
 gyfffffff
4aceaa739f
gyfffffff
4aceaa739f
|
10 miesięcy temu | ||
|---|---|---|---|
| .github/workflows | 删除 | 2 lat temu | |
| benchmarks | 删除 | 2 lat temu | |
| cmake | 删除 | 5 lat temu | |
| db | 删除 | 10 miesięcy temu | |
| doc | 删除 | 3 lat temu | |
| helpers/memenv | 删除 | 3 lat temu | |
| include/leveldb | 删除 | 10 miesięcy temu | |
| issues | 删除 | 3 lat temu | |
| pics | 删除 | 10 miesięcy temu | |
| port | 删除 | 10 miesięcy temu | |
| table | 删除 | 10 miesięcy temu | |
| test | 删除 | 10 miesięcy temu | |
| third_party | 删除 | 2 lat temu | |
| util | 删除 | 2 lat temu | |
| .clang-format | 6 lat temu | ||
| .gitignore | 10 miesięcy temu | ||
| .gitmodules | 4 lat temu | ||
| AUTHORS | 12 lat temu | ||
| CMakeLists.txt | 10 miesięcy temu | ||
| CONTRIBUTING.md | 3 lat temu | ||
| LICENSE | 14 lat temu | ||
| NEWS | 14 lat temu | ||
| README.md | 10 miesięcy temu | ||
| TODO | 13 lat temu | ||
README.md
实验报告
1. 设计思路和实现过程
1.1 实验总体流程介绍
实验总体上分为了两个阶段。第一个阶段修改了key的编码,增加了ttl信息,并只修改memtable中的逻辑,分割简化任务,保证编码、写入与读memtable逻辑的正确性。这可以通过插入少量数据,不触发大小合并进行阶段性测试。 第二个阶段进一步修改sstable中读取与合并的逻辑,并通过最终的测试样例。
1.2 编码
考虑到leveldb中key本身附带有额外的信息(seq和type),我们选择将ttl的信息一并存入key中,也便于读写合并过程中直接对key进行逻辑判断,不涉及获取value的额外操作。编码修改如下:
internal key中末尾的tag,原本是56位的seq加8位的type,但实际type只需要最后一位表示是否是delete,其余7位为0。为节省空间,我们用倒数第二位表示该键是否有ttl,如果有,则在tag前增加一个64位的时间戳deadTime,表示过期时间。(deadTime并不是一定有,要先依靠存储在固定位置的标识确定,所以放在tag前而非后)
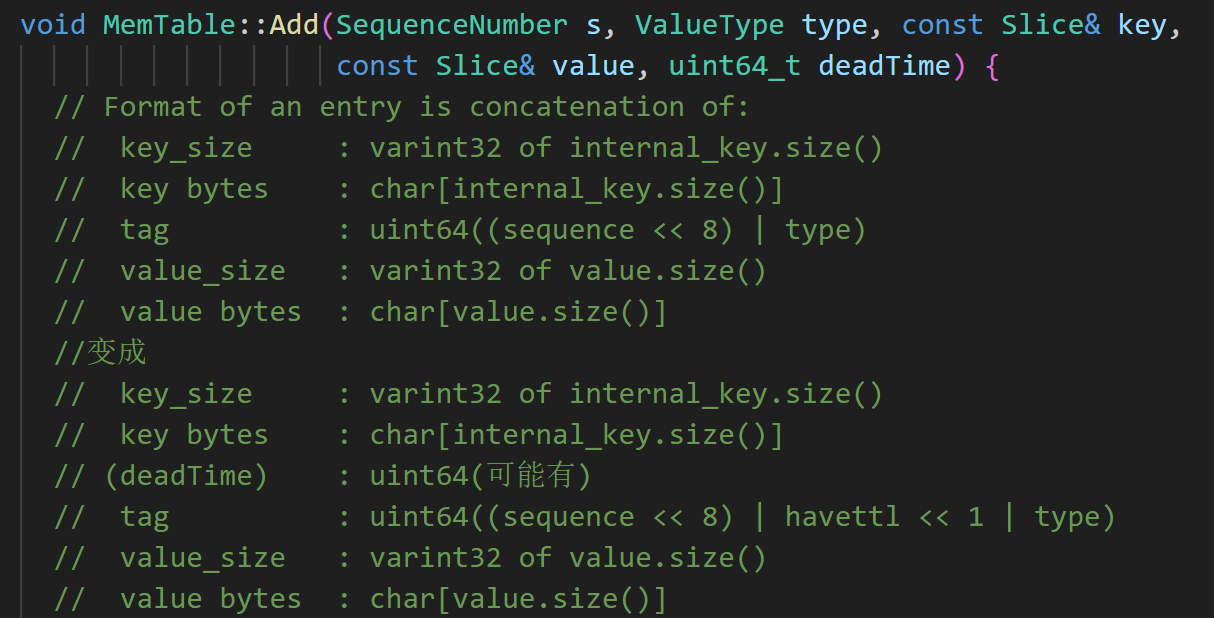 lookup key一定需要一个当前时间在查询中进行比较,因此不再设置标识位,仅在tag前加64位的nowTime。
lookup key一定需要一个当前时间在查询中进行比较,因此不再设置标识位,仅在tag前加64位的nowTime。
 为了便于对于新编码的操作,我们也修改了相应的
为了便于对于新编码的操作,我们也修改了相应的ParsedInternalKey结构体和parseInternalKey函数等。
//这里或许可以多贴一点代码
1.3 写入
新的put接口多了一个默认参数ttl,当调用时不加这个参数,则这一次写入没有ttl,与原来的leveldb写入逻辑一致。否则需要进行两处的修改:
一是writebatch中信息的记录,这里同样进行编码的修改,8位havettl接可能有的64位deadtime(当前时间+传入的ttl),以及WriteBatch::Iterate中相应的信息解码。
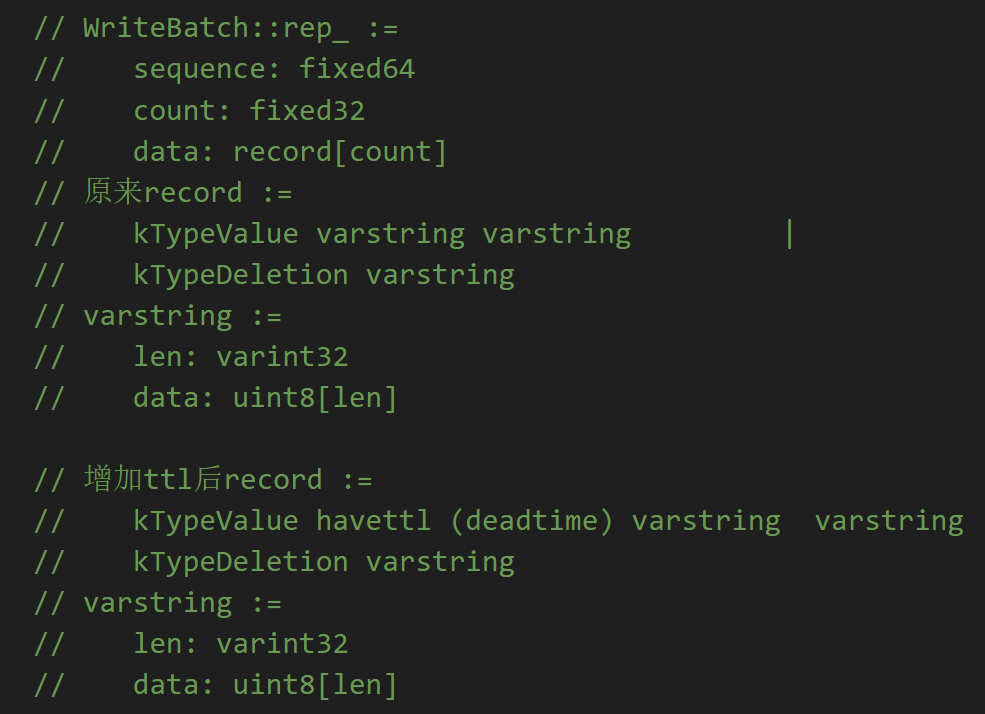 二是memtable::Add中对于key新的编码。
二是memtable::Add中对于key新的编码。
1.4 读取
在构建lookupkey时记录了当前时间,读取过程需要根据这个时间返回未过期的序列号最大的值。读取分为memtable和sstable两部分,下面将对两部分分别进行阐述。
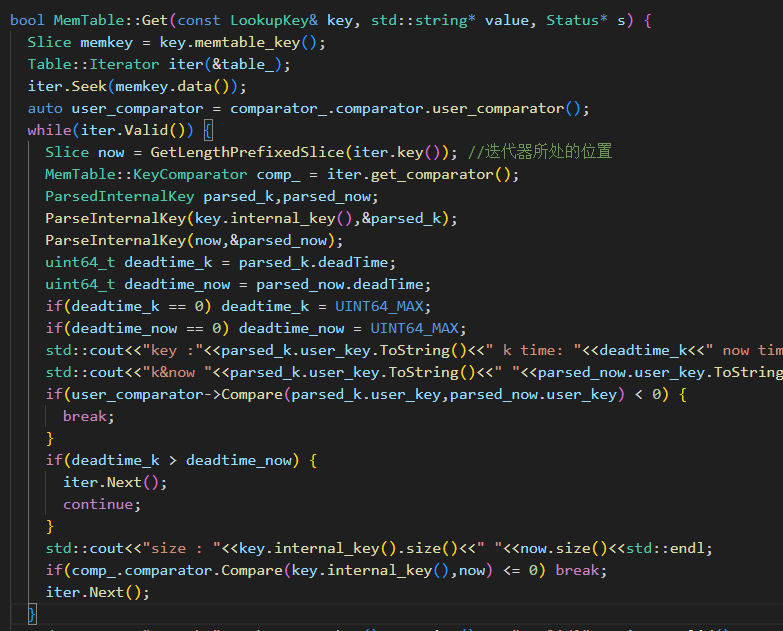
Memtable的读取操作
memtable中,迭代器找到原本的位置(即同userkey,seq为查询前最大的那个),这时有了ttl需要新的判断:是否超时。超时的话迭代器继续后移,直到userkey不同了说明没找到,或是找到了没过期的数据。这样就能得到没过期的数据中,seq最大的那条。 核心代码如下:
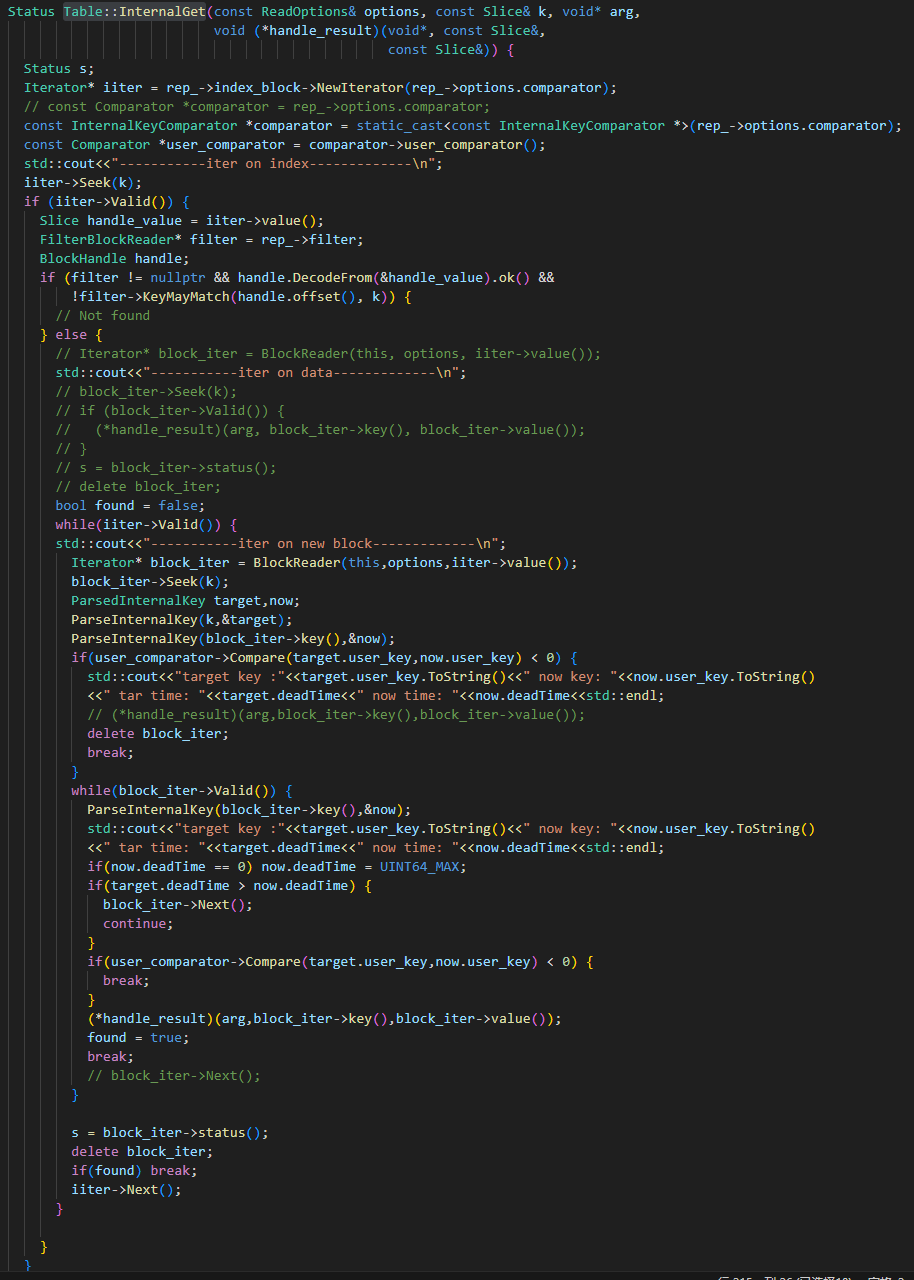
SSTable的读取操作
SSTable的读取流程虽然涉及到了level、SSTable、indexblock、datablock多个层级,但是整体思路并没有发生改变,仍然是使用迭代器原来的seek方法找到这一系列数据的"基准位置",然后根据TTL,不断的向后找,直到userkey不同为止。
具体的流程在Table::InternalGet中实现。由于这个函数使用了indexblock和datablock两层迭代器,所以这里嵌套了两层循环。
具体代码如下:
1.5 合并
合并包含小合并和大合并。此处也将分开进行阐述
小合并
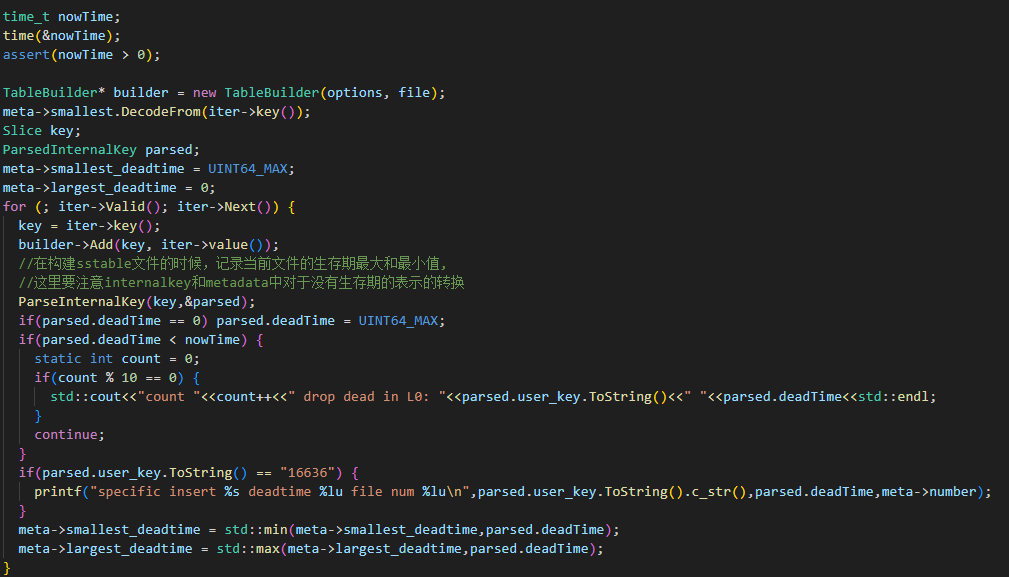
实际产生小合并结果文件(L0)的地方是BuildTable函数,因此我们加入kv对的循环中增加对于TTL的判断来实现小合并中的过期数据删除。
具体代码如下:(其中包括了部分后面会提到的代码逻辑)
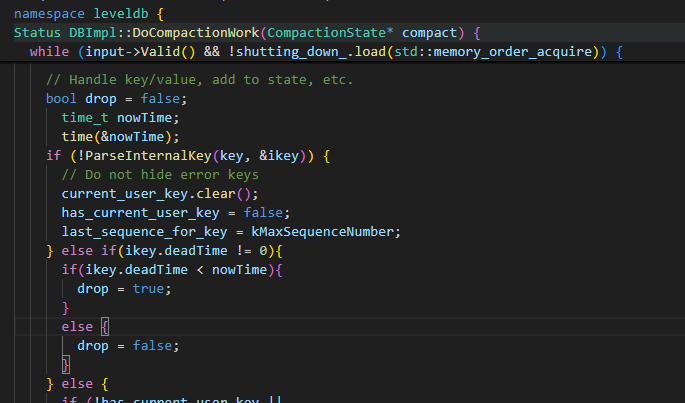
大合并
大合并实际产生结果文件的地方是DoCompactionWork函数。和小合并类似,如果存在一个过期的数据,那么直接drop这个数据,但是只要这个数据没有过期且存在TTL,那么这个数据就不能drop。如果只是忽略过期数据的话,那么可能会出现多个未过期的相同key的数据进行合并,按照leveldb原来的逻辑,此时只有seq最大的数据会被保留,其他的数据都会被丢弃。这在原本的leveldb中并没有问题,但是如果附带了TTL,那么我们就不能够保证数据严格的排序关系,有可能seq最大的数据的TTL反而很短,会先于TTL较长但是seq较小的数据前失效,那么如果将seq较小的数据合并的话,会产生数据的丢失。
当然,有可能会出现首先是一个不包含TTL(TTL无限长)的delete记录或者Value记录,然后是一串带有或者不带有TTL的数据,此时我们也可以将这些数据删除。不过处于简便考虑,我们保留所有带有TTL且没有过期的数据,因为这至少在逻辑上是对的,虽然可能会产生一些空间浪费。
具体代码如下:
小结
至此,ttl功能得到实现。对于手动合并过程中合并不完全的情况,采用的是强制对每一层进行合并的方式。至此,所有的测试都能够通过
3. 扩展特性和未来展望
3.1 文件元数据更新
我们对于文件元数据内容进行了修改,来帮助我们更好的进行相关操作。我们增加了smallest_deadtime和largest_deadtime字段,用来表示某个SSTable中所有数据的生存期的范围。修改如下:
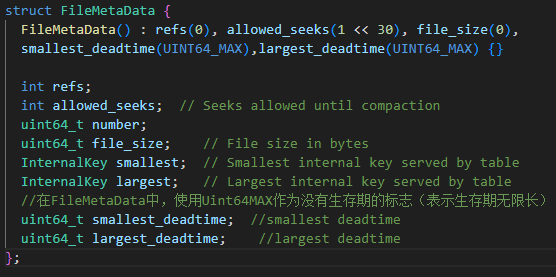 为了支持文件元数据的写入和读取,我们更改了
为了支持文件元数据的写入和读取,我们更改了AddFile、EncodeTo、DecodeFrom等相关函数,并在所有调用处也进行了相应的修改。
在leveldb中,只有在小合并和大合并的过程中才会产生新的文件,所以只要在这两个流程中进行代码的添加,就能够完成新增文件元数据的获取。
小合并中的代码逻辑在上一章有关小合并的部分已经展示。在大合并中,由于首先生成的是out结构体,在合并结束时候才将out结构体转换为Filemetadata,所以我们对于out结构体也进行了修改。out结构体和大合并获取新增元数据的逻辑如下:
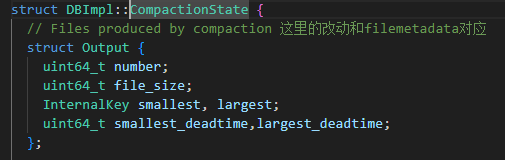
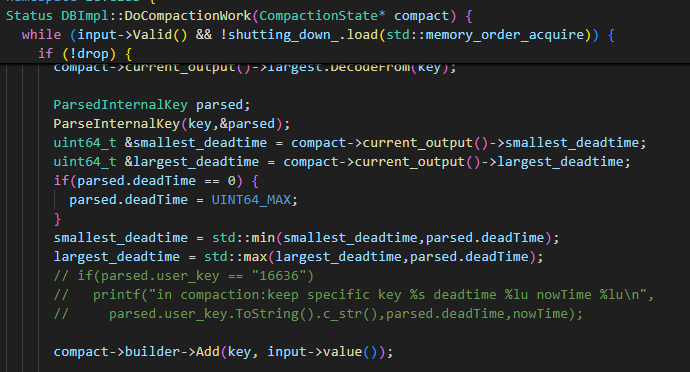
3.2 用于合并流程
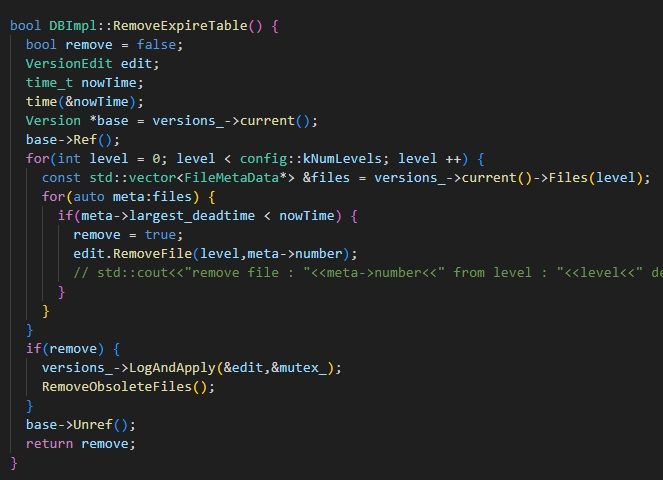
有了文件所含数据的生存期的范围,我们就可以很容易的判断一个文件是否存在有效的数据,如果一个文件的所有数据全部无效,那么我们只要在合并过程中删除整个文件就行。
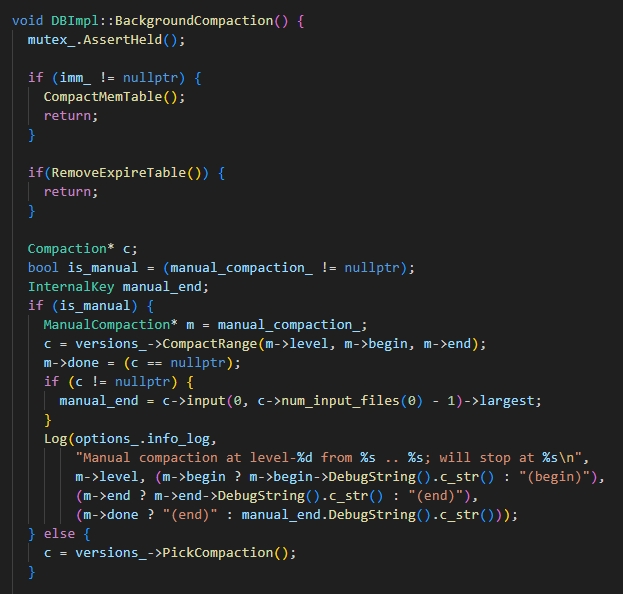
由于所有的文件元数据全部都保存在内存中,我们可以高效的去遍历所有元数据筛选出所有数据全都无效的文件并进行删除。在原版大合并流程之前进行这样的删除操作,可以减少大合并过程中的开销。原版的流程中需要遍历文件中所有的数据才能完成合并,但是现在只需要判断元数据信息即可。同时也增加了大合并的效果完成之后的大合并可以选择额外的输入文件进行合并。此外,通过扫描所有的文件元数据,可以在不更改手动合并流程去强制合并每一个level的情况下就能够通过原先的test。
由于大合并的入口函数是可以递归调用的,所以完成文件删除后可以直接返回,在递归调用中可以启动原版的大合并。
代码逻辑如下:
3.3 用于加快get访问
上文提到,读取的时候会按照level、文件、indexblock、datablock这样的顺序进行读取操作。因此,我们利用文件的新增元数据信息,可以跳过那些所含数据全部失效的文件,加快数据的搜索速度。
2. 测试用例和结果
2.1 测试用例
除了原本提供的测试用例,新增:
- GetEarlierData:该样例插入两次key相同但value不同的数据,后一次的ttl短于前一次。在后插入的数据过期,而前插入的未过期时,查询应得到前一次插入的value。
- ReadWithoutTTL: 该样例插入两次key相同但value不同的数据,前一次没有ttl,而后一次插入附带ttl。在后插入的数据过期时,查询应得到前一次插入的value。
2.2 结果
3. 问题和解决方案
总结几个实验过程中遇到的大bug和设计问题:
- 查询判断过期数据的逻辑最初放在了internal key比较器内部,但后来发现memtable、sstable、compact等多处比较的逻辑都有不同,一起调用比较器,内部实现逻辑过于复杂,并且在数据查询的过程中会有许多二分查找的过程,由于ttl的存在,单独修改比较器无法保证数据的偏序关系,并不适配二分查找的实现。最终修改为处理外部调用的迭代器。
- 一开始对于SSTable的读取实现中,我们是在seek内部进行修改的,但是出了很多问题,调试了很久后发现,这是由于indexblock和datablock是公用一种迭代器导致的。由于indexblock是datablock的“缩略信息”,所以会存在indexblock中所存的值表示该条目所对应datablock全部过期了,所以在查找的时候会直接跳过这个datablock,但是实际上这个datablock中存在着deadtime更久的记录。这本质上还是由于ttl的存在导致无法保证偏序关系。因此,我们放弃了直接修改迭代器内部实现的方式,改为在外部调用迭代器。
- 查询最后插入的那条数据,此时比较器中seq是相等的,按照原本的leveldb,tag也是相等的,但是由于编码修改加入了havettl位,原本代码仅比较了tag,大小出现了问题。由于仅有这一条数据会出问题,没有意识到seq会相等而新增位影响了比较,调试了许久。修改非常简单:单独拿出tag中的seq比较。