|
|
|
@ -584,7 +584,7 @@ InsertOneField:只插一条特定数据的测试(让key<=0, 和批量写入 |
|
|
|
DeleteOneField:只删一条特定数据的测试,功能与单条插入相似,主要用来测试delete。 |
|
|
|
GetOneField:只读一条特定数据的测试,与上面两条对应。 |
|
|
|
|
|
|
|
对于所有涉及随机性的函数,传参一个随机种子。只要随机种子一致,随机生成的内容就一致,相应的读需要和相应的写、删保持一致。此外测试的数据量也是可以修改的。 |
|
|
|
对于所有涉及随机性的函数,传参一个随机种子。只要随机种子一致,随机生成的内容就一致,相应的读需要和相应的写、删保持一致。此外测试的数据量也是可以修改的。需要注意的是,之前项目使用的srand线程不安全,使用std::mt19937可以保证多线程时随机序列也一致。 |
|
|
|
|
|
|
|
InsertFieldData:批量写入,按照上面提到的测试规则生成kv,并调用putfields。检查返回状态是否ok。同时对于生成的字段,如果是address为shanghai或age为20,统计入相应的set。 |
|
|
|
|
|
|
|
@ -612,7 +612,8 @@ TestLab1流程: 批量写 -> 必须读到 -> findkeysbycity -> 批量删 -> |
|
|
|
|
|
|
|
TestLab2流程:批量写 -> 创索引address,age -> 索引查询address,age -> 删索引address -> 索引查询address(haveindex=false) -> 索引查询age -> 批量删 -> 索引查询age(索引还在能查,但返回的key数量为0) -> write -> 必须读到 -> 索引查询age。 |
|
|
|
|
|
|
|
至此,上面的流程基本覆盖了我们数据库的每个基础功能。 |
|
|
|
至此,上面的流程基本覆盖了我们数据库的每个基础功能。 |
|
|
|
 |
|
|
|
|
|
|
|
#### 3.1.2 并发测试 |
|
|
|
相关代码在`parallel_test.cc`中 |
|
|
|
@ -631,7 +632,8 @@ TestPutDelete:创索引 -> 并发:两线程写0、1种子数据,两线程 |
|
|
|
TestWrite(在之前基础上并发所有,并加入write):创索引address、批量写种子2 -> 并发:线程0创索引age,其他线程忙等至开始创建,线程1批量写种子0,线程2write种子1, 线程3删索引age -> 检测:种子012所有数据都应被读到,一致性, age索引被删除。 |
|
|
|
这里的测试也可以加入delete,或不删索引age检测age的一致性,具体见注释。 |
|
|
|
|
|
|
|
至此,上面的流程基本覆盖了我们数据库的每个基础功能之间的并发。 |
|
|
|
至此,上面的流程基本覆盖了我们数据库的每个基础功能之间的并发。 |
|
|
|
 |
|
|
|
|
|
|
|
#### 3.1.2 恢复测试 |
|
|
|
相关代码在`recover_test.cc`中 |
|
|
|
@ -640,7 +642,8 @@ TestWrite(在之前基础上并发所有,并加入write):创索引addres |
|
|
|
TestNormalRecover:创索引、批量写、此时之前测试都检测过能被读到 -> delete db -> 重新open -> 读数据、索引查(之前写入的数据仍能被读到)。 |
|
|
|
|
|
|
|
TestParalRecover**该测试比较特别,需要运行两次**:创索引 -> 并发:线程0批量写,线程1write,线程2delete,线程3 在单条插入后,deletedb。线程3导致了其他线程错误,测试会终止(模拟数据库崩溃),这会导致各线程在各种奇怪的时间点崩溃。此时注释掉上半部分代码,运行下半部分:单条写入能被读到,并检测一致性。 |
|
|
|
这里我们运行了几十次,前半部分的崩溃报错有多种,但后半部分的运行都是成功的。同时也追踪了恢复的运行过程,确实有数据从metadb中被正确解析。 |
|
|
|
这里我们运行了几十次,前半部分的崩溃报错有多种,但后半部分的运行都是成功的。同时也追踪了恢复的运行过程,确实有数据从metadb中被正确解析。 |
|
|
|
 |
|
|
|
|
|
|
|
### 3.2 性能测试、分析、优化 |
|
|
|
|
|
|
|
@ -666,7 +669,7 @@ TestParalRecover**该测试比较特别,需要运行两次**:创索引 -> |
|
|
|
"WriteSeqWhileIndependentCCD," //在不断创建删除索引的情况下,顺序写与创删索引无关的数据 |
|
|
|
"WriteSeqWhileCCD," //在不断创建删除索引的情况下,顺序写与创删索引有关的数据 |
|
|
|
``` |
|
|
|
通过上述新增加的benchmark,可以更加全面的了解增加了新功能后的,各个常见使用场景下的FieldDB的性能指标。各个benchmark的具体实现可以在`/becnmarks/db_becnh_FieldDB.cc`中找到。 |
|
|
|
通过上述新增加的benchmark,可以更加全面的了解增加了新功能后的,各个常见使用场景下的FieldDB的性能指标。各个benchmark的具体实现可以在`/benchmarks/db_becnh_FieldDB.cc`中找到。 |
|
|
|
|
|
|
|
为了能够进一步的定位性能瓶颈,我们对于操作的关键路径进行了层次化的插桩分析,实现更加精准的性能测量。根据外部测量得到的数据,相较于leveldb,对于读性能,FieldDB几乎没有影响,但是对于写性能,FieldDB性能有所下降,因此我们着重使用插桩分析了写入的关键路径。由于所收集的数据如下: |
|
|
|
```c++ |
|
|
|
@ -745,10 +748,12 @@ Status FieldDB::HandleRequest(Request &req, const WriteOptions &op) { |
|
|
|
WriteBatch KVBatch,IndexBatch,MetaBatch; |
|
|
|
SliceHashSet batchKeySet; |
|
|
|
Status status; |
|
|
|
} |
|
|
|
} |
|
|
|
/************************************************************************/ |
|
|
|
``` |
|
|
|
|
|
|
|
#### 3.2.2 性能分析与优化(需要加上相关的性能分析结果) |
|
|
|
#### 3.2.2 性能分析与优化 |
|
|
|
|
|
|
|
通过外部测量和内部测量,我们定位到了许多的值得优化的点,并进行迭代,下面将对于两个比较显著的点进行阐述: |
|
|
|
|
|
|
|
@ -763,26 +768,70 @@ Status FieldDB::HandleRequest(Request &req, const WriteOptions &op) { |
|
|
|
基于上述的考量,我们通过几轮的commit,将`request`内部的数据结构、相关辅助数据结构以及实现方式全部尽可能的使用`Slice`替换`std::string`。经过测试,我们发现性能确实有所提高。 |
|
|
|
|
|
|
|
|
|
|
|
#### 3.2.3 最终版本的性能分析(草稿) |
|
|
|
|
|
|
|
1. 对于leveldb本身的一些分析(着重于多线程性能方面) |
|
|
|
|
|
|
|
2. 对于FieldDB的分析 |
|
|
|
|
|
|
|
1) 所有涉及读取性能的:和原版leveldb相比,几乎没有任何的损耗,还是非常好的 |
|
|
|
2) 常规的写入性能:有所下降,但是由于是因为需要增加读操作,无法避免 |
|
|
|
3) 对于创删索引:总体态度是虽然没有比较对象,但是总体可以接受 |
|
|
|
4) 对于创删索引和写并发:如果是无关的,那么还是保持了高吞吐;如果是相关的,那么不得不受限于创删索引 |
|
|
|
#### 3.2.3 最终版本的性能分析 |
|
|
|
|
|
|
|
1. 对于leveldb本身的一些分析 |
|
|
|
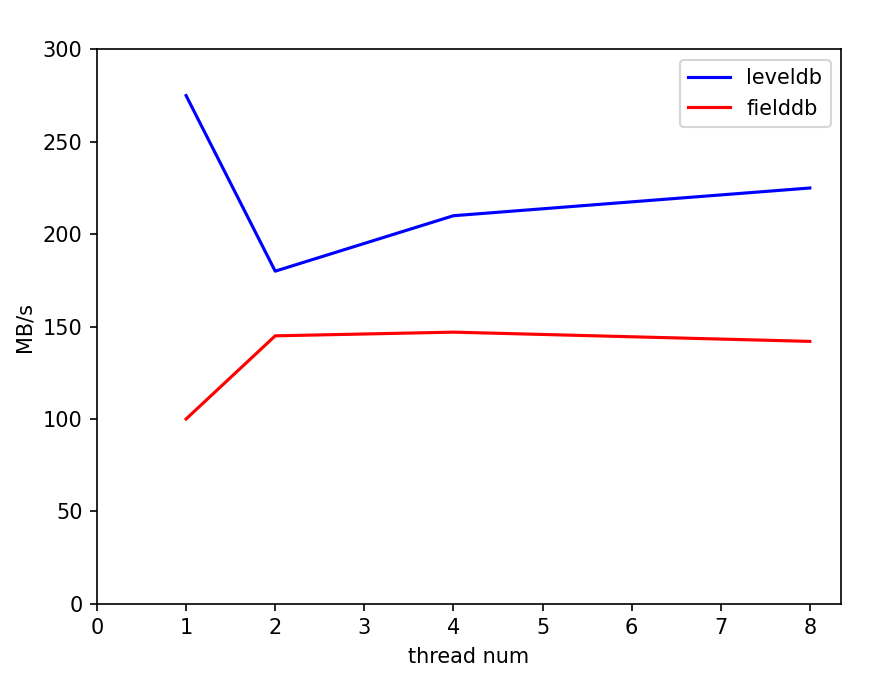
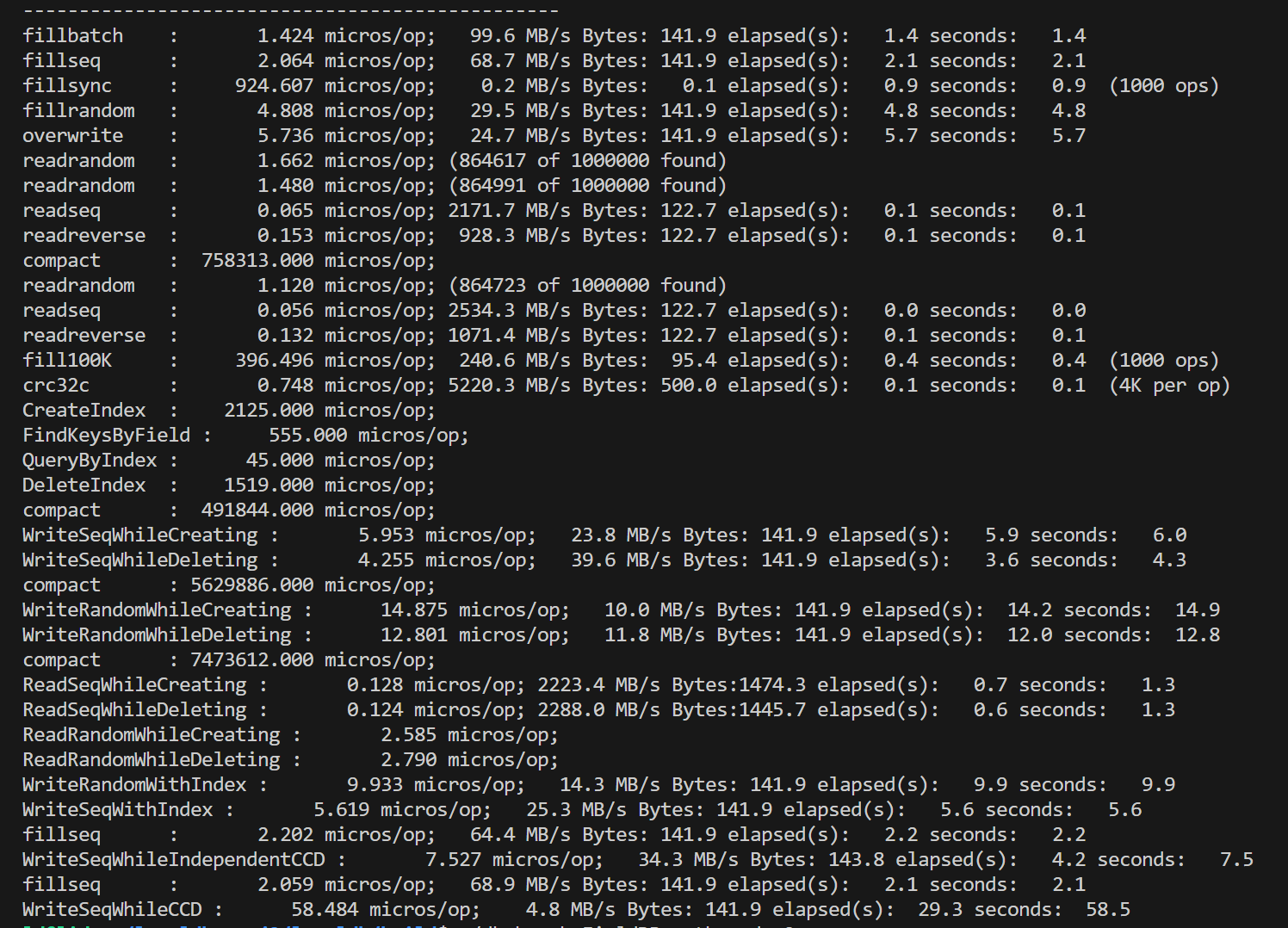
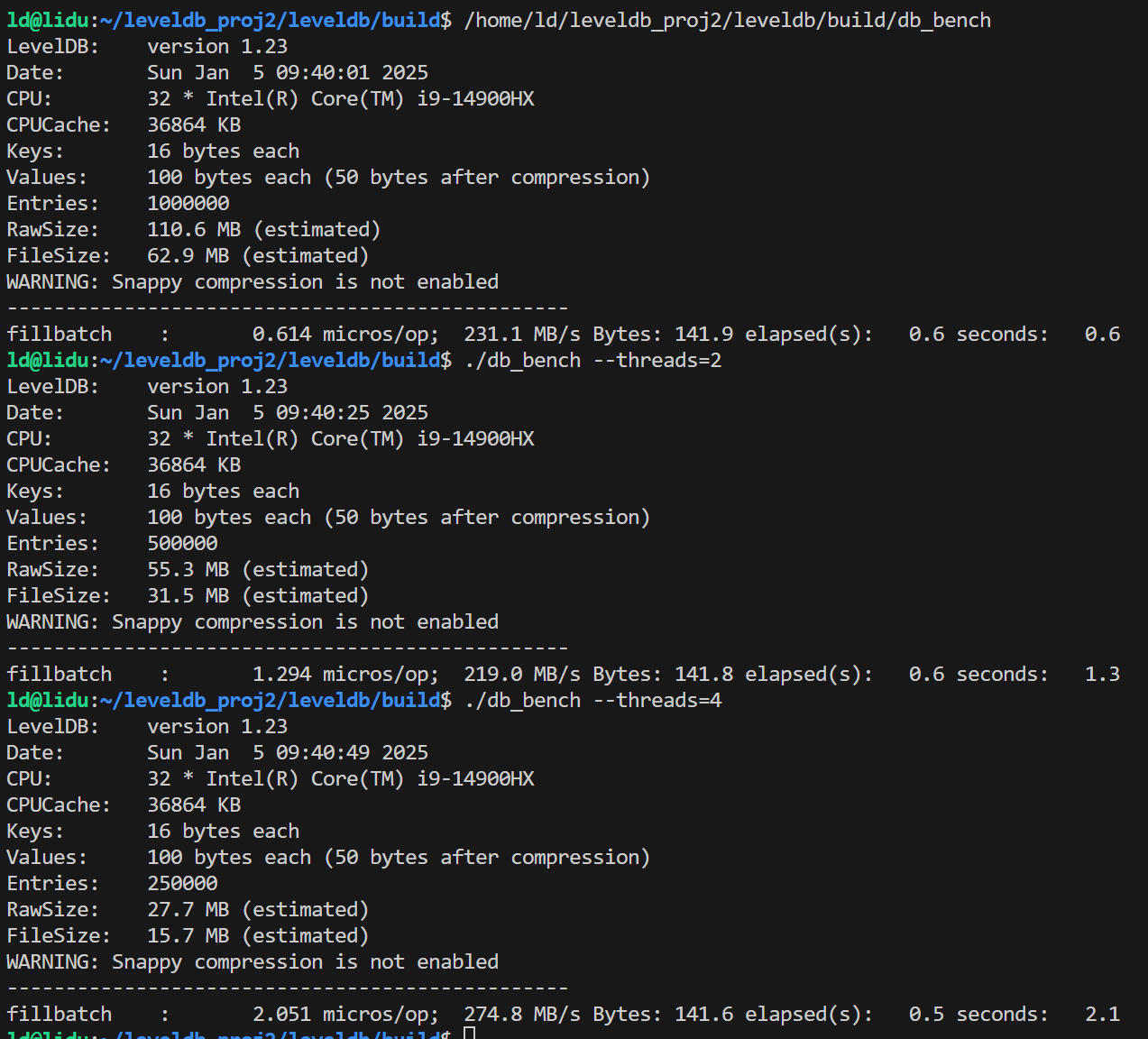
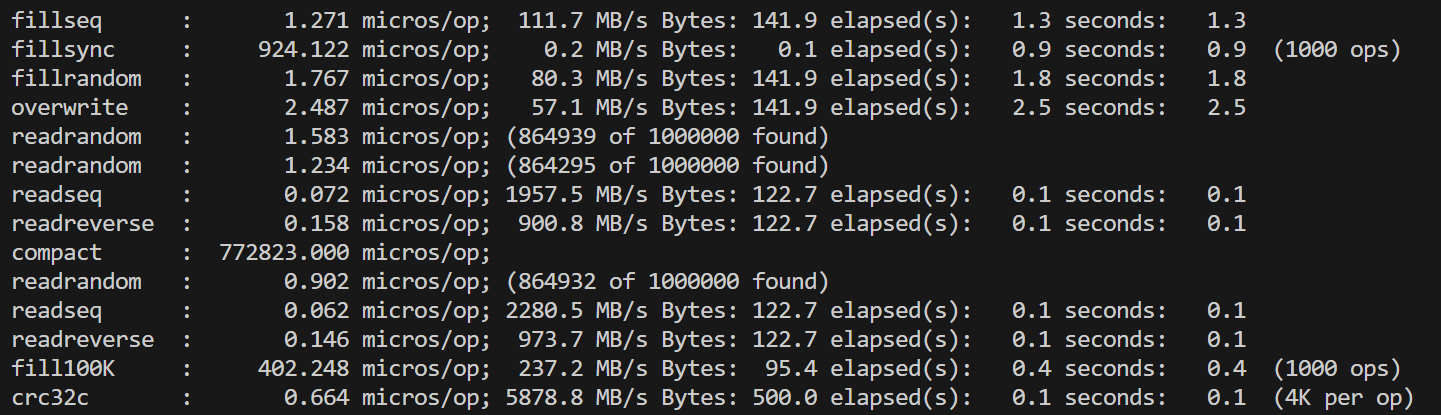
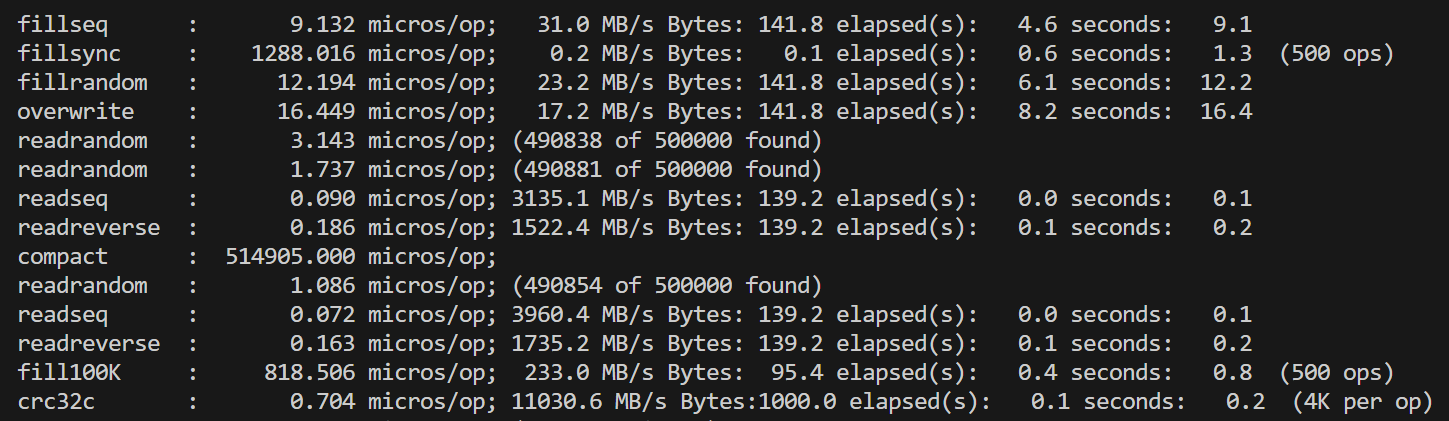
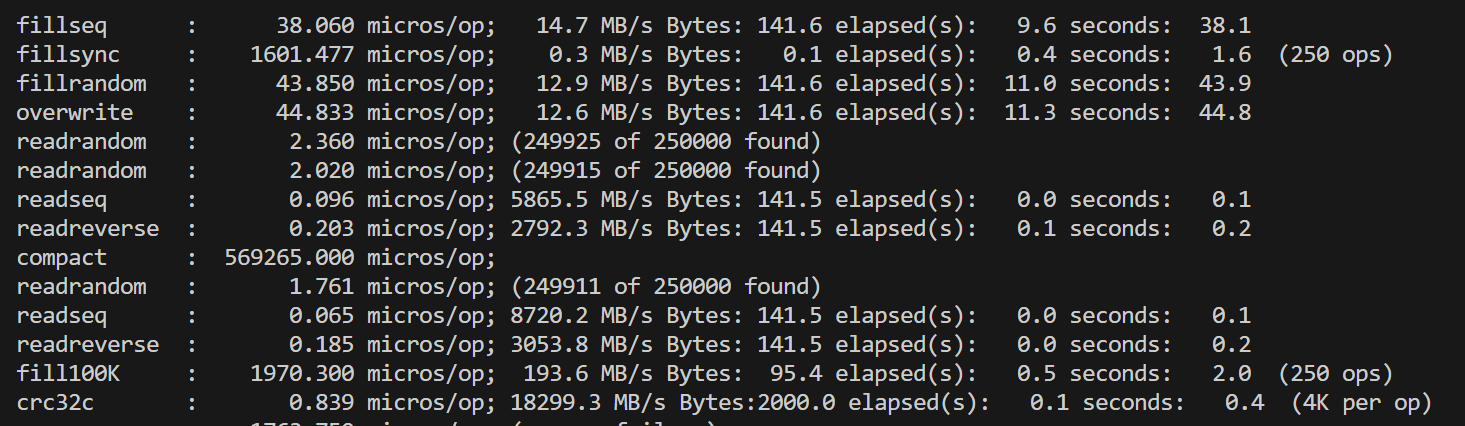
在对fielddb进行性能测试之前,我们首先运行了leveldb自带的db_bench对原版leveldb进行测试。单线程的测试结果总体上符合预期,但是对多线程并发写的测试结果有一些困惑:双线程相比单线程的各种写性能降低了一倍多,四线程再继续降低。考虑到leveldb的写是通过维护写队列、合并writebatch写完成,理论上并发的锁竞争只在写队列,是非常小的。起初我们以为是因为db_bench的数据量随线程翻倍而翻倍,导致了后台合并增加,影响了性能,但修改总数据量为一致后,并没有改变测试结果。 |
|
|
|
单线程 |
|
|
|
 |
|
|
|
双线程 |
|
|
|
 |
|
|
|
四线程 |
|
|
|
 |
|
|
|
|
|
|
|
最后经过多个方面的尝试,我们发现问题的出处。原本的db_bench中所有的写,默认都是每个batch数据量为1。如果扩大了每个batch到1000(总数据量不变),也就是fillbatch测试,多线程这一因素不会影响到性能。 |
|
|
|
 |
|
|
|
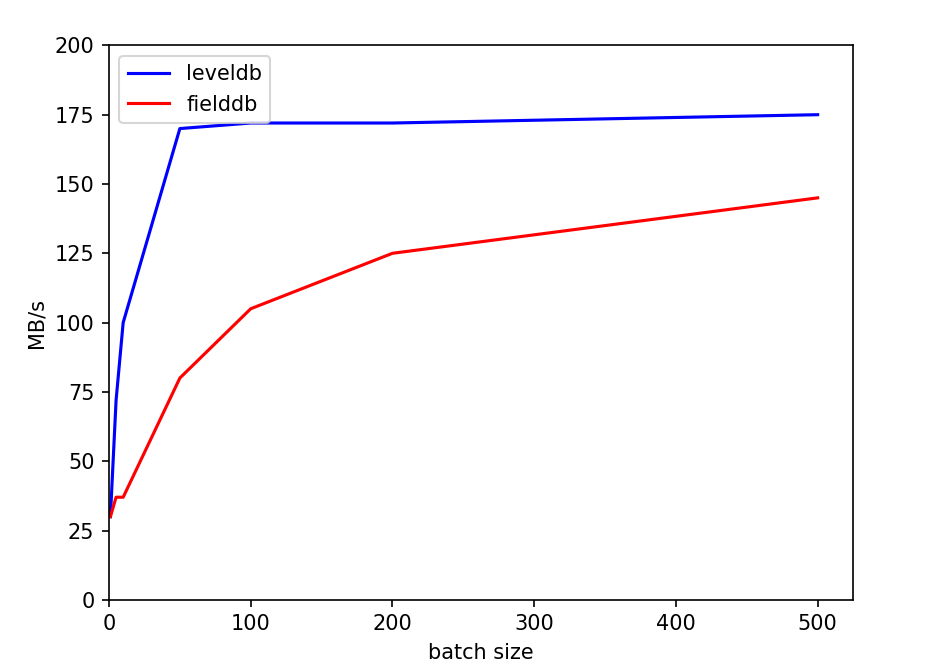
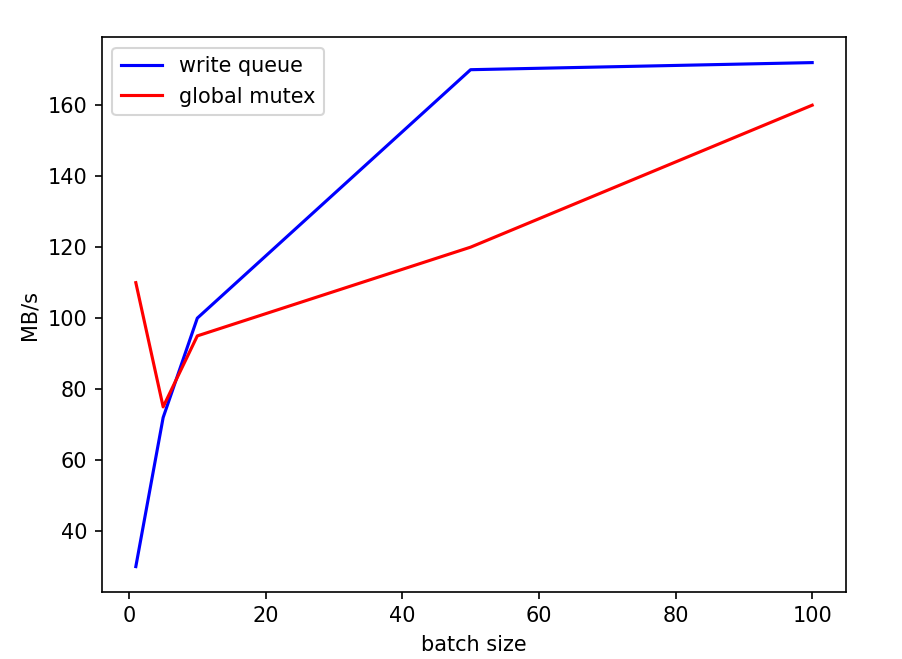
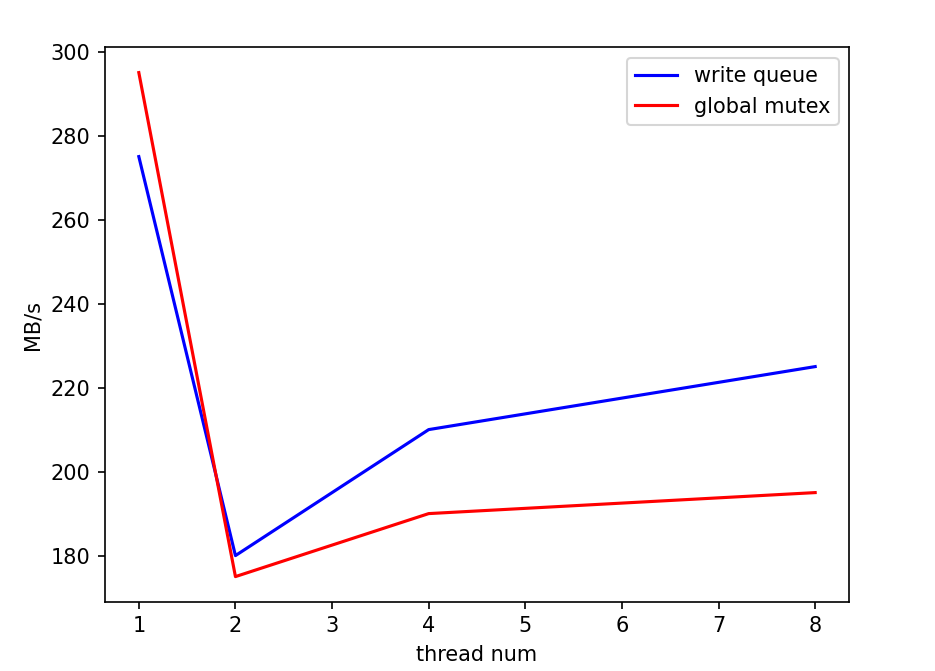
从这一结果倒推可能的原因,我们认为主要问题在于如果每个write的batch过小,实际处理速度过快,使得性能的瓶颈处在了写队列竞争上,而合并写这一策略并没有实际产生效果。我们使用了一个小尝试印证了这一推测:直接对write函数开头使用一把全局互斥锁,对写进行同步。尝试结果是,在原本的batch=1测试中,复杂的写队列策略甚至性能不如直接上全局锁,而随着batch的扩大,写队列策略的性能优势体现了出来,逐渐超过全局锁方法。下面是两种方式的一些比较,测量了顺序写的情况,实验数据取五次平均值: |
|
|
|
双线程情况下,batchsize对性能的影响: |
|
|
|
 |
|
|
|
|
|
|
|
batchsize=1000下,线程数对性能的影响: |
|
|
|
 |
|
|
|
|
|
|
|
这一实验体现了leveldb写队列策略在不同情况下的优劣。而我们fielddb的请求队列策略和这个基本一致,性能使用场景具有相似性。 |
|
|
|
|
|
|
|
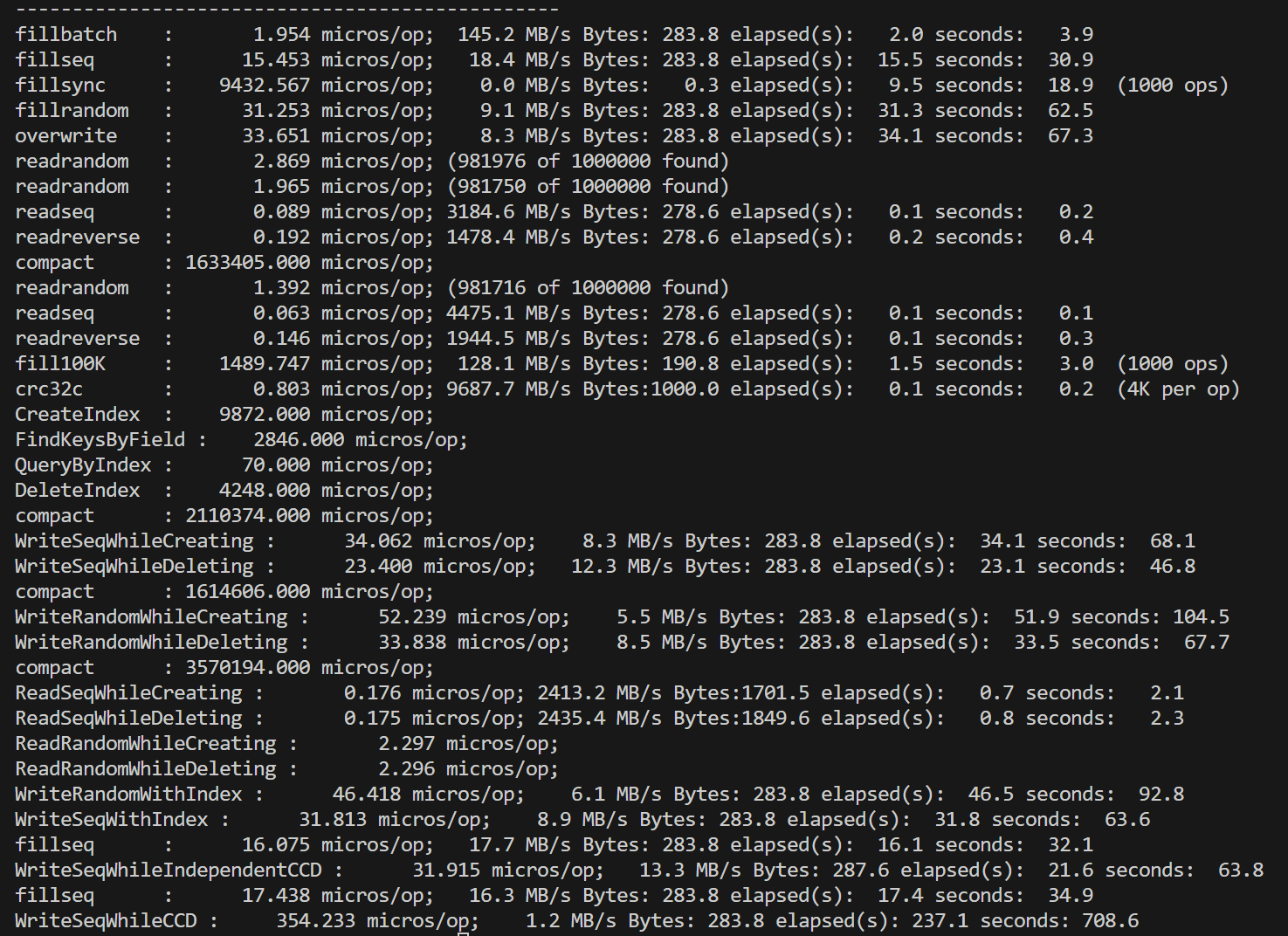
2. 对于FieldDB的分析 |
|
|
|
单线程 |
|
|
|
 |
|
|
|
双线程 |
|
|
|
 |
|
|
|
1) 所有涉及读取性能的:和原版leveldb相比,损耗非常少(一个必要的字段解析步骤),还是非常好的 |
|
|
|
2) 常规的写入性能:有所下降,但是由于需要支持索引功能,一些额外的开销无法避免(例如先读一遍,并发控制,一致性维护)。fillbatch的测试,基于我们合并请求和一段请求只处理一次同名key的算法,多线程性能甚至比单线程能够提高许多 |
|
|
|
 |
|
|
|
 |
|
|
|
其中单线程fillbatch差异比较明显。这里面的主要原因,一是因为leveldb本身这方面性能就非常优秀,二是因为在有索引功能的情况下,为了避免之前提到的问题,我们处理batch实际上还是需要把里面的每一条数据拆分出来,分别创建请求处理(而不是直接批量写入)。 |
|
|
|
这也反映在batchsize图中,我们的性能上升速率不如leveldb。但同样可观的上升速率意味着,我们的请求处理算法是有一定效果的。 |
|
|
|
3) 对于创删索引:没有比较对象,但是总体可以接受 |
|
|
|
4) 对于创删索引和写并发:如果是无关的,那么还是保持了高吞吐;如果是相关的,那么不得不受限于创删索引。考虑到数据库的创删索引请求还是比较少的(不太可能出现我们测试中,不停并发创删索引和写入的情况),一定的性能牺牲可以接受 |
|
|
|
|
|
|
|
## 4. 问题与解决 |
|
|
|
### 设计层面 |
|
|
|
1. 我们对并发的写入请求进行了合并,但在测试中发现了一个问题:之前提到,putfield和delete都需要先读一次原来的数据,但他们读不到合并在一起的请求中,之前的那个数据。这就导致了不一致(e.g. 将对于同一个key的putfield和delete请求合并,处理putfield时本次处理要写kv和index,处理delete时先读,发现数据库原来的数据中字段没有索引,于是删kv但没有删index)。我们的解决方式是,对于并发的写入只处理第一个相同的key。这同样提高了处理请求的效率。 |
|
|
|
|
|
|
|
1. 包装一层性能减半? |
|
|
|
|
|
|
|
2. |
|
|
|
### 一些调试较久的bug |
|
|
|
1. 测试部分srand、全局set多线程问题。 |
|
|
|
2. destroydb是全局的函数,而fielddb重新实现了一次。但在实际使用时忘记加fielddb的命名空间,导致调用了leveldb的destroy,而fielddb数据库一直没有正确删除。 |
|
|
|
3. 迭代器使用后忘记delete,导致版本一直没有unref。 |
|
|
|
4. 性能测试中创建索引时间慢于读,如果并发一个读和创会把创建的时间统计入读的时间。最后改为读线程一直循环读,直到创建完成后通知该线程结束。 |
|
|
|
|
|
|
|
## 5. 潜在优化点 |
|
|
|
1. 使用一些高性能并发设计模式,如reactor来优化多线程写入时由于锁竞争导致的性能问题 |
|
|
|
2. 采用一些高性能的库,如dpdk等 |
|
|
|
3. 使用一些基于polling的请求处理手段等 |
|
|
|
4. 对于各个log进行合并,减少写放大 |
|
|
|
4. 对于各个log进行合并,减少写放大 |
|
|
|
5. `GetHandleInterval`中选择一段request时,设置一个上限(综合考量max_batchsize和索引写入开销),和子数据库的批量写对齐。 |
|
|
|
6. 创删索引时会先产生中间结果,再向indexdb批量写。设置一个单次写的上限,分批次写入中间结果。 |
|
|
|
7. 涵盖复杂的数据库故障问题,比如硬件故障、恢复文件丢失等。 |
|
|
|
|
|
|
|
## 6. 分工 |
|
|
|
功能 | 完成日期 | 分工 |
|
|
|
:------|:---------|:------ |
|
|
|
value序列化、lab1功能实现|11.19|李度 |
|
|
|
fieldDb接口框架|11.25|陈胤遒 |
|
|
|
lab1整体+测试|11.30|李度、陈胤遒、高宇菲 |
|
|
|
fieldDb功能实现(没有并发和恢复)|12.10|李度、陈胤遒 |
|
|
|
并发框架|12.15|陈胤遒 |
|
|
|
lab2测试、并发完成|12.20|李度 |
|
|
|
恢复|12.25|李度、陈胤遒 |
|
|
|
整体系统整合+测试|12.28|李度、陈胤遒、高宇菲 |
|
|
|
性能测试|1.1|李度、陈胤遒、高宇菲 |

 cyq
8 months ago
cyq
8 months ago
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}