|
|
|
@ -6,11 +6,12 @@ leveldb中的存储原本只支持简单的字节序列,在这个项目中我 |
|
|
|
|
|
|
|
# 2. 功能实现 |
|
|
|
## 2.1 字段 |
|
|
|
设计目标:对value存储读取时进行序列化编码,使其支持字段。 |
|
|
|
设计目标:对value存储读取时进行序列化编码,使其支持字段。 |
|
|
|
这一部分的具体代码在util/serialize_value.cc中 |
|
|
|
|
|
|
|
实现思路:设计之初有考虑增加一些元数据(例如过滤器、字段偏移支持二分)来加速查询。但考虑到在数据库中kv的数量是十分庞大的,新加数据结构会带来巨大的空间开销。因此我们决定在这里牺牲时间换取空间,而将时间的加速放在索引中。 |
|
|
|
在这一基础上,我们对序列化进行了简单的优化:将字段名排序后,一一调用leveldb中原本的编码方法`PutLengthPrefixedSlice`存入value。这样不会有额外的空间开销,而好处在于遍历一个value的字段时,如果得到的字段名比目标大,就可以提前结束遍历。 |
|
|
|
``` |
|
|
|
```c++ |
|
|
|
std::string SerializeValue(const FieldArray& fields){ |
|
|
|
std::sort(sortFields.begin(), sortFields.end(), compareByFirst); |
|
|
|
for (const Field& pairs : sortFields) { |
|
|
|
@ -22,13 +23,237 @@ std::string SerializeValue(const FieldArray& fields){ |
|
|
|
``` |
|
|
|
最终db类提供了新接口`putFields`, `getFields`,分别对传入的字段序列化后调用原来的`put`, `get`接口。 |
|
|
|
`FindKeysByField`调用`NewIterator`遍历所有数据,field名和值符合则加入返回的key中。 |
|
|
|
**这一部分的具体代码在util/serialize_value.cc中** |
|
|
|
|
|
|
|
|
|
|
|
## 2.2 二级索引 |
|
|
|
设计目标:对某个字段(属性)建立索引,提高对该字段的查询效率。 |
|
|
|
这一部分的具体代码在field/下 |
|
|
|
|
|
|
|
### 2.2.1 总体架构 |
|
|
|
fielddb |
|
|
|
1. **二级索引的设计** |
|
|
|
|
|
|
|
二级索引的难点主要包括以下几点:索引数据与kv数据的存储需要进行隔离,不同操作之间存在同步与异步问题,每一次的写入操作都需要额外考虑数据库原本的索引情况,任何操作还需要考虑两种数据间的一致性。为了使设计简洁化,避免不同模块耦合带来潜在的问题,我们的设计如下: |
|
|
|
|
|
|
|
总体上,我们对两种数据分别创建一个db类的对象kvDb, indexDb。对外的接口类FieldDb包含了这两个对象,提供原先的leveldb各种接口,以及新功能,并在这一层完成两个对象的管理。这两个子数据库共同协作,完成了二级索引的各核心操作。在此基础上,为了保证数据库崩溃时两个子数据库的一致性,我们设计了第三个子数据库metadb,它的作用类似于日志。 |
|
|
|
```c++ |
|
|
|
class FieldDB : DB { |
|
|
|
public: |
|
|
|
FieldDB() : indexDB_(nullptr), kvDB_(nullptr), metaDB_(nullptr) {}; |
|
|
|
~FieldDB(); |
|
|
|
/*lab1的要求,以及作为db派生类要实现的虚函数*/ |
|
|
|
Status Put(const WriteOptions &options, const Slice &key, const Slice &value) override; |
|
|
|
Status PutFields(const WriteOptions &, const Slice &key, const FieldArray &fields) override; |
|
|
|
Status Delete(const WriteOptions &options, const Slice &key) override; |
|
|
|
Status Write(const WriteOptions &options, WriteBatch *updates) override; |
|
|
|
Status Get(const ReadOptions &options, const Slice &key, std::string *value) override; |
|
|
|
Status GetFields(const ReadOptions &options, const Slice &key, FieldArray *fields) override; |
|
|
|
std::vector<std::string> FindKeysByField(Field &field) override; |
|
|
|
Iterator * NewIterator(const ReadOptions &options) override; |
|
|
|
const Snapshot * GetSnapshot() override; |
|
|
|
void ReleaseSnapshot(const Snapshot *snapshot) override; |
|
|
|
bool GetProperty(const Slice &property, std::string *value) override; |
|
|
|
void GetApproximateSizes(const Range *range, int n, uint64_t *sizes) override; |
|
|
|
void CompactRange(const Slice *begin, const Slice *end) override; |
|
|
|
/*与索引相关*/ |
|
|
|
Status CreateIndexOnField(const std::string& field_name, const WriteOptions &op); |
|
|
|
Status DeleteIndex(const std::string &field_name, const WriteOptions &op); |
|
|
|
std::vector<std::string> QueryByIndex(const Field &field, Status *s); |
|
|
|
IndexStatus GetIndexStatus(const std::string &fieldName); |
|
|
|
|
|
|
|
static Status OpenFieldDB(Options& options,const std::string& name,FieldDB** dbptr); |
|
|
|
|
|
|
|
private: |
|
|
|
//根据metaDB的内容进行恢复 |
|
|
|
Status Recover(); |
|
|
|
|
|
|
|
private: |
|
|
|
leveldb::DB *kvDB_; |
|
|
|
leveldb::DB *metaDB_; |
|
|
|
leveldb::DB *indexDB_; |
|
|
|
|
|
|
|
std::string dbname_; |
|
|
|
const Options *options_; |
|
|
|
Env *env_; |
|
|
|
} |
|
|
|
``` |
|
|
|
这样的设计带来了如下的好处: |
|
|
|
kv和index实现了完全的分离,并且由于各自都使用了leveldb构建的lsmtree,完全保证了内部实现的正确性。相应的,我们的工作基本只处在fielddb层,减少了模块的耦合,对于我们自己实现的正确性也有极大的提升。 |
|
|
|
|
|
|
|
所有leveldb原本的功能仍然能够支持,并且有些实现起来十分简单,比如: |
|
|
|
```c++ |
|
|
|
Iterator * FieldDB::NewIterator(const ReadOptions &options) { |
|
|
|
return kvDB_->NewIterator(options); |
|
|
|
} |
|
|
|
|
|
|
|
Status FieldDB::GetFields(const ReadOptions &options, const Slice &key, FieldArray *fields) { |
|
|
|
return kvDB_->GetFields(options, key, fields); |
|
|
|
} |
|
|
|
``` |
|
|
|
|
|
|
|
此外,性能开销增加也只在fielddb层,使我们能够进行比较和优化。 |
|
|
|
|
|
|
|
2. **index的编码** |
|
|
|
index编码仍然采用了leveldb提供`PutLengthPrefixedSlice`,保留信息的同时,提高空间利用率。 |
|
|
|
对于一个`key : {name : val}`的字段,索引采用如下编码: |
|
|
|
```c++ |
|
|
|
inline void AppendIndexKey(std::string* result, const ParsedInternalIndexKey& key){ |
|
|
|
PutLengthPrefixedSlice(result, key.name_); |
|
|
|
PutLengthPrefixedSlice(result, key.val_); |
|
|
|
PutLengthPrefixedSlice(result, key.user_key_); |
|
|
|
``` |
|
|
|
这一部分也被模块化的封装在field/encode_index.h中。 |
|
|
|
|
|
|
|
由此产生了索引读的方法:根据name和val构建一个新的iterator,迭代获取范围内的所有key: |
|
|
|
```c++ |
|
|
|
std::vector<std::string> FieldDB::QueryByIndex(const Field &field, Status *s) { |
|
|
|
if (index_.count(field.first) == 0 || index_[field.first].first != Exist){ |
|
|
|
*s = Status::NotFound(Slice()); |
|
|
|
return std::vector<std::string>(); |
|
|
|
} |
|
|
|
std::string indexKey; |
|
|
|
AppendIndexKey(&indexKey, |
|
|
|
ParsedInternalIndexKey(Slice(), field.first, field.second)); |
|
|
|
Iterator *indexIterator = indexDB_->NewIterator(ReadOptions()); |
|
|
|
indexIterator->Seek(indexKey); |
|
|
|
|
|
|
|
std::vector<std::string> result; |
|
|
|
for (; indexIterator->Valid(); indexIterator->Next()) { |
|
|
|
ParsedInternalIndexKey iterKey; |
|
|
|
if (ParseInternalIndexKey(indexIterator->key(), &iterKey)){ |
|
|
|
if (iterKey.name_ == field.first && iterKey.val_ == field.second){ |
|
|
|
result.push_back(iterKey.user_key_.ToString()); |
|
|
|
continue; //查到说明在范围里,否则break |
|
|
|
} |
|
|
|
} |
|
|
|
break; |
|
|
|
} |
|
|
|
delete indexIterator; |
|
|
|
*s = Status::OK(); |
|
|
|
return result; |
|
|
|
} |
|
|
|
``` |
|
|
|
|
|
|
|
3. **新的写流程** |
|
|
|
索引功能的出现,使得写的逻辑需要重新设计。因为每一次写,不仅需要关注本次写入的字段,是不是需要同时写入索引,还需要关注本次写入的key,是不是覆盖了数据库原本的key,导致需要修改原本key的索引情况。这也意味着,即使是put简单的kv(不带字段),实际上还是需要修改put逻辑。方便起见,我们为原本的put中的value加入一个""的字段名,也视为putfield(这只是为了使我们的数据库支持原本的所有功能,也并不是本项目的重点,完全可以索性删除put功能,让我们的数据库只支持字段value)。 |
|
|
|
|
|
|
|
下面是putfield的实现思路: |
|
|
|
```c++ |
|
|
|
void FieldsReq::ConstructBatch(WriteBatch &KVBatch,WriteBatch &IndexBatch, |
|
|
|
WriteBatch &MetaBatch,fielddb::FieldDB *DB, |
|
|
|
SliceHashSet &batchKeySet) |
|
|
|
{ |
|
|
|
if (batchKeySet.find(Key) != batchKeySet.end()){ |
|
|
|
return;//并发的被合并的put/delete请求只处理一次 |
|
|
|
} else { |
|
|
|
batchKeySet.insert(Key); |
|
|
|
} |
|
|
|
std::string val_str; |
|
|
|
s = DB->kvDB_->Get(ReadOptions(), Key, &val_str); |
|
|
|
FieldSliceArray oldFields; |
|
|
|
if (s.IsNotFound()){ |
|
|
|
// oldFields = nullptr; |
|
|
|
} else if (s.ok()) { //得到数据库之前key的fields, 判断需不需要删除其中潜在的索引 |
|
|
|
Slice nameSlice, valSlice; |
|
|
|
Slice Value(val_str); |
|
|
|
while(GetLengthPrefixedSlice(&Value, &nameSlice)) { |
|
|
|
if(GetLengthPrefixedSlice(&Value, &valSlice)) { |
|
|
|
oldFields.push_back({nameSlice,valSlice}); |
|
|
|
} else { |
|
|
|
std::cout << "name and val not match! From FieldsReq Init" << std::endl; |
|
|
|
assert(0); |
|
|
|
} |
|
|
|
nameSlice.clear(), valSlice.clear(); |
|
|
|
} |
|
|
|
} else { |
|
|
|
assert(0); |
|
|
|
} |
|
|
|
|
|
|
|
bool HasIndex = false; |
|
|
|
bool HasOldIndex = false; |
|
|
|
{ |
|
|
|
DB->index_mu.AssertHeld(); |
|
|
|
//1.将存在冲突的put pend到对应的请求 |
|
|
|
for(auto &[field_name,field_value] : SliceFields) { |
|
|
|
if(field_name.data() == EMPTY) break; |
|
|
|
if(DB->index_.count(field_name.ToString())) { |
|
|
|
auto [index_status,parent_req] = DB->index_[field_name.ToString()]; |
|
|
|
if(index_status == IndexStatus::Creating || index_status == IndexStatus::Deleting) { |
|
|
|
parent_req->PendReq(this->parent); |
|
|
|
return; |
|
|
|
} else if(index_status == IndexStatus::Exist) { |
|
|
|
HasIndex = true; |
|
|
|
} |
|
|
|
} |
|
|
|
} |
|
|
|
//冲突也可能存在于,需要删除旧数据的索引,但该索引正在创删中 |
|
|
|
if (!oldFields.empty()){ |
|
|
|
for(auto &[field_name,field_value] : oldFields) { |
|
|
|
if(field_name.data() == EMPTY) break; |
|
|
|
if(DB->index_.count(field_name.ToString())) { |
|
|
|
auto [index_status,parent_req] = DB->index_[field_name.ToString()]; |
|
|
|
if(index_status == IndexStatus::Creating || index_status == IndexStatus::Deleting) { |
|
|
|
parent_req->PendReq(this->parent); |
|
|
|
return; |
|
|
|
} else if(index_status == IndexStatus::Exist) { |
|
|
|
HasOldIndex = true; |
|
|
|
} |
|
|
|
} |
|
|
|
} |
|
|
|
} |
|
|
|
std::string scrach = SerializeValue(SliceFields); |
|
|
|
KVBatch.Put(Slice(Key), Slice(scrach)); |
|
|
|
//2.对于没有冲突但含有索引操作的put,构建metaKV |
|
|
|
if(HasIndex || HasOldIndex) { |
|
|
|
std::string MetaKey,MetaValue; |
|
|
|
std::string serialized = SerializeValue(SliceFields); |
|
|
|
MetaKV MKV = MetaKV(Key,serialized); |
|
|
|
MKV.TransPut(MetaKey, MetaValue); |
|
|
|
MetaBatch.Put(MetaKey, serialized); |
|
|
|
|
|
|
|
|
|
|
|
//3.1对于含有索引的oldfield删除索引 |
|
|
|
if (HasOldIndex) { |
|
|
|
for(auto &[field_name,field_value] : oldFields) { |
|
|
|
if(field_name.data() == EMPTY) continue; |
|
|
|
if(DB->index_.count(field_name.ToString()) && //旧数据有,新数据没有的字段,删索引 |
|
|
|
std::find(SliceFields.begin(), SliceFields.end(), |
|
|
|
std::make_pair(field_name, field_value)) == SliceFields.end()) { |
|
|
|
std::string indexKey; |
|
|
|
AppendIndexKey(&indexKey, ParsedInternalIndexKey( |
|
|
|
Key,field_name,field_value)); |
|
|
|
IndexBatch.Delete(indexKey); |
|
|
|
} |
|
|
|
} |
|
|
|
} |
|
|
|
|
|
|
|
//3.2对于含有索引的field建立索引 |
|
|
|
if (HasIndex) { |
|
|
|
for(auto &[field_name,field_value] : SliceFields) { |
|
|
|
if(field_name.data() == EMPTY) continue; |
|
|
|
if(DB->index_.count(field_name.ToString())) { |
|
|
|
std::string indexKey; |
|
|
|
AppendIndexKey(&indexKey, ParsedInternalIndexKey( |
|
|
|
Key,field_name,field_value)); |
|
|
|
IndexBatch.Put(indexKey, Slice()); |
|
|
|
} |
|
|
|
} |
|
|
|
} |
|
|
|
|
|
|
|
} |
|
|
|
} |
|
|
|
} |
|
|
|
``` |
|
|
|
|
|
|
|
同理,delete也需要先读最新的数据,再进行相应的处理,这里简单贴上实现逻辑: |
|
|
|
``` |
|
|
|
//1. 读取当前的最新的键值对,判断是否存在含有键值对的field |
|
|
|
//2.1 如果无,则正常构造delete |
|
|
|
//2.2 如果是有的field的索引状态都是exist,则在meta中写KV_Deleting类型的记录 |
|
|
|
//在kvDB和indexDB中写入对应的delete |
|
|
|
//2.3 如果存在field的索引状态是Creating或者Deleting,那么在那个队列上面进行等待 |
|
|
|
``` |
|
|
|
|
|
|
|
上面的代码也展现了并发与恢复的部分,接下来会一一阐述。 |
|
|
|
|
|
|
|
### 2.2.2 如何并发创删索引与读写 |
|
|
|
1. **为什么要并发控制创删索引与读写** |
|
|
|
@ -238,8 +463,106 @@ BatchReq::BatchReq(WriteBatch *Batch,port::Mutex *mu): |
|
|
|
} |
|
|
|
``` |
|
|
|
|
|
|
|
### 2.2.3 如何保证两个kv与index的一致性 |
|
|
|
metadb |
|
|
|
### 2.2.3 如何保证kv与index的一致性 |
|
|
|
metadb为异常恢复服务,只涉及到putfield和delete部分。(这里最初的设计有些问题,当时认为异常恢复也需要考虑创删索引部分,但实际上创删索引的本质,是一次往indexdb的writebatch,只会有索引整体写入成功和不成功两种情况,并不会出现不一致问题。) |
|
|
|
|
|
|
|
因此metadb的编码,只要在原本kv编码的基础上,加一个标志位,标识本条是来自putfield还是delete。 |
|
|
|
metadb提供的功能被封装在fielddb/meta.cc中,包括编码: |
|
|
|
```c++ |
|
|
|
void MetaKV::TransPut(std::string &MetaKey,std::string &MetaValue) { |
|
|
|
MetaKey.clear(); |
|
|
|
MetaValue.clear(); |
|
|
|
std::string &buf = MetaKey; |
|
|
|
PutFixed32(&buf, KV_Creating); |
|
|
|
PutLengthPrefixedSlice(&buf, Slice(name)); |
|
|
|
} |
|
|
|
|
|
|
|
void MetaKV::TransDelete(std::string &MetaKey) { |
|
|
|
MetaKey.clear(); |
|
|
|
std::string &buf = MetaKey; |
|
|
|
PutFixed32(&buf, KV_Deleting); |
|
|
|
PutLengthPrefixedSlice(&buf, Slice(name)); |
|
|
|
} |
|
|
|
``` |
|
|
|
|
|
|
|
以及kv和index写完后的清理(构建一个都是delete的writebatch,向metadb中写入): |
|
|
|
```c++ |
|
|
|
class CleanerHandler : public WriteBatch::Handler { |
|
|
|
public: |
|
|
|
WriteBatch *NeedClean; |
|
|
|
void Put(const Slice& key, const Slice& value) override { |
|
|
|
//将所有之前put的meta数据进行delete |
|
|
|
NeedClean->Delete(key); |
|
|
|
} |
|
|
|
void Delete(const Slice& key) override { |
|
|
|
//所有的传入的MetaBatch都是Put的 |
|
|
|
assert(0); |
|
|
|
} |
|
|
|
}; |
|
|
|
|
|
|
|
void MetaCleaner::Collect(WriteBatch &MetaBatch) { |
|
|
|
if(MetaBatch.ApproximateSize() <= 12) return; |
|
|
|
CleanerHandler Handler; |
|
|
|
Handler.NeedClean = &NeedClean; |
|
|
|
MetaBatch.Iterate(&Handler); |
|
|
|
} |
|
|
|
|
|
|
|
void MetaCleaner::CleanMetaBatch(DB *metaDB) { |
|
|
|
if(NeedClean.ApproximateSize() <= 12) return; |
|
|
|
metaDB->Write(WriteOptions(), &NeedClean); |
|
|
|
} |
|
|
|
``` |
|
|
|
|
|
|
|
相应的,我们数据库的恢复也是建立在三个数据库的协作之上: |
|
|
|
在重新打开三个数据库,依靠各自的日志恢复各自的数据后,完成对索引相关内容的恢复: |
|
|
|
```c++ |
|
|
|
Status FieldDB::Recover() { |
|
|
|
//1. 遍历所有Index类型的meta,重建内存中的index_状态表 |
|
|
|
Iterator *Iter = indexDB_->NewIterator(ReadOptions()); |
|
|
|
std::string IndexKey; |
|
|
|
Iter->SeekToFirst(); |
|
|
|
while(Iter->Valid()) { |
|
|
|
IndexKey = Iter->key().ToString(); |
|
|
|
ParsedInternalIndexKey ParsedIndex; |
|
|
|
ParseInternalIndexKey(Slice(IndexKey),&ParsedIndex); |
|
|
|
index_[ParsedIndex.name_.ToString()] = {Exist,nullptr}; |
|
|
|
|
|
|
|
//构建下一个搜索的对象,在原来的fieldname的基础上加一个最大的ascii字符(不可见字符) |
|
|
|
std::string Seek; |
|
|
|
PutLengthPrefixedSlice(&Seek, ParsedIndex.name_); |
|
|
|
Seek.push_back(0xff); |
|
|
|
Iter->Seek(Slice(Seek)); |
|
|
|
} |
|
|
|
delete Iter; |
|
|
|
//2. 寻找所有KV类型的meta,再次提交一遍请求 |
|
|
|
Iter = metaDB_->NewIterator(ReadOptions()); |
|
|
|
Slice MetaValue; |
|
|
|
Iter->SeekToFirst(); |
|
|
|
while (Iter->Valid()) { |
|
|
|
MetaValue = Iter->key(); |
|
|
|
MetaType type = MetaType(DecodeFixed32(MetaValue.data())); |
|
|
|
MetaValue.remove_prefix(4);//移除头上的metaType的部分 |
|
|
|
Slice extractKey; |
|
|
|
GetLengthPrefixedSlice(&MetaValue, &extractKey); |
|
|
|
if(type == KV_Creating) { |
|
|
|
FieldArray fields; |
|
|
|
ParseValue(Iter->value().ToString(), &fields); |
|
|
|
PutFields(WriteOptions(), extractKey, fields); |
|
|
|
} else if(type == KV_Deleting) { |
|
|
|
Delete(WriteOptions(), extractKey); |
|
|
|
} else { |
|
|
|
assert(0 && "Invalid MetaType"); |
|
|
|
} |
|
|
|
Iter->Next(); |
|
|
|
} |
|
|
|
delete Iter; |
|
|
|
//在所有的请求完成后,会自动把metaDB的内容清空。 |
|
|
|
Iter = metaDB_->NewIterator(ReadOptions()); |
|
|
|
Iter->SeekToFirst(); |
|
|
|
delete Iter; |
|
|
|
return Status::OK(); |
|
|
|
} |
|
|
|
``` |
|
|
|
|
|
|
|
## 3. 测试 |
|
|
|
### 3.1 正确性测试 |
|
|
|
@ -261,7 +584,7 @@ InsertOneField:只插一条特定数据的测试(让key<=0, 和批量写入 |
|
|
|
DeleteOneField:只删一条特定数据的测试,功能与单条插入相似,主要用来测试delete。 |
|
|
|
GetOneField:只读一条特定数据的测试,与上面两条对应。 |
|
|
|
|
|
|
|
对于所有涉及随机性的函数,传参一个随机种子。只要随机种子一致,随机生成的内容就一致,相应的读需要和相应的写、删保持一致。此外测试的数据量也是可以修改的。 |
|
|
|
对于所有涉及随机性的函数,传参一个随机种子。只要随机种子一致,随机生成的内容就一致,相应的读需要和相应的写、删保持一致。此外测试的数据量也是可以修改的。需要注意的是,之前项目使用的srand线程不安全,使用std::mt19937可以保证多线程时随机序列也一致。 |
|
|
|
|
|
|
|
InsertFieldData:批量写入,按照上面提到的测试规则生成kv,并调用putfields。检查返回状态是否ok。同时对于生成的字段,如果是address为shanghai或age为20,统计入相应的set。 |
|
|
|
|
|
|
|
@ -289,7 +612,8 @@ TestLab1流程: 批量写 -> 必须读到 -> findkeysbycity -> 批量删 -> |
|
|
|
|
|
|
|
TestLab2流程:批量写 -> 创索引address,age -> 索引查询address,age -> 删索引address -> 索引查询address(haveindex=false) -> 索引查询age -> 批量删 -> 索引查询age(索引还在能查,但返回的key数量为0) -> write -> 必须读到 -> 索引查询age。 |
|
|
|
|
|
|
|
至此,上面的流程基本覆盖了我们数据库的每个基础功能。 |
|
|
|
至此,上面的流程基本覆盖了我们数据库的每个基础功能。 |
|
|
|
 |
|
|
|
|
|
|
|
#### 3.1.2 并发测试 |
|
|
|
相关代码在`parallel_test.cc`中 |
|
|
|
@ -308,7 +632,8 @@ TestPutDelete:创索引 -> 并发:两线程写0、1种子数据,两线程 |
|
|
|
TestWrite(在之前基础上并发所有,并加入write):创索引address、批量写种子2 -> 并发:线程0创索引age,其他线程忙等至开始创建,线程1批量写种子0,线程2write种子1, 线程3删索引age -> 检测:种子012所有数据都应被读到,一致性, age索引被删除。 |
|
|
|
这里的测试也可以加入delete,或不删索引age检测age的一致性,具体见注释。 |
|
|
|
|
|
|
|
至此,上面的流程基本覆盖了我们数据库的每个基础功能之间的并发。 |
|
|
|
至此,上面的流程基本覆盖了我们数据库的每个基础功能之间的并发。 |
|
|
|
 |
|
|
|
|
|
|
|
#### 3.1.2 恢复测试 |
|
|
|
相关代码在`recover_test.cc`中 |
|
|
|
@ -317,14 +642,286 @@ TestWrite(在之前基础上并发所有,并加入write):创索引addres |
|
|
|
TestNormalRecover:创索引、批量写、此时之前测试都检测过能被读到 -> delete db -> 重新open -> 读数据、索引查(之前写入的数据仍能被读到)。 |
|
|
|
|
|
|
|
TestParalRecover**该测试比较特别,需要运行两次**:创索引 -> 并发:线程0批量写,线程1write,线程2delete,线程3 在单条插入后,deletedb。线程3导致了其他线程错误,测试会终止(模拟数据库崩溃),这会导致各线程在各种奇怪的时间点崩溃。此时注释掉上半部分代码,运行下半部分:单条写入能被读到,并检测一致性。 |
|
|
|
这里我们运行了几十次,前半部分的崩溃报错有多种,但后半部分的运行都是成功的。同时也追踪了恢复的运行过程,确实有数据从metadb中被正确解析。 |
|
|
|
这里我们运行了几十次,前半部分的崩溃报错有多种,但后半部分的运行都是成功的。同时也追踪了恢复的运行过程,确实有数据从metadb中被正确解析。 |
|
|
|
 |
|
|
|
|
|
|
|
### 3.2 性能测试、分析、优化 |
|
|
|
|
|
|
|
#### 3.2.1 性能测量的实现 |
|
|
|
我们主要采用了外部测量和内部测量相互结合的方式,来评估数据库系统的性能表现和定位性能瓶颈。外部测量的方式主要借助于benchmark完成。内部测量的主要采用插桩来测量数据库的各个部分的性能损耗情况。 |
|
|
|
|
|
|
|
相较于原版的leveldb,FieldDB增加了Field和二级索引功能,因此我们针对新的常见使用场景,增加了benchmark的测试点。新增部分有: |
|
|
|
```c++ |
|
|
|
"CreateIndex," //创建索引 |
|
|
|
"FindKeysByField," //得到包含所有Field的KV对(不使用索引) |
|
|
|
"QueryByIndex," //通过索引得到对应的主键 |
|
|
|
"DeleteIndex," //删除索引 |
|
|
|
"WriteSeqWhileCreating," //创建索引的同时顺序写 |
|
|
|
"WriteSeqWhileDeleting," //删除索引的同时顺序写 |
|
|
|
"WriteRandomWhileCreating," //创建索引的同时随机写 |
|
|
|
"WriteRandomWhileDeleting," //删除索引的同时随机写 |
|
|
|
"ReadSeqWhileCreating," //创建索引的同时顺序读 |
|
|
|
"ReadSeqWhileDeleting," //删除索引的同时顺序读 |
|
|
|
"ReadRandomWhileCreating," //创建索引的同时随机读 |
|
|
|
"ReadRandomWhileDeleting," //删除索引的同时随机读 |
|
|
|
"WriteRandomWithIndex," //随机写带索引的键值 |
|
|
|
"WriteSeqWithIndex," //顺序写带索引的键值 |
|
|
|
"WriteSeqWhileIndependentCCD," //在不断创建删除索引的情况下,顺序写与创删索引无关的数据 |
|
|
|
"WriteSeqWhileCCD," //在不断创建删除索引的情况下,顺序写与创删索引有关的数据 |
|
|
|
``` |
|
|
|
通过上述新增加的benchmark,可以更加全面的了解增加了新功能后的,各个常见使用场景下的FieldDB的性能指标。各个benchmark的具体实现可以在`/benchmarks/db_becnh_FieldDB.cc`中找到。 |
|
|
|
|
|
|
|
为了能够进一步的定位性能瓶颈,我们对于操作的关键路径进行了层次化的插桩分析,实现更加精准的性能测量。根据外部测量得到的数据,相较于leveldb,对于读性能,FieldDB几乎没有影响,但是对于写性能,FieldDB性能有所下降,因此我们着重使用插桩分析了写入的关键路径。由于所收集的数据如下: |
|
|
|
```c++ |
|
|
|
int count = 0;//总计完成请求数量 |
|
|
|
int count_Batch = 0;//总计完成的Batch数量 |
|
|
|
int count_Batch_Sub = 0;//总计完成的Batch_sub数量 |
|
|
|
uint64_t elapsed = 0;//总计时间消耗 |
|
|
|
|
|
|
|
uint64_t construct_elapsed = 0;//构建写入内容消耗 |
|
|
|
uint64_t construct_BatchReq_init_elapsed = 0;//请求初始化消耗 |
|
|
|
uint64_t construct_BatchReq_elapsed = 0;//构建batch的消耗 |
|
|
|
uint64_t construct_BatchReq_Sub_elapsed = 0;//构建batch_sub消耗 |
|
|
|
uint64_t construct_BatchReq_perSub_elapsed = 0;//每个Batch_sub消耗 |
|
|
|
uint64_t construct_FieldsReq_Read_elapsed = 0;//构建时读取的消耗 |
|
|
|
|
|
|
|
uint64_t write_elapsed = 0;//写入的总耗时 |
|
|
|
uint64_t write_meta_elapsed = 0;//写入meta的耗时 |
|
|
|
uint64_t write_index_elapsed = 0;//写入index的耗时 |
|
|
|
uint64_t write_kv_elapsed = 0;//写入kv的耗时 |
|
|
|
uint64_t write_clean_elapsed = 0;//清除meta的耗时 |
|
|
|
|
|
|
|
uint64_t write_bytes = 0; |
|
|
|
uint64_t write_step = 500 * 1024 * 1024; |
|
|
|
uint64_t write_bytes_lim = write_step; |
|
|
|
|
|
|
|
uint64_t temp_elapsed = 0; |
|
|
|
|
|
|
|
uint64_t waiting_elasped = 0; //等待耗时 |
|
|
|
|
|
|
|
inline void dumpStatistics() { |
|
|
|
if(count && count % 500000 == 0 || write_bytes && write_bytes > write_bytes_lim) { |
|
|
|
std::cout << "=====================================================\n"; |
|
|
|
std::cout << "Total Count : " << count; |
|
|
|
std::cout << "\tTotal Write Bytes(MB) : " << write_bytes / 1048576.0 << std::endl; |
|
|
|
std::cout << "Average Time(ms) : " << elapsed * 1.0 / count; |
|
|
|
std::cout << "\tAverage Write rates(MB/s) : " << write_bytes / 1048576.0 / elapsed * 1000000 << std::endl; |
|
|
|
std::cout << "Construct Time(ms) : " << construct_elapsed * 1.0 / count << std::endl; |
|
|
|
std::cout << "\tConstruct BatchReq Init Time(ms) : " << construct_BatchReq_init_elapsed * 1.0 / count << std::endl; |
|
|
|
std::cout << "\tConstruct BatchReq Time(ms) : " << construct_BatchReq_elapsed * 1.0 / count << std::endl; |
|
|
|
std::cout << "\tConstruct BatchReq Sub Time(ms) : " << construct_BatchReq_Sub_elapsed * 1.0 / count << std::endl; |
|
|
|
std::cout << "\tConstruct BatchReq perSub Time(ms) : " << construct_BatchReq_perSub_elapsed * 1.0 / count_Batch_Sub << std::endl; |
|
|
|
std::cout << "\tConstruct FieldsReq Read Time(ms) : " << construct_FieldsReq_Read_elapsed * 1.0 / count << std::endl; |
|
|
|
std::cout << "Write Time(ms) : " << write_elapsed * 1.0 / count << std::endl; |
|
|
|
std::cout << "\tWrite Meta Time(ms) : " << write_meta_elapsed * 1.0 / count << std::endl; |
|
|
|
std::cout << "\tWrite Index Time(ms) : " << write_index_elapsed * 1.0 / count << std::endl; |
|
|
|
std::cout << "\tWrite KV Time(ms) : " << write_kv_elapsed * 1.0 / count << std::endl; |
|
|
|
std::cout << "\tWrite Clean Time(ms) : " << write_clean_elapsed * 1.0 / count << std::endl; |
|
|
|
std::cout << "TaskQueue Size : " << taskqueue_.size() << std::endl; |
|
|
|
std::cout << "temp_elased : " << temp_elapsed * 1.0 / count << std::endl; |
|
|
|
std::cout << "waiting elapsed : " << waiting_elasped * 1.0 / count << std::endl; |
|
|
|
std::cout << "=====================================================\n"; |
|
|
|
write_bytes_lim = write_bytes + write_step; |
|
|
|
std::fflush(stdout); |
|
|
|
} |
|
|
|
} |
|
|
|
``` |
|
|
|
数据收集的方式如下所示(仅展示部分): |
|
|
|
```c++ |
|
|
|
Status FieldDB::HandleRequest(Request &req, const WriteOptions &op) { |
|
|
|
uint64_t start_ = env_->NowMicros(); |
|
|
|
MutexLock L(&mutex_); |
|
|
|
taskqueue_.push_back(&req); |
|
|
|
while(true){ |
|
|
|
uint64_t start_waiting = env_->NowMicros(); |
|
|
|
while(req.isPending() || !req.done && &req != taskqueue_.front()) { |
|
|
|
req.cond_.Wait(); |
|
|
|
} |
|
|
|
waiting_elasped += env_->NowMicros() - start_waiting; |
|
|
|
if(req.done) { |
|
|
|
elapsed += env_->NowMicros() - start_; |
|
|
|
count ++; |
|
|
|
dumpStatistics(); |
|
|
|
return req.s; //在返回时自动释放锁L |
|
|
|
} |
|
|
|
Request *tail = GetHandleInterval(); |
|
|
|
WriteBatch KVBatch,IndexBatch,MetaBatch; |
|
|
|
SliceHashSet batchKeySet; |
|
|
|
Status status; |
|
|
|
} |
|
|
|
} |
|
|
|
/************************************************************************/ |
|
|
|
``` |
|
|
|
|
|
|
|
#### 3.2.2 性能分析与优化 |
|
|
|
|
|
|
|
通过外部测量和内部测量,我们定位到了许多的值得优化的点,并进行迭代,下面将对于两个比较显著的点进行阐述: |
|
|
|
|
|
|
|
1. 消除冗余的写入请求 |
|
|
|
|
|
|
|
通过插桩分析,我们发现对于一个普通的写入,理论上只有对于kvDB写入的流量,但是在实际写入的时候,对于kvDB、metaDB、indexDB都会产生时间消耗。通过审阅代码,我们发现原因在于产生了对于空WriteBatch的写入,因此在写入之前对于WriteBatch的大小进行判断,如果是一个空的WriteBatch,则直接跳过实际写入流程。 |
|
|
|
|
|
|
|
### 3.2 性能测试 |
|
|
|
测试、分析、优化 |
|
|
|
2. 使用Slice代替std::string |
|
|
|
|
|
|
|
进一步分析了写入流程的各个部分后,我们认为实际写入数据库部分的写入消耗已经到了理论上限,在现有的结构上并没有优化的办法。同时,在写入流程中的读数据库也无法很好地优化。我们将目光聚焦于构建请求部分的实现上的优化。经过了代码分析,我们发现了在一开始实现的时候为了实现的便捷,我们大量的使用了stl库的`std::string`,但是有每次`string`的拷贝构造问题,会导致数据的多次在内存中的拷贝操作,在数据量较大的时候,我们认为对于性能会产生影响。 |
|
|
|
|
|
|
|
基于上述的考量,我们通过几轮的commit,将`request`内部的数据结构、相关辅助数据结构以及实现方式全部尽可能的使用`Slice`替换`std::string`。经过测试,我们发现性能确实有所提高。 |
|
|
|
|
|
|
|
|
|
|
|
#### 3.2.3 最终版本的性能分析 |
|
|
|
|
|
|
|
1. 对于leveldb本身的一些分析 |
|
|
|
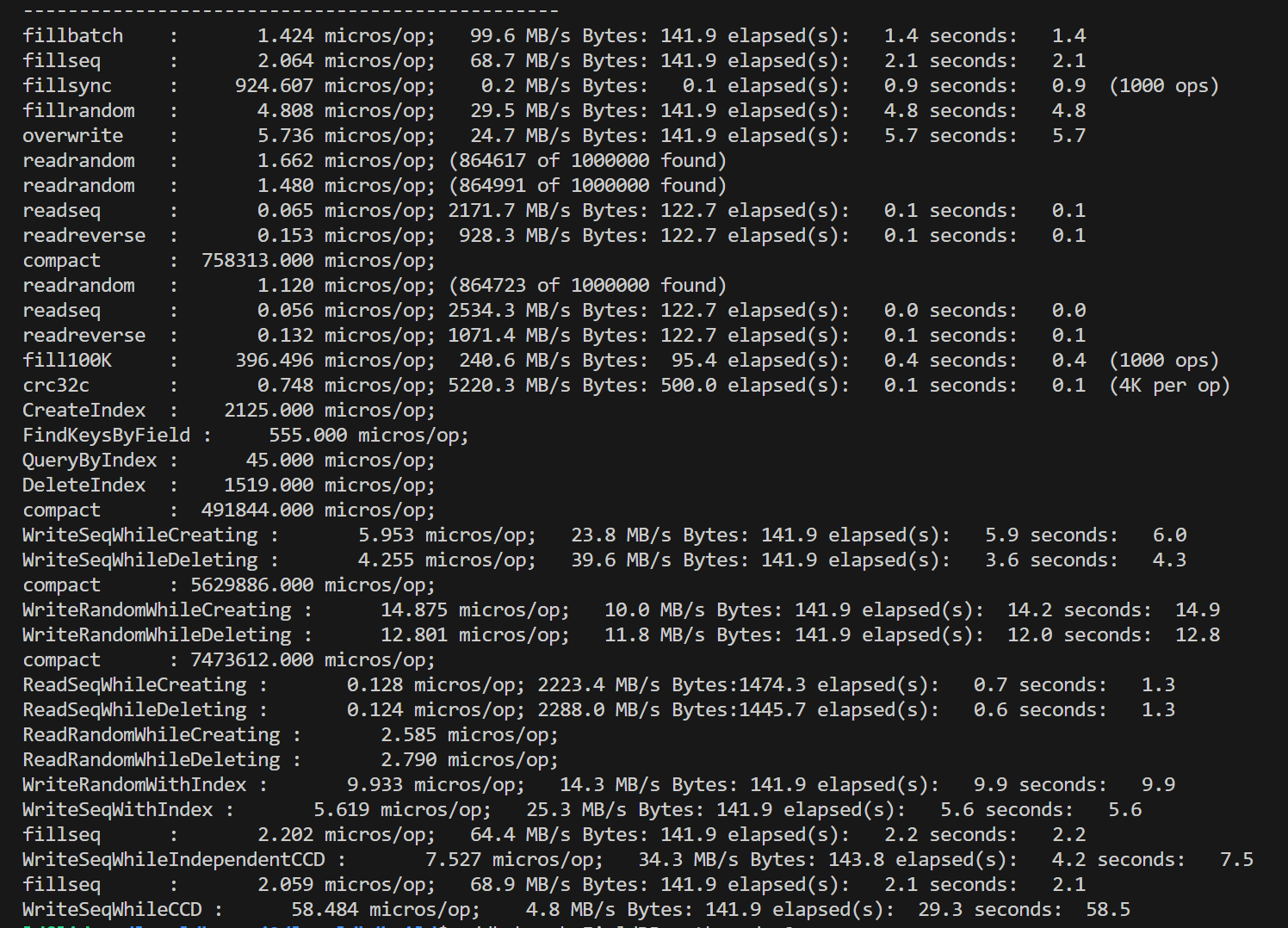
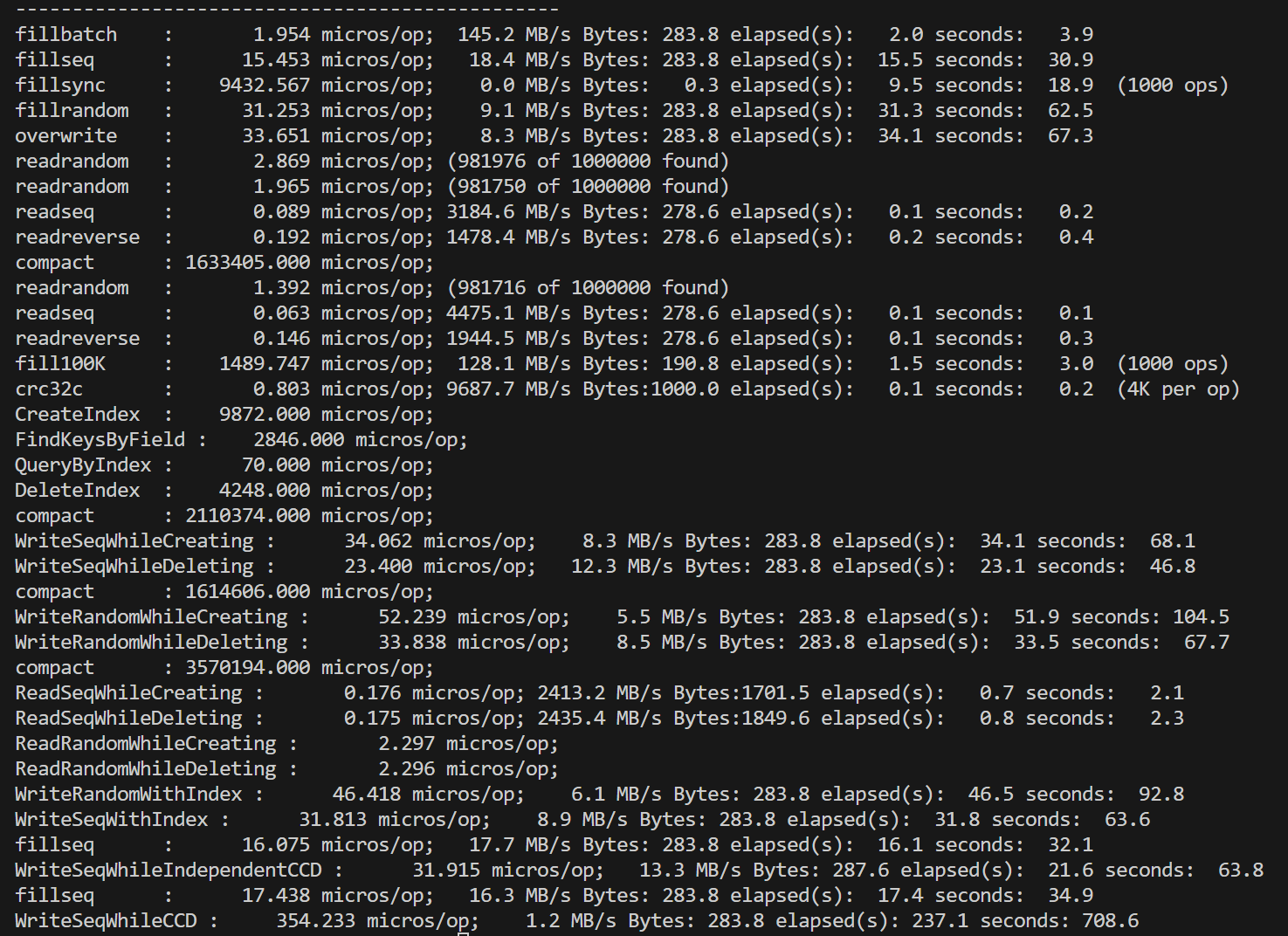
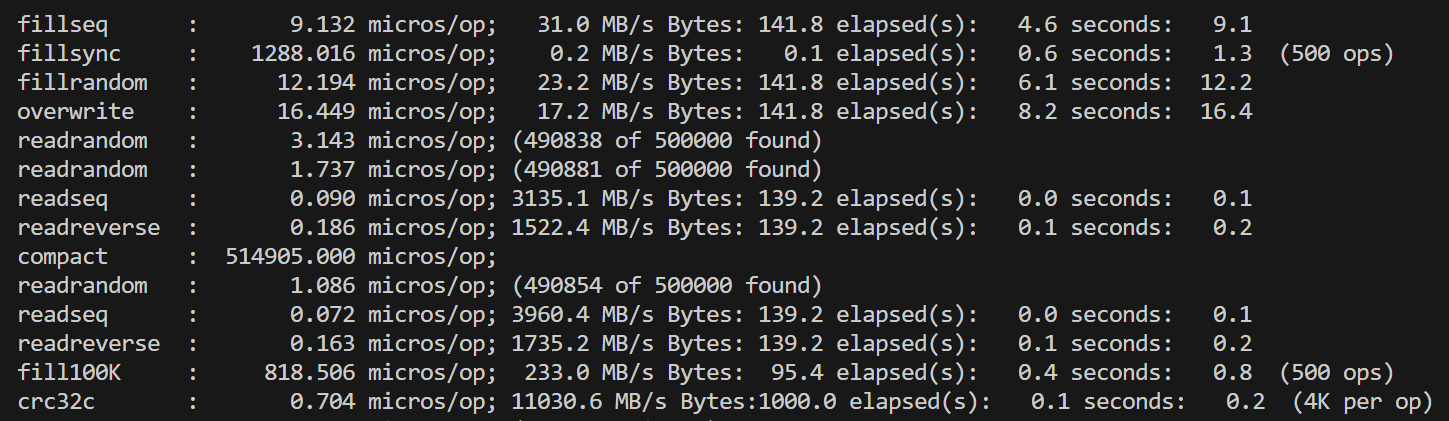
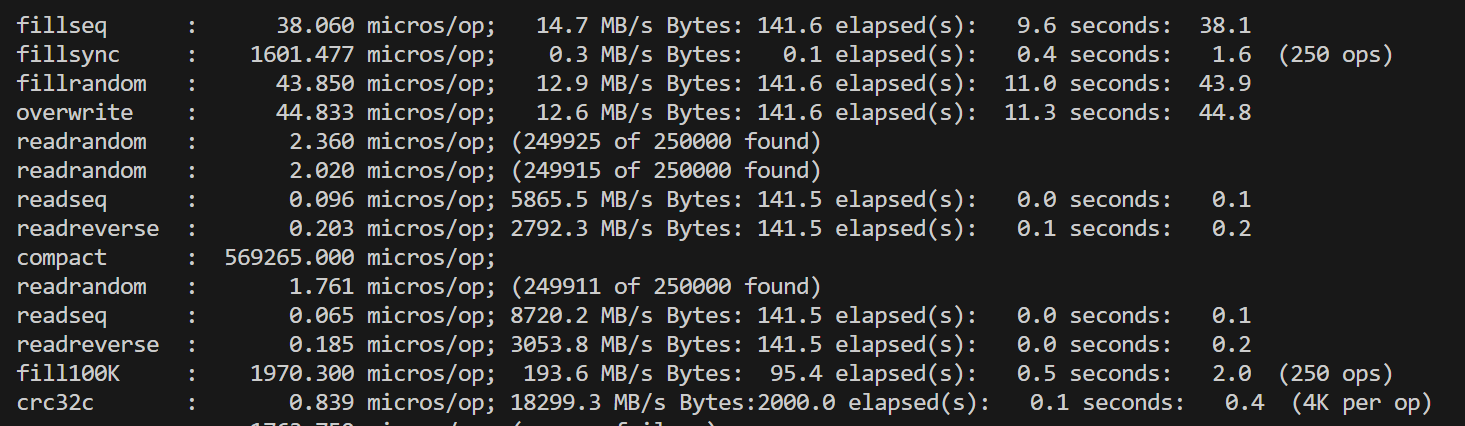
在对fielddb进行性能测试之前,我们首先运行了leveldb自带的db_bench对原版leveldb进行测试。单线程的测试结果总体上符合预期,但是对多线程并发写的测试结果有一些困惑:双线程相比单线程的各种写性能降低了一倍多,四线程再继续降低。考虑到leveldb的写是通过维护写队列、合并writebatch写完成,理论上并发的锁竞争只在写队列,是非常小的。起初我们以为是因为db_bench的数据量随线程翻倍而翻倍,导致了后台合并增加,影响了性能,但修改总数据量为一致后,并没有改变测试结果。 |
|
|
|
单线程 |
|
|
|
 |
|
|
|
双线程 |
|
|
|
 |
|
|
|
四线程 |
|
|
|
 |
|
|
|
|
|
|
|
最后经过多个方面的尝试,我们发现问题的出处。原本的db_bench中所有的写,默认都是每个batch数据量为1。如果扩大了每个batch到1000(总数据量不变),也就是fillbatch测试,多线程这一因素不会影响到性能。 |
|
|
|
 |
|
|
|
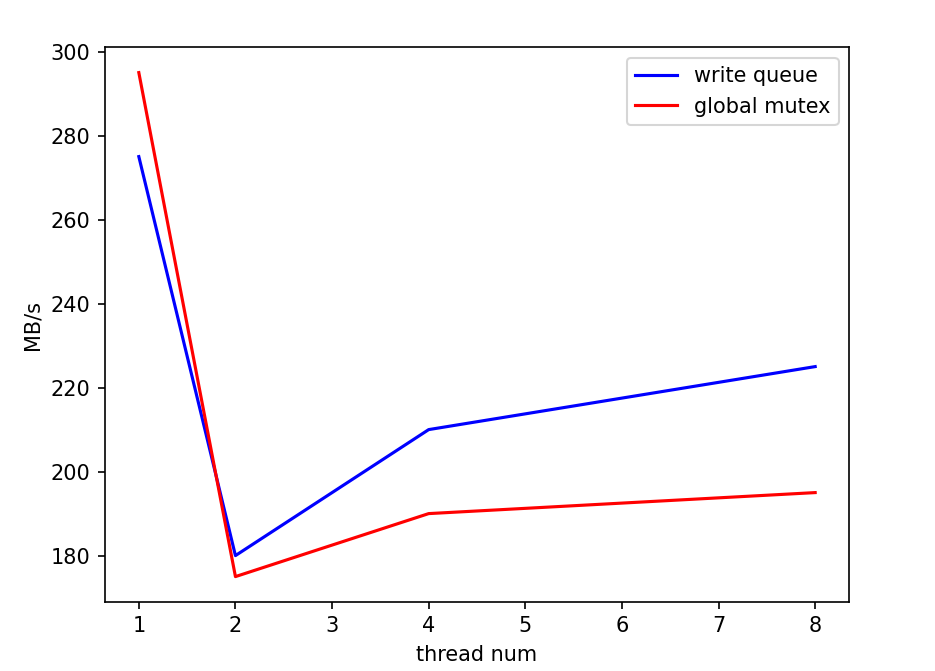
从这一结果倒推可能的原因,我们认为主要问题在于如果每个write的batch过小,实际处理速度过快,使得性能的瓶颈处在了写队列竞争上,而合并写这一策略并没有实际产生效果。我们使用了一个小尝试印证了这一推测:直接对write函数开头使用一把全局互斥锁,对写进行同步。尝试结果是,在原本的batch=1测试中,复杂的写队列策略甚至性能不如直接上全局锁,而随着batch的扩大,写队列策略的性能优势体现了出来,逐渐超过全局锁方法。下面是两种方式的一些比较,测量了顺序写的情况,实验数据取五次平均值: |
|
|
|
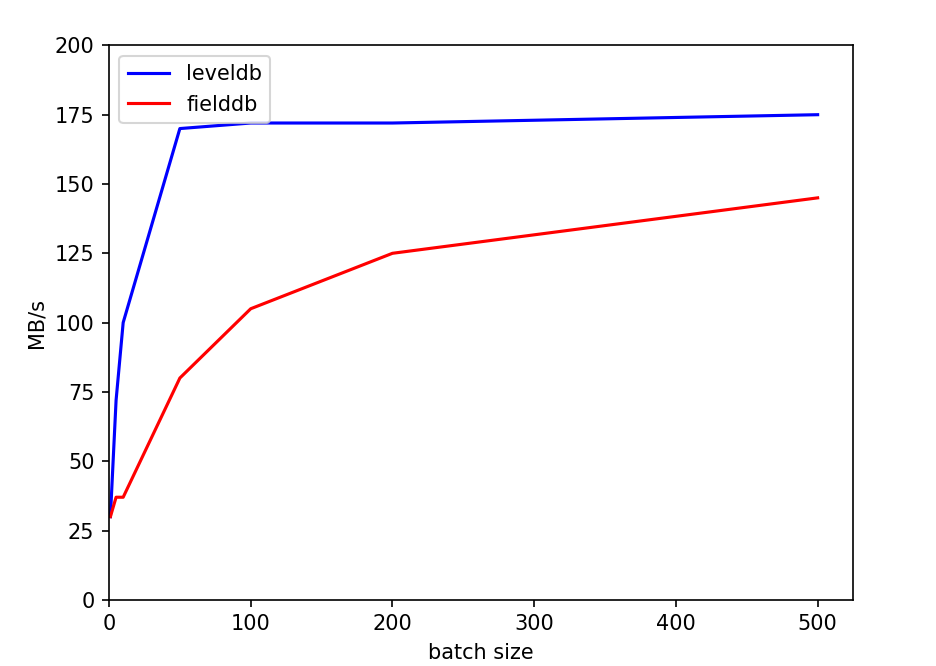
双线程情况下,batchsize对性能的影响: |
|
|
|
 |
|
|
|
|
|
|
|
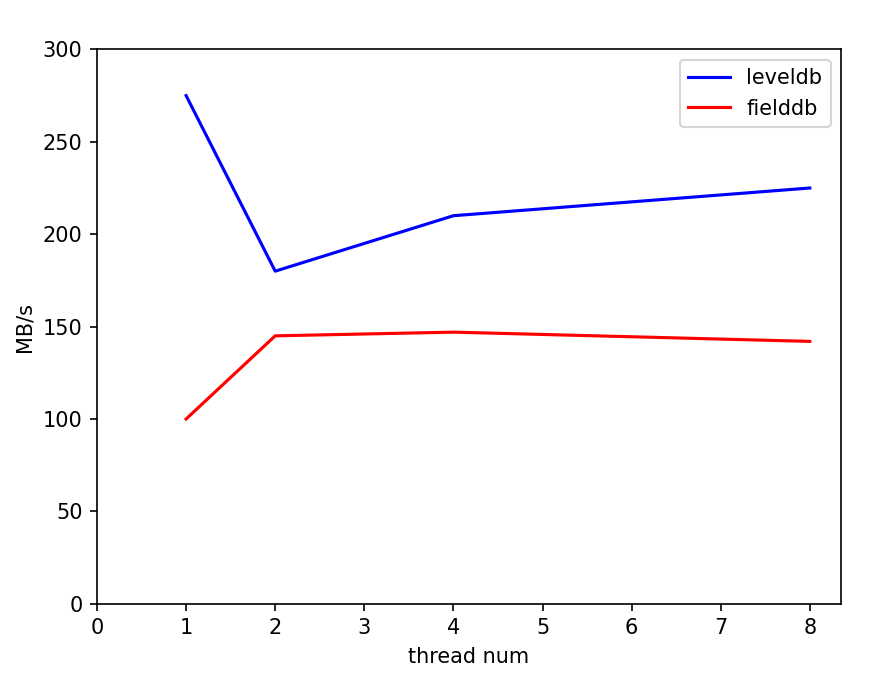
batchsize=1000下,线程数对性能的影响: |
|
|
|
 |
|
|
|
|
|
|
|
这一实验体现了leveldb写队列策略在不同情况下的优劣。而我们fielddb的请求队列策略和这个基本一致,性能使用场景具有相似性。 |
|
|
|
|
|
|
|
2. 对于FieldDB的分析 |
|
|
|
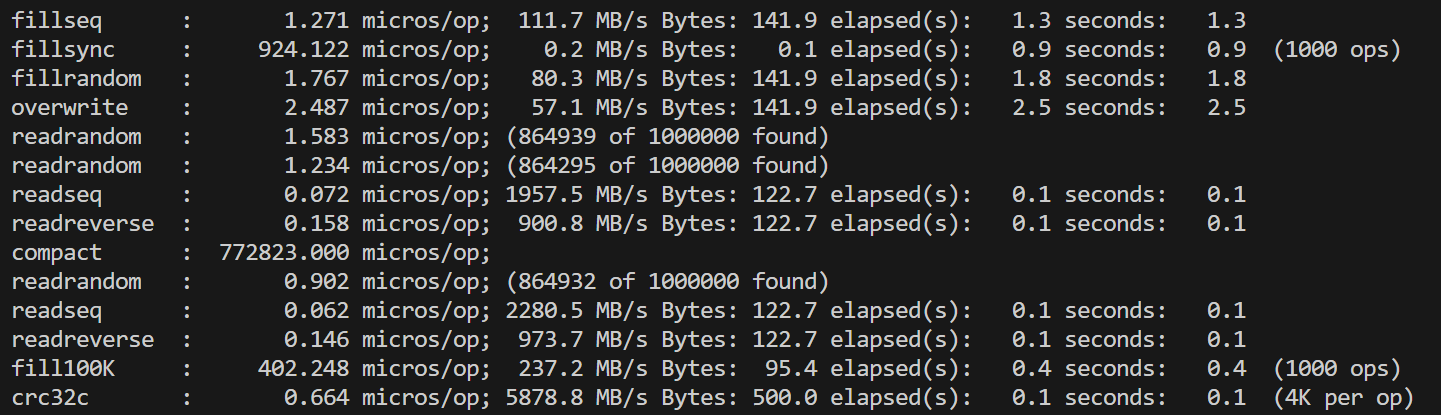
单线程 |
|
|
|
 |
|
|
|
双线程 |
|
|
|
 |
|
|
|
1) 所有涉及读取性能的:和原版leveldb相比,损耗非常少(一个必要的字段解析步骤),还是非常好的 |
|
|
|
2) 常规的写入性能:有所下降,但是由于需要支持索引功能,一些额外的开销无法避免(例如先读一遍,并发控制,一致性维护)。fillbatch的测试,基于我们合并请求和一段请求只处理一次同名key的算法,多线程性能甚至比单线程能够提高许多 |
|
|
|
 |
|
|
|
 |
|
|
|
其中单线程fillbatch差异比较明显。这里面的主要原因,一是因为leveldb本身这方面性能就非常优秀,二是因为在有索引功能的情况下,为了避免之前提到的问题,我们处理batch实际上还是需要把里面的每一条数据拆分出来,分别创建请求处理(而不是直接批量写入)。 |
|
|
|
这也反映在batchsize图中,我们的性能上升速率不如leveldb。但同样可观的上升速率意味着,我们的请求处理算法是有一定效果的。 |
|
|
|
3) 对于创删索引:没有比较对象,但是总体可以接受 |
|
|
|
4) 对于创删索引和写并发:如果是无关的,那么还是保持了高吞吐;如果是相关的,那么不得不受限于创删索引。考虑到数据库的创删索引请求还是比较少的(不太可能出现我们测试中,不停并发创删索引和写入的情况),一定的性能牺牲可以接受 |
|
|
|
|
|
|
|
#### 3.2.4 写放大问题的一些讨论 |
|
|
|
相比原版leveldb,我们的写放大问题主要在于metadb需要多一次日志写入。但leveldb的写放大本身比较严重,问题在于文件合并时的处理。这一具体的数值,取决于数据量变化造成的文件数量变化(通常在30~50倍)。我们在测试中进行了一些插桩,比较数据本身和log中统计得到的磁盘写入,在不触发大合并、不插入重复数据、不删除数据的前提下,kv本身写放大大约在1.8倍(索引不计入其中)。即使加上kv和meta的两份日志,和合并时几十倍相比仍然很少,并不是系统的主要问题。至于metadb本身的数据,我们会在写完后进行清理,不会进行实际的落盘,所以也没有额外的开销。(当然上述前提是写入数据有索引,需要写meta,否则我们的写是和原版保持一致的) |
|
|
|
|
|
|
|
## 4. 问题与解决 |
|
|
|
### 设计层面 |
|
|
|
1. 我们对并发的写入请求进行了合并,但在测试中发现了一个问题:之前提到,putfield和delete都需要先读一次原来的数据,但他们读不到合并在一起的请求中,之前的那个数据。这就导致了不一致(e.g. 将对于同一个key的putfield和delete请求合并,处理putfield时本次处理要写kv和index,处理delete时先读,发现数据库原来的数据中字段没有索引,于是删kv但没有删index)。我们的解决方式是,对于并发的写入只处理第一个相同的key。这同样提高了处理请求的效率。 |
|
|
|
|
|
|
|
### 一些调试较久的bug |
|
|
|
1. 测试部分srand、全局set多线程问题。 |
|
|
|
2. destroydb是全局的函数,而fielddb重新实现了一次。但在实际使用时忘记加fielddb的命名空间,导致调用了leveldb的destroy,而fielddb数据库一直没有正确删除。 |
|
|
|
3. 迭代器使用后忘记delete,导致版本一直没有unref。 |
|
|
|
4. 性能测试中创建索引时间慢于读,如果并发一个读和创会把创建的时间统计入读的时间。最后改为读线程一直循环读,直到创建完成后通知该线程结束。 |
|
|
|
|
|
|
|
## 5. 潜在优化点 |
|
|
|
1. 使用一些高性能并发设计模式,如reactor来优化多线程写入时由于锁竞争导致的性能问题 |
|
|
|
2. 采用一些高性能的库,如dpdk等 |
|
|
|
3. 使用一些基于polling的请求处理手段等 |
|
|
|
4. 对于各个log进行合并,减少写放大 |
|
|
|
5. `GetHandleInterval`中选择一段request时,设置一个上限(综合考量max_batchsize和索引写入开销),和子数据库的批量写对齐。 |
|
|
|
6. 创删索引时会先产生中间结果,再向indexdb批量写。设置一个单次写的上限,分批次写入中间结果。 |
|
|
|
7. 涵盖复杂的数据库故障问题,比如硬件故障、恢复文件丢失等。 |
|
|
|
|
|
|
|
## 6. 分工 |
|
|
|
功能 | 完成日期 | 分工 |
|
|
|
:------|:---------|:------ |
|
|
|
value序列化、lab1功能实现|11.19|李度 |
|
|
|
fieldDb接口框架|11.25|陈胤遒 |
|
|
|
lab1整体+测试|11.30|李度、陈胤遒、高宇菲 |
|
|
|
fieldDb功能实现(没有并发和恢复)|12.10|李度、陈胤遒 |
|
|
|
并发框架|12.15|陈胤遒 |
|
|
|
lab2测试、并发完成|12.20|李度 |
|
|
|
恢复|12.25|李度、陈胤遒 |
|
|
|
整体系统整合+测试|12.28|李度、陈胤遒、高宇菲 |
|
|
|
性能测试|1.1|李度、陈胤遒、高宇菲 |
|
|
|
|
|
|
|
## 7. KV分离 |
|
|
|
由于在讨论的时候我们想到了一种感觉非常思路清晰、实现简单的实现kv分离的方案,在基本完成了实验报告后,我们抽空花了一天半基本上实现了kv分离,代码总计700行左右下面对于设计进行最简单的介绍 |
|
|
|
|
|
|
|
### 7.1 KVLog |
|
|
|
我们实现kv分离的主要途径是使用KVLog和FilePointer。KVLog和SSTable在生成的时候是一一对应的,但是并不随着SSTable的合并而合并。KVLog是一个如下结构的文件类型: |
|
|
|
``` |
|
|
|
Batchsize|WriteBatch|Batchsize|WriteBatch|...... |
|
|
|
``` |
|
|
|
`FilePointer`包含三个信息,分别是KVLog的文件编号,偏移量以及信息的长度。 |
|
|
|
|
|
|
|
从逻辑结构来看,非常类似于leveldb的log,两者本质上存储的都是一系列的WriteBatch。但是不同的是,leveldb的log会每4KB对于内容进行切分,这会导致无法直接通过`(偏移量,长度)`读出内容,而KVLog是连续的存储,是可以直接通过`(偏移量,长度)`读出内容的。 |
|
|
|
|
|
|
|
由于leveldb的写入原子性是通过基于log文件的结构完成的,且log在写入和恢复的路径中被大量的使用,因此我们不直接使用KVLog替换log,而是先将WriteBatch写入KVLog,然后将该WriteBatch对应的`FilePointer`写入log中。这样子我们只要对于涉及log的代码进行最简单的更改即可。 |
|
|
|
|
|
|
|
之后,我们对于写入到memtable和SSTable中的内容进行处理,将所有的value替换成相应的`FilePointer`。 |
|
|
|
|
|
|
|
以上就是对于写入流程的处理,部分核心代码如下: |
|
|
|
```c++ |
|
|
|
Status DBImpl::Write(const WriteOptions& options, WriteBatch* updates) { |
|
|
|
/******************************/ |
|
|
|
FilePointer fp; |
|
|
|
//1. 将WriteBatch写入到kvlog中 |
|
|
|
status = kvlog_->AddRecord(WriteBatchInternal::Contents(write_batch), fp); |
|
|
|
//2. 将writebatch的filepointer写入到log中 |
|
|
|
// status = log_->AddRecord(WriteBatchInternal::Contents(write_batch)); |
|
|
|
char rep[8 * 3]; |
|
|
|
EncodeFP(fp, rep); |
|
|
|
status = log_->AddRecord(Slice(rep, 3 * 8)); |
|
|
|
bool sync_error = false; |
|
|
|
if (status.ok() && options.sync) { |
|
|
|
status = logfile_->Sync(); |
|
|
|
if (!status.ok()) { |
|
|
|
sync_error = true; |
|
|
|
} |
|
|
|
} |
|
|
|
//3. 根据write_batch里面的内容,构建kp_batch |
|
|
|
WriteBatchInternal::ConstructKPBatch(tmp_kp_batch_, write_batch, fp); |
|
|
|
WriteBatchInternal::SetSequence(tmp_kp_batch_,temp_seq + 1); |
|
|
|
if (status.ok()) { |
|
|
|
status = WriteBatchInternal::InsertInto(tmp_kp_batch_, mem_); |
|
|
|
} |
|
|
|
/******************************/ |
|
|
|
} |
|
|
|
|
|
|
|
class KVLog; //用于KVLog的写入 |
|
|
|
class KVLogReader;//用于读取KVLog中的每一个键值对以及相应的sequence |
|
|
|
struct FilePointer { |
|
|
|
uint64_t FileNumber; |
|
|
|
uint64_t FileOffset; |
|
|
|
uint64_t Size; |
|
|
|
}; |
|
|
|
``` |
|
|
|
|
|
|
|
### 7.2 KVLog的管理 |
|
|
|
KVLog的管理主要参考的是SSTable的方式,采用多版本并发控制的思路。原因主要有两点:1. 有利于KVLog回收的实现;2.可以大量的复用或者参考SSTableFile的实现方式。核心代码如下: |
|
|
|
```c++ |
|
|
|
class VersionEdit { |
|
|
|
/*****************************/ |
|
|
|
void AddKVLogs(uint64_t file) { |
|
|
|
FileMetaData f; |
|
|
|
f.number = file; |
|
|
|
new_kvlogs_.push_back(f); |
|
|
|
} |
|
|
|
|
|
|
|
void RemoveKVLogs(uint64_t file) { |
|
|
|
deleted_kvlogs_.insert(file); |
|
|
|
} |
|
|
|
std::set<uint64_t> deleted_kvlogs_; |
|
|
|
std::vector<FileMetaData> new_kvlogs_; |
|
|
|
/*****************************/ |
|
|
|
} |
|
|
|
|
|
|
|
class VersionSet{ |
|
|
|
/*****************************/ |
|
|
|
void AddLiveKVLogs(std::set<uint64_t>* live_kvlogs); |
|
|
|
std::vector<FileMetaData*> kvlogs_; |
|
|
|
void Apply(const VersionEdit* edit); |
|
|
|
void SaveTo(Version* v); |
|
|
|
/*****************************/ |
|
|
|
} |
|
|
|
``` |
|
|
|
|
|
|
|
### 7.3 KVLog的回收 |
|
|
|
我们观察到Level0的SSTable是允许重叠的。因此,我们将KVLog的回收放在后台,同时禁止小合并将新生成SSTable放于L0以下的位置,这样可以保证L0以下的level不变。然后只回收KVLog不与mem、imm和L0SSTableu对应的kvlog。回收的时候新构建一个放在L0的SSTable以及对应的KVLog。新生成的SSTable包含的key和原来的sequence完全相同,value指向新的KVLog。这样子,随着之后的合并,自然就能够完成回收的操作也不会和并发的写入发生冲突。代码主体是`bool DBImpl::CollectKVLogs()`. |
|
|
|
|
|
|
|
以上就是对于我们实现KV分离方式的最简要的介绍 |


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

{kind=link}
{kind=link}