
 augurier
пре 8 месеци
augurier
пре 8 месеци
3 измењених фајлова са 5 додато и 1 уклоњено
+ 5
- 1
README.md
Прегледај датотеку
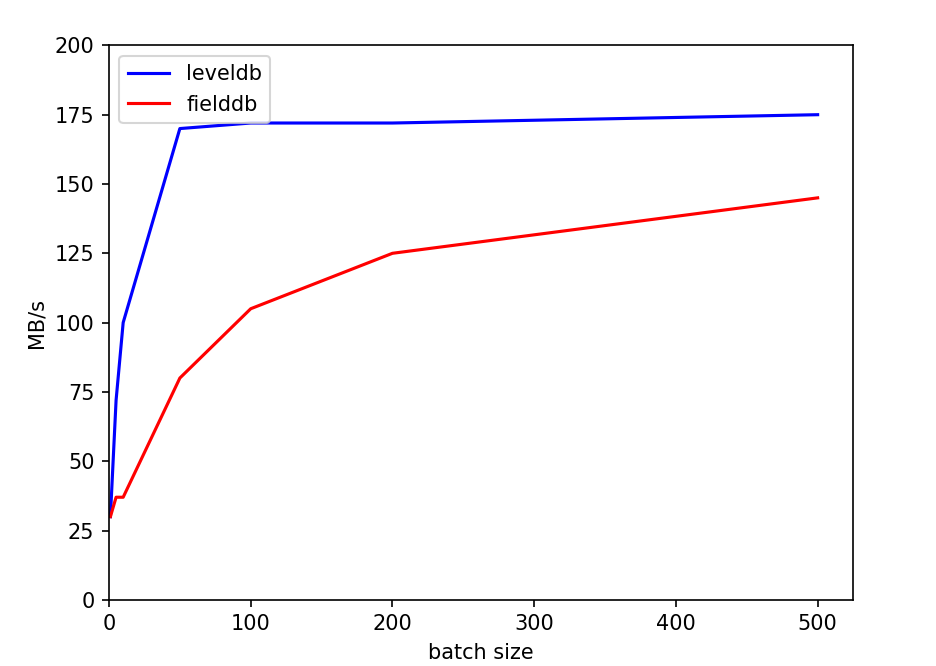
BIN
pics/f_bsize.png
Прегледај датотеку
{kind=link}
| Before | After |
|---|---|
|
|
| Width: 936 | Height: 666 | Size: 34 KiB |
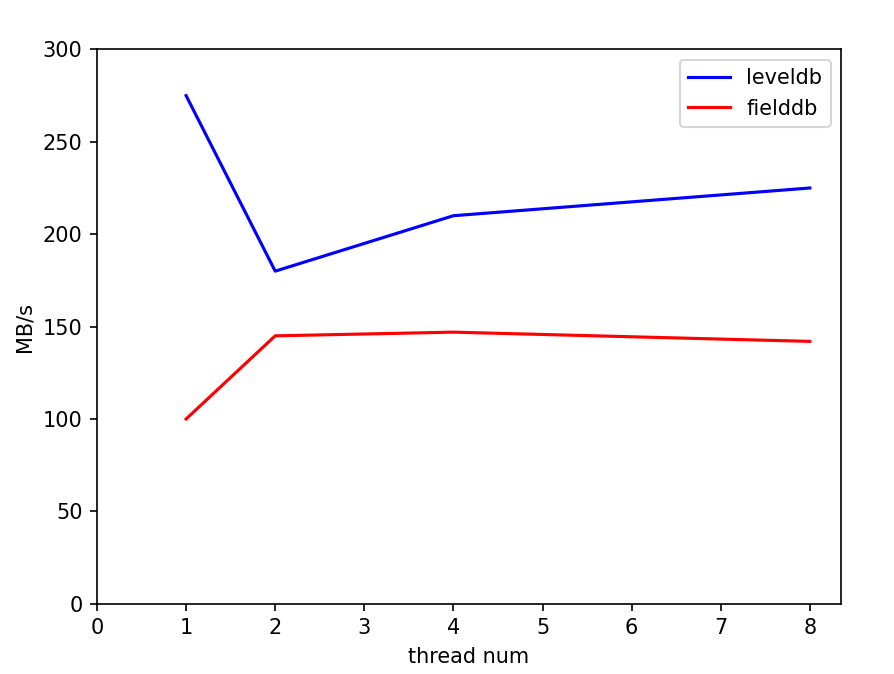
BIN
pics/f_thread.png
Прегледај датотеку
{kind=link}
| Before | After |
|---|---|
|
|
| Width: 894 | Height: 674 | Size: 28 KiB |
Loading…