
 二是memtable::Add中对于key新的编码。
二是memtable::Add中对于key新的编码。
1.4 读取
读取分为memtable和sstable两部分,在构建lookupkey时记录了当前时间。
memtable中,迭代器找到原本的位置(即同userkey,seq为查询前最大的那个),这时有了ttl需要新的判断:是否超时。超时的话迭代器继续后移,直到userkey不同了说明没找到,或是找到了没过期的数据。这样就能得到没过期的数据中,seq最大的那条。
...
2. 测试用例和结果
2.1 测试用例
除了原本提供的测试用例,新增:
GetEarlierData:该样例插入两次key相同但value不同的数据,后一次的ttl短于前一次。在后插入的数据过期,而前插入的未过期时,查询应得到前一次插入的value。
2.2 结果
3. 问题和解决方案
总结几个实验过程中遇到的大bug和设计问题:
- 查询判断过期数据的逻辑最初放在了internal key比较器内部,但后来发现memtable、sstable、compact等多处比较的逻辑都有不同,一起调用比较器,内部实现逻辑过于复杂,最终修改为处理外部调用的迭代器。
- 查询最后插入的那条数据,此时比较器中seq是相等的,按照原本的leveldb,tag也是相等的,但是由于编码修改加入了havettl位,原本代码仅比较了tag,大小出现了问题。由于仅有这一条数据会出问题,没有意识到seq会相等而新增位影响了比较,调试了许久。修改非常简单:单独拿出tag中的seq比较。