
46 KiB
LevelDB设计文档
王雪飞,马也驰1.项目概述及目标
1.1 项目概述
本项目的背景是提升 LevelDB 在高写入负载场景下的性能。LevelDB 是一种轻量级的键值存储引擎,但在数据频繁更新或大值(Large Values)存储场景下,由于数据写入和合并(Compaction)过程的设计,其性能可能受到显著影响。为解决这一问题,项目目标是实现 KV(Key-Value)分离机制,以降低写放大现象并提高存储效率。
具体实现内容包括在 LevelDB 内部引入 KV 分离功能,即将键(Key)与值(Value)存储到不同的存储介质中。通过修改 SSTable 的结构设计,将键与指向值的指针存储在原有的文件中,而将实际值存储到单独的文件或存储介质中,从而减少 Compaction 操作对大值的处理负担。此外,项目还优化了数据访问逻辑,实现了值文件的高效读写支持。
该功能的应用场景主要包括:
- 适用于大值写入频繁的场景,如日志存储、视频元数据管理等。
- 提升 SSD 等固态存储设备的寿命,减少写入放大带来的磨损。
- 在混合存储架构中,提高冷热数据分离的效率。
1.2 项目目标
本项目涵盖下面三个方面:
- 实验一:在 LevelDB 的 value 中实现字段功能。
- 实验二:实现 KV 分离。
- 实验三:实现 Benchmark,测试并分析性能。
2. 实验内容
2.1 在 LevelDB 的 value 中实现字段功能
具体指:基于 levelDB扩展 value 的结构,使其可以包含多个字段,并通过这些字段实现类似数据库列查询的功能。
2.1.1 实验要求:
- 字段存储:
- 将 LevelDB 中的 value 组织成字段数组,每个数组元素对应一个字段(字段名:字段值)。
- 字段会被序列化为字符串,然后插入LevelDB。
- 这些字段可以通过解析字符串得到,字段名与字段值都是字符串类型。
- 允许任意调整字段。
- 查询功能:
- 实现通过字段值查询对应的 key。
2.1.2 实验内容
- 数据存储与解析: 每个 value 存储为一个字符串数组,数组中的每个元素代表一个字段。
using Field = std::pair<std::string, std::string>; // field_name:field_value
using FieldArray = std::vector<std::pair<std::string, std::string>>;
编码函数:
void DBImpl::SerializeValue(const FieldArray& fields, std::string &value)
功能: 将传入的字段数组序列化为字符串,并存到 value
字符串形式:
single value: || value_size(uint16_t) | slot_num(size_t) || {field_nums(uint16_t), attr1, attr2, ... } |
single attr: | attr1_name_len(uint8_t) | attr1_name | attr1_len(uint16_t) | attr1 |
输入: 字段数组, slot_num, &value
具体实现如下:
void DBImpl::SerializeValue(const FieldArray& fields, std::string &value) {
// 先构建 slot_num 之后的字符串,存到 tmp_value 中
std::string tmp_value;
// slot_num 之后的总长度
uint16_t value_size = sizeof(uint16_t);
// 字段数目
uint16_t field_nums = 0;
// 遍历所有字段
for (const auto& field : fields) {
// 字段名的长度
const uint8_t attr_name_len = field.name.size();
// 字段属性的长度
const uint16_t attr_value_len = field.value.size();
const size_t attr_size = attr_name_len + attr_value_len + sizeof(uint8_t) + sizeof(uint16_t);
// 用 attr_data 存放:字段名长度 + 字段名 + 字段属性长度 + 字段属性
char attr_data[attr_size];
size_t off = 0;
memcpy(attr_data+off, &attr_name_len, sizeof(uint8_t));
off += sizeof(uint8_t);
memcpy(attr_data+off, field.name.c_str(), attr_name_len);
off += attr_name_len;
memcpy(attr_data+off, &attr_value_len, sizeof(uint16_t));
off += sizeof(uint16_t);
memcpy(attr_data+off, field.value.c_str(), attr_value_len);
off += attr_value_len;
assert(off == attr_size);
// 将 attr_data 添加到 tmp_value 中
tmp_value += std::string(attr_data, attr_size);
// 更新总长度和字段数目
value_size += attr_size;
field_nums ++;
}
// value_data 存放完整的字符串
char value_data[value_size];
// 将 value_size 添加到 value_data 中
memcpy(value_data, &value_size, sizeof(uint16_t));
// 将 tmp_value 添加到 value_data 中
memcpy(value_data+sizeof(uint16_t), tmp_value.c_str(), tmp_value.size());
assert(sizeof(uint16_t) + tmp_value.size() == value_size);
value = std::string(value_data, value_size);
}
解码函数:
void DBImpl::DeserializeValue(FieldArray& fields, const std::string& value_str)
功能: 将传入的待解码字符串反序列化为字段数组并存到 fields
字符串形式:
single value: || value_size(uint16_t) | slot_num(size_t) || {field_nums(uint16_t), attr1, attr2, ... } |
single attr: | attr1_name_len(uint8_t) | attr1_name | attr1_len(uint16_t) | attr1 |
输入: 存放解码结果的字段数组,待解码的字符串
具体实现如下:
void DBImpl::DeserializeValue(FieldArray& fields, const std::string& value_str) {
const char *value_data = value_str.c_str();
// value_len 为 value 的长度
const size_t value_len = value_str.size();
// 最前面为 value_size,大小为 uint16_t
size_t attr_off = sizeof(uint16_t);
// 当偏移小于 value 的长度时,继续解码
while (attr_off < value_len) {
// 下面的步骤为:读取属性后加偏移
// 读属性名长度,加偏移
uint8_t attr_name_len = *(uint8_t *)(value_data+attr_off);
attr_off += sizeof(uint8_t);
// 读属性名,加偏移
auto attr_name = std::string(value_data+attr_off, attr_name_len);
attr_off += attr_name_len;
// 读属性长度,加偏移
uint16_t attr_len = *(uint16_t *)(value_data+attr_off);
attr_off += sizeof(uint16_t);
// 读属性值,加偏移
auto attr_value = std::string(value_data+attr_off, attr_len);
attr_off += attr_len;
// 将 属性名 和 属性 添加到 fields 中
fields.push_back({attr_name, attr_value});
}
assert(attr_off == value_len);
}
- 通过字段查询 Key: 实现函数 FindKeysByField,传入字段名和字段的值就可以找到对应的key
std::vector<std::string> FindKeysByField(leveldb::DB* db, const Field& field)
功能: 根据传入的字段值 field 查找所有包含该字段的 key,由于一个字段值可能对应多个key,所以返回std::vector<std::string>
具体实现如下:
std::vector<std::string> FindKeysByField(leveldb::DB* db, const Field& field) {
std::vector<std::string> keys;
// 遍历数据库中所有的 KV 对
leveldb::Iterator* it = db->NewIterator(leveldb::ReadOptions());
for (it->SeekToFirst(); it->Valid() ; it->Next()) {
std::string key = it->key().ToString();
FieldArray fields;
// 调用 Get_Fields 函数,获取 key 对应的字段数组
db->Get_Fields(leveldb::ReadOptions(), key, fields);
// 遍历字段数组,如果字段数组中包含该字段,则将该 key 添加到 keys 中
for (const auto& f : fields) {
if (f.name == field.name && f.value == field.value) {
keys.push_back(key);
break; // 假设每个key中每个字段值唯一
}
}
}
delete it;
return keys;
}
2.2 KV分离
在LevelDB中实现KV分离,即将键值对中的键和值存储在不同的存储区域,以优化写性能和点查询性能。
2.2.1 实验要求
- KV 分离设计
- a. 将LevelDB的key-value存储结构进行扩展,分离存储key和value
- b. Key存储在一个LevelDB实例中,LSM-tree中的value为一个指向Value log文件和偏移地址的指针,用户Value存储在Value log中。
- 读取操作
- a. KV分离后依然支持点查询与范围查询操作。
- value_log 的管理
- a. 当Value log超过一定大小后通过后台GC操作释放Value log中的无效数据。
- b. GC能把旧Value log中没有失效的数据写入新的Value log,并更新LSM-tree里的键值对。
- c. 新旧Value log的管理功能。
- 确保操作的原子性
2.2.2 实验内容
-
- 不改变LevelDB原有的接口,实现KV分离。
-
- 编写测试点验证KV分离是否正确实现。
设计思路:
- value的分离式存储 我们使用若干个vlog文件,为每一个vlog文件设置容量上限,并在内存中为每一个vlog维护一个discard计数器,表示这个vlog中当前有多少value已经在lsm tree中被标记为删除。
- 存储value所在vlog和偏移量的元数据 我们在 memtable 和vlog中添加一个slot_page的中间层,这一层存储每一个key对应的value所在的vlog文件和文件内偏移,而lsm tree中的key包含的实际上是这个中间层的slot下标,而每一个slot中存储的是key所对应的vlog文件号以及value在vlog中的偏移。这样,我们就可以在不修改lsm tree的基础上,完成对vlog的compaction,并将vlog的gc结果只反映在这个中间层slot_page中。这个slot_page实际上也是一个线性增长的log文件,作用类似于os中的页表,负责维护lsm tree中存储的slot下标到vlog和vlog内偏移量的一个映射。这样,通过slot_page我们就可以找到具体的vlog文件和其文件内偏移量。对于vlog的GC过程,我们不需要修改lsm tree中的内容,我们只需要修改slot_page中的映射即可。
- slot_page文件和vlog文件的GC 对于vlog文件,我们在内存中维护一个bitmap,用来表示每一个slot的使用情况,并在插入和GC删除kv时进行动态的分配和释放。对于vlog文件的GC,我们用一个后台线程来扫描所有vlog的discard计数器。当某些vlog的discard计数器超过某个阈值(比如1024),我们就对这些vlog文件进行GC过程,当GC完成之后将slot_page中的slot元数据进行更新,再将原来的vlog文件进行删除,GC过程就完成了。
相关代码文件
/db/db_impl.cc: 修改函数 DBImpl::Get, DBImpl::Put 和 DBImpl::Delete,添加函数 Put_fields, Get_fields, get_slot_num,SerializeValue, DeserializeValue/db/db_impl.h: 添加相关结构体和函数声明/db/shared_lock.h: 定义了一个 SharedLock 类,用于实现读写锁机制。该类支持两种锁模式:软锁(soft_lock/soft_unlock)和硬锁(hard_lock/hard_unlock);/db/slotpage.h:
- 定义了 slot_content 结构体:
struct slot_content {
uint32_t vlog_num;
uint32_t value_offset;
slot_content() {}
slot_content(uint32_t vn, uint32_t vo) {
vlog_num = vn;
value_offset = vo;
}
};
- 定义了 SlotCache 类,类中函数:get_slot, set_slot, read_slot, set_slot;
- 定义了 BitMap 类,类中函数: dealloc_slot, alloc_slot, alloc_new_bitmap;
- 定义了 Slot_page 类,类中函数: get_slot, set_slot, alloc_slot, dealloc_slot
- 定义了 vlog_info 结构体(存放 value_log 的相关信息):
struct vlog_info {
std::mutex vlog_info_latch_; // 保护对vlog_info本身的并发修改
size_t vlog_num;
size_t vlog_num_for_gc; // set when start gc
bool processing_gc;; // init to be false, set as true when processing gc
bool vlog_valid_; // init to be true, set as false after deleted
size_t discard;
size_t value_nums;
size_t curr_size;
vlog_info(size_t vlog_num) : processing_gc(false), discard(0), value_nums(0),
vlog_num(vlog_num), curr_size(2*sizeof(size_t)), vlog_valid_(true) {}
vlog_info(size_t vlog_num, size_t value_nums, size_t curr_size) : processing_gc(false),
discard(0), value_nums(value_nums),
vlog_num(vlog_num), curr_size(curr_size),
vlog_valid_(true) {}
};
- 定义了 vlog_handler 结构体:
struct vlog_handler {
std::mutex vlog_handler_latch_;
size_t curr_access_thread_nums;
SharedLock vlog_latch_; // 表明当前vlog上的并发情况,读上soft_lock,写上hard_lock
vlog_handler() : curr_access_thread_nums(0) {}
inline void incre_access_thread_nums() {
vlog_handler_latch_.lock();
curr_access_thread_nums ++;
vlog_handler_latch_.unlock();
}
inline void decre_access_thread_nums() {
vlog_handler_latch_.lock();
curr_access_thread_nums --;
vlog_handler_latch_.unlock();
}
inline bool non_access_thread() {
bool flag = false;
vlog_handler_latch_.lock();
if (!curr_access_thread_nums) {
flag = true;
}
vlog_handler_latch_.unlock();
return flag;
}
};
定义 VlogGC 类,声明类中函数
- 定义了 executor_param 结构体:
struct executor_param {
VlogGC *vg;
size_t old_vlog_num;
size_t new_vlog_num;
};
- 实现 vlog_gc 中声明的函数
/db/vlog_set.h(用于管理 vlog): 定义 VlogSet 结构体/db/vlog_set.cpp: 实现 vlog_set 中的函数/db/vlog_cache.h:
- 定义结构体:frame_info, block_frame
- 定义类 VlogCache
/db/vlog_cache.cpp:实现 vlog_cache 中的函数CMakeLists.txt:添加可执行文件
数据结构设计:
sstable 中:| key | slot_num |
slot_page 中: | slot0:{vlog_no(定长), offset(定长)}, slot1:{vlog_no, offset}, ... |
value_log 中:|value 长度 | slot_num | attr个数(定长) | attr1_name的长度(定长) | attr1_name(变长) | attr1_value的长度(定长) | attr1_value(变长) | ... |
写操作:
Status DBImpl::Put_Fields(const WriteOptions& opt, const Slice& key, const FieldArray& fields)
流程图:
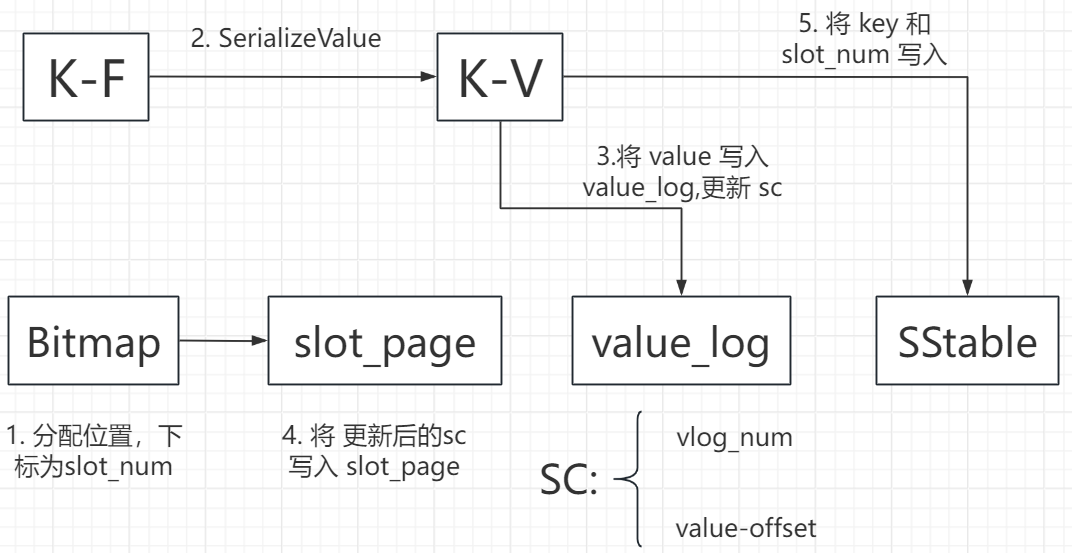 功能:
功能:
将传入的字段数组插入数据库中
步骤:
- 在 bit_map 中分配一个空闲位置;
- 调用 SerializeValue 函数将字段数组序列化为字符串 serialized_value;
- 调用 put_value 函数,将字符串 serialized_value 写入 vlog 中;
- 调用 set_slot 函数,将 sc 写入缓存中;
- 将 slot_num 作为 value 写入数据库中。
代码实现:
Status DBImpl::Put_Fields(const WriteOptions& opt, const Slice& key,
const FieldArray& fields) {
std::string serialized_value;
// alloc_slot 函数作用:分配一个 slot_num
size_t slot_num = slot_page_->alloc_slot();
// SerializeValue 函数作用:将字段数组序列化为字符串 serialized_value
SerializeValue(fields, serialized_value, slot_num);
// 实例化 slot_content 结构体 sc
struct slot_content sc;
// put_value函数作用:将序列化后的字符串 serialized_value 插入 value_log 中
vlog_set_->put_value(sc, slot_num, serialized_value);
// set_slot函数作用: 将 sc 写入内存中
slot_page_->set_slot(slot_num, &sc);
// 将 slot_num 作为 value 插入 sstable 中
char data[sizeof(size_t)];
memcpy(data, &slot_num, sizeof(size_t));
Slice slot_val(data, sizeof(data));
return DB::Put(opt, key, slot_val);
}
size_t alloc_slot()
功能: 在 bitmap 中分配一个空闲的槽位
实现步骤:
- 获取互斥锁;
- 判断当前 bitmap 是否有空闲槽位,就是遍历 bitmap,找到第一个为 0 的位,然后设置该位为 1,返回该位对应的 slot_num。
具体实现如下:
size_t alloc_slot() {
// 获取互斥锁
mtx.lock();
size_t target_slot = first_empty_slot;
char *start_byte = get_bitmap_byte(slot2byte(first_empty_slot));
const size_t off = slot2offset(first_empty_slot);
SETBIT(start_byte, off);
// find the next free slot
if (HASFREESLOT(*start_byte)) {
auto bit_off = find_first_free_slot_inbyte(*start_byte);
first_empty_slot += bit_off - off;
if (slot2byte(first_empty_slot) >= size) {
alloc_new_bitmap();
}
} else {
size_t i;
for (i = slot2byte(first_empty_slot)+1; i < size; i++) {
char *byte = get_bitmap_byte(i);
if (HASFREESLOT(*byte)) {
// FIXME: pack four bytes to do free slot finding
auto bit_off = find_first_free_slot_inbyte(*byte);
first_empty_slot = byte2slot(i) + bit_off;
break;
}
}
// scale the bitmap
if (i >= size) {
alloc_new_bitmap();
// char *byte = get_bitmap_byte(i);
// SETBIT(byte, 0);
first_empty_slot = byte2slot(i) + 1;
}
}
mtx.unlock();
return target_slot;
}
void set_slot(size_t slot_num, struct slot_content *sc)
功能: 将 sc 写入缓存块中,缓存块与 bitmap 有对应关系
实现步骤:
- 计算块编号:通过 slotnum_hash2_blocknum 函数将槽位编号转换为块编号
- 确定缓存块位置:使用块编号对 BLOCK_NUM 取模,得到缓存块的位置
- 加锁:对目标缓存块加锁以确保线程安全
- 检查和更新缓存块
- 设置槽位内容:调用 set_slot 函数设置槽位内容
- 更新访问时间和脏标志:增加访问时间并标记为脏数据
- 解锁:释放锁
具体实现如下:
void set_slot(size_t slot_num, struct slot_content *sc) {
auto block_num = slotnum_hash2_blocknum(slot_num);
auto blockcache_num = block_num % BLOCK_NUM;
latches_[blockcache_num].lock();
if (!info[blockcache_num].used || info[blockcache_num].block_num != block_num) {
if (info[blockcache_num].is_dirty) {
write_back_block(blockcache_num);
}
read_in_block(blockcache_num, block_num);
access_time[blockcache_num] = 0;
info[blockcache_num] = block_info(block_num, false, true);
}
set_slot(sc, blockcache_num, SLOT_OFFSET_IN_BLOCK(slot_num));
access_time[blockcache_num]++;
info[blockcache_num].is_dirty = true;
latches_[blockcache_num].unlock();
}
void VlogSet::put_value(struct slot_content &sc, size_t slot_num, const leveldb::Slice &value)
功能: 做前期准备,并调用 write_vlog_value 将序列化后的字符串 serialized_value 插入 value_log 中
实现步骤:
- 获取互斥锁;
- 根据值的大小获取可写入的vlog信息;
- 锁定 vlog 信息,更新 slot_content 内容;
- 更新 vlog 内容,包括当前大小 curr_size 和存储的 value 个数;
- 根据 vlog 编号获取 vlog 处理器;
- 如果 vlog 无效或者正在进行GC,则使用 vlog_num_for_gc;
- 调用 write_vlog_value 函数,将字符串 serialized_value 写入 vlog 中
具体实现如下:
void VlogSet::put_value(struct slot_content &sc, size_t slot_num, const leveldb::Slice &value) {
mtx.lock();
// 根据值的大小获取可写入的vlog信息
auto vinfo = get_writable_vlog_info(value.size());
if (!vinfo) {
// vlog全部已满,创建新的vlog
auto _vlog_num_ = register_new_vlog();
vinfo = get_vlog_info(_vlog_num_);
}
// 锁定 vlog 信息,更新 slot_content 内容
vinfo->vlog_info_latch_.lock();
sc.vlog_num = vinfo->vlog_num;
sc.value_offset = vinfo->curr_size;
// 更新 vlog 内容,包括当前大小 curr_size 和存储的 value 个数
vinfo->curr_size += value.size() + sizeof(uint16_t) + sizeof(size_t);
vinfo->value_nums ++;
// 根据 vlog 编号获取 vlog 处理器
auto vhandler = get_vlog_handler(vinfo->vlog_num);
// 如果 vlog 无效或者正在进行GC,则使用 vlog_num_for_gc
if (!vinfo->vlog_valid_ || vinfo->processing_gc) {
vhandler = get_vlog_handler(vinfo->vlog_num_for_gc);
}
// 加锁
vhandler->vlog_latch_.hard_lock();
// 增加访问线程数
vhandler->incre_access_thread_nums(); // FIXME: increase thread nums
mtx.unlock(); // for better performance
// vlog 信息写入完毕,解锁
vinfo->vlog_info_latch_.unlock();
// write_vlog_value 函数功能:将字符串 serialized_value 写入 vlog 中
write_vlog_value(sc, slot_num, value);
// 写入完毕,减少访问线程数
vhandler->decre_access_thread_nums(); // FIXME: decrease thread nums
// 解锁
vhandler->vlog_latch_.hard_unlock();
}
void VlogSet::write_vlog_value(const struct slot_content &sc, size_t slot_num, const leveldb::Slice &value)
功能: 将字符串 value 写入 vlog 中
实现步骤:
- 获取 vlog 名称;
- 打开 vlog 文件;
- 定位写入位置;
- 构造要写入的数据;
- 写入数据。
具体实现如下:
void VlogSet::write_vlog_value(const struct slot_content &sc, size_t slot_num, const leveldb::Slice &value) {
// 函数 get_vlog_name 作用:获取 slot_content 中 vlog_num 对应的 vlog 名称
auto vlog_name = get_vlog_name(sc.vlog_num);
// 打开文件:使用 fstream 打开文件,确保文件以读写模式打开
auto handler = std::fstream(vlog_name, std::ios::in | std::ios::out);
// 定位写入位置:通过 seekp 方法将文件指针移动到 slot_content 中的 value_offset 位置
handler.seekp(sc.value_offset);
// 准备数据:构造要写入的数据,包括值大小(uint16_t)、slot_num(size_t)和实际值内容(Slice)
const char *value_buff = value.data();
const size_t off = sizeof(uint16_t) + sizeof(size_t);
const size_t value_size = off + value.size();
char data[value_size];
memcpy(data, &value_size, sizeof(uint16_t));
memcpy(data+sizeof(uint16_t), &slot_num, sizeof(size_t));
memcpy(data+off, value_buff, value.size());
handler.write(data, value_size);
// 刷新缓冲区:调用 flush 方法确保数据写入磁盘
handler.flush();
// 关闭文件
handler.close();
}
Status DBImpl::Get_Fields(const ReadOptions& options, const Slice& key,FieldArray& fields)
功能: 从数据库中读取 key 对应的字段数组并存放到 fields 中
实现步骤:
- 读取 key 对应的 slot_num
- 调用 get_slot 函数,根据 slot_num 从 slot_page 中获取 slot_content
- 调用 get_value 函数,从 vlog 中读取字符串
- 将字符串解码得到 value
代码实现:
Status DBImpl::Get_Fields(const ReadOptions& options, const Slice& key,
FieldArray& fields) {
size_t slot_num;
// get_slot_num 函数作用:从 memtable 中读取 key 对应的 slot_num
auto s = get_slot_num(options, key, &slot_num);
if (!s.ok()) {
return s;
}
struct slot_content sc;
std::string vlog_value;
// get_slot 函数作用:根据 slot_num 从缓存中获取 slot_content,并存放到 sc 中
slot_page_->get_slot(slot_num, &sc);
// get_value 函数作用:根据 sc 中的信息,从 value_log 中读取字符串并存放到 vlog_value
vlog_set_->get_value(sc, &vlog_value);
if (vlog_value.empty()) {
return Status::NotFound("value has been deleted");
}
// 调用 DeserializeValue 函数,将 vlog_value 解码为字段数组 fields
DeserializeValue(fields, vlog_value);
return Status::OK();
}
void get_slot(size_t slot_num, struct slot_content *sc)
功能: 获取 slot_num 对应的 slot_content 并存放到 sc 中
实现步骤:
- 计算块编号:根据槽位号计算出对应的块编号。
- 锁定缓存块:通过哈希计算确定缓存块编号,并加锁以确保线程安全。
- 检查缓存命中:如果缓存未使用或块编号不匹配,则处理缓存未命中情况。
- 写回脏数据:如果缓存块是脏数据,先将其写回磁盘。
- 读取新块:从磁盘读取新的块到缓存,并更新访问时间和块信息。
- 读取槽位内容:从缓存块中读取指定槽位的内容。
- 解锁缓存块:操作完成后解锁。
具体实现如下:
void get_slot(size_t slot_num, struct slot_content *sc) {
auto block_num = slotnum_hash2_blocknum(slot_num);
auto blockcache_num = block_num % BLOCK_NUM;
latches_[blockcache_num].lock();
if (!info[blockcache_num].used || info[blockcache_num].block_num != block_num) { // cache miss
if (info[blockcache_num].is_dirty) {
write_back_block(blockcache_num);
}
read_in_block(blockcache_num, block_num);
access_time[blockcache_num] = 0;
info[blockcache_num] = block_info(block_num, false, true);
}
read_slot(sc, blockcache_num, SLOT_OFFSET_IN_BLOCK(slot_num));
access_time[blockcache_num]++;
latches_[blockcache_num].unlock();
}
void VlogSet::get_value(const struct slot_content &sc, std::string *value)
功能: 做准备工作,并调用 read_vlog_value 函数从 vlog 中读取字符串
实现步骤:
- 根据 sc.vlog_num 获取 vinfo 和 vlog_handler;
- 加 vlog 信息锁;
- 根据 vinfo 中的信息检查 vlog 是否有效;
- 调用 read_vlog_value 函数,根据 sc 中的 vlog_num 和 value_offset 从 vlog 中读取字符串 具体实现如下:
void VlogSet::get_value(const struct slot_content &sc, std::string *value) {
// 获取互斥锁
mtx.lock();
// get_vlog_info 函数作用:根据 sc 中的 vlog_num 获取 vlog_info
auto vinfo = get_vlog_info(sc.vlog_num);
// get_vlog_handler 函数作用:根据 sc 中的 vlog_num 获取 vlog_handler
auto vhandler = get_vlog_handler(sc.vlog_num);
// 加 vlog 信息锁
vinfo->vlog_info_latch_.lock();
// 根据 vinfo 检查 vlog 是否有效
if (!vinfo->vlog_valid_) {
// 如果无效,则进行垃圾处理
vhandler = get_vlog_handler(vinfo->vlog_num_for_gc);
}
// 加锁
vhandler->vlog_latch_.soft_lock();
// 增加访问线程数
vhandler->incre_access_thread_nums(); // FIXME: increase thread nums
// 释放互斥锁和 vlog 信息锁
mtx.unlock(); // for better performance
vinfo->vlog_info_latch_.unlock();
// read_vlog_value 函数作用:根据 sc 中的 vlog_num 和 value_offset 从 vlog 中读取字符串
read_vlog_value(sc, value);
// 减少访问线程数
vhandler->decre_access_thread_nums(); // FIXME: decrease thread nums
// 释放 vlog 锁
vhandler->vlog_latch_.soft_unlock();
}
void VlogSet::read_vlog_value(const struct slot_content &sc, std::string *value)
功能: 根据 sc 中的 vlog_num 和 value_offset 从 vlog 中读取字符串并存放到 value
实现步骤:
- 获取 vlog 文件名;
- 打开 vlog 文件;
- 定位文件指针到 value_offset 指定的位置;
- 读取固定大小的数据到缓冲区 value_buff;
- 从缓冲区中提取 value 的大小,value_size 字段设置了标志位,用于检查是否被标记为删除, 如果被标记为删除,则将结果字符串设置为空并返回;
- 计算实际值的大小并从缓冲区中提取值,存储到结果字符串中
具体实现如下:
void VlogSet::read_vlog_value(const struct slot_content &sc, std::string *value) {
// 根据 sc 中的 vlog_num 获取 vlog 文件名
auto vlog_name = get_vlog_name(sc.vlog_num);
// 打开 vlog 文件
auto handler = std::fstream(vlog_name, std::ios::in | std::ios::out);
// 使用 seekp 方法将文件指针定位到 value_offset 指定的位置
handler.seekp(sc.value_offset);
// 从文件中读取固定大小的数据到缓冲区 value_buff
char value_buff[VALUE_BUFF_SIZE];
handler.read(value_buff, VALUE_BUFF_SIZE);
// 从缓冲区中提取值的大小,并检查是否被标记为删除
uint16_t value_size;
memcpy(&value_size, value_buff, sizeof(uint16_t));
// 如果值带有删除标记,则将结果字符串设置为空并返回
if (value_size & VALUE_DELE_MASK) {
*value = "";
return ;
}
// 计算实际值的大小并从缓冲区中提取值,存储到结果字符串中
value_size &= VALUE_SIZE_MASK;
assert(value_size <= VALUE_BUFF_SIZE);
const size_t off = sizeof(uint16_t)+sizeof(size_t);
// 减去 off 的长度,只读取出 value 中实际存放属性的部分
*value = std::string(&value_buff[off], value_size-off);
// 关闭文件
handler.close();
}
Status DBImpl::Delete(const WriteOptions& options, const Slice& key)
功能: 删除 key 对应的条目
步骤:
- 获取 key 对应的 slot_num;
- 获取 slot_num 对应的 slot_content;
- 删除 vlog 中 slot_content 对应的条目;
- 释放 slot_num 中对应的 slot_content;
- 删除 k-v对。
代码实现:
Status DBImpl::Delete(const WriteOptions& options, const Slice& key) {
size_t slot_num;
// get_slot_num 函数的作用: 获取 key 对应的 slot_num
auto s = get_slot_num(ReadOptions(), key, &slot_num);
if (!s.ok()) {
return s;
}
struct slot_content sc;
// get_slot 函数作用: 获取 slot_num 对应的 slot_content
slot_page_->get_slot(slot_num, &sc);
// del_value 函数作用:删除 vlog 中 slot_content 对应的 value
vlog_set_->del_value(sc);
// dealloc_slot 函数作用: 释放 slot_num
slot_page_->dealloc_slot(slot_num);
return DB::Delete(options, key);
}
void VlogSet::del_value(const struct slot_content &sc)
功能: 做准备工作,调用 mark_del_value 删除 vlog 中的条目
实现步骤:
- 加锁:使用互斥锁 mtx 确保线程安全。
- 获取信息:通过 sc.vlog_num 获取对应的 vlog 信息和处理器。
- 检查状态:如果 vlog 无效或正在处理垃圾回收,则更新处理器为垃圾回收的 vlog。
- 加锁并增加访问计数:对 vlog 处理器加锁,并增加访问线程数。
- 解锁:释放互斥锁和 vlog 信息锁。
- 标记删除:调用 mark_del_value 标记并进行删除操作。
- 减少访问计数并解锁:减少访问线程数并解锁 vlog
具体实现如下:
void VlogSet::del_value(const struct slot_content &sc) {
mtx.lock();
auto vinfo = get_vlog_info(sc.vlog_num);
auto vhandler = get_vlog_handler(sc.vlog_num);
vinfo->vlog_info_latch_.lock();
if (!vinfo->vlog_valid_ || vinfo->processing_gc) {
vhandler = get_vlog_handler(vinfo->vlog_num_for_gc);
}
vhandler->vlog_latch_.hard_lock();
vhandler->incre_access_thread_nums(); // FIXME: increase thread nums
mtx.unlock(); // for better performance
vinfo->vlog_info_latch_.unlock();
mark_del_value(sc);
vhandler->decre_access_thread_nums(); // FIXME: decrease thread nums
vhandler->vlog_latch_.hard_unlock();
}
void VlogSet::mark_del_value(const struct slot_content &sc)
功能: 标记 slot_content 对应的条目为删除并判断是否需要调用 GC,如果需要,调用do_gc
实现步骤:
- 根据 sc.vlog_num 获取 vlog 文件信息;
- 调用 delete_vlog_value 函数删除 vlog 中的条目,并返回被删除的日志项的大小;
- 更新信息;
- 判断是否需要 GC
具体实现如下:
void VlogSet::mark_del_value(const struct slot_content &sc) {
// 根据 sc.vlog_num 获取 vlog 文件信息
auto vinfo = get_vlog_info(sc.vlog_num);
// 调用 delete_vlog_value 函数删除 vlog 中的条目,并返回被删除的项的大小
auto value_size = delete_vlog_value(sc);
// handle gc, mtx is locked outside, vlog_info_latch and vlog hard lock is locked outside too
// 更新统计信息,包括 增加丢弃计数 discard, 减少值的数量 value_nums, 减少当前大小 curr_size,减去被删除的日志项的大小 value_size
vinfo->discard ++;
vinfo->value_nums --;
vinfo->curr_size -= value_size;
// FIXME: gc process, avoid repeated gc
// 判断是否需要触发垃圾回收
if (vlog_need_gc(sc.vlog_num) && !vinfo->processing_gc) {
// create new vlog
vinfo->processing_gc = true;
// 分配一个新的 vlog
vinfo->vlog_num_for_gc = register_new_vlog();
// 启动垃圾回收过程
vlog_gc->do_gc(sc.vlog_num, vinfo->vlog_num_for_gc);
}
}
void VlogGC::do_gc(size_t old_vlog_num, size_t new_vlog_num)
功能: 做 GC 的前期准备,并启动垃圾回收过程
实现步骤:
- 首先检查 old_vlog_num 是否正在进行GC,如果是则直接返回;否则将其标记为正在GC;
- 增加全局GC计数器,并获取当前的GC编号;
- 准备执行参数:创建一个结构体 executor_param,包含当前对象指针、旧日志编号和新日志编号;
- 添加执行参数和GC记录:将上述参数和当前对象添加到执行器参数列表和GC记录中;
- 启动GC线程:创建并启动一个独立线程来执行GC任务。该线程会调用exec_gc方法进行实际的GC操作,并在完成后减少全局GC计数器;
- 分离线程:将线程分离,使其独立运行。
具体实现如下:
void VlogGC::do_gc(size_t old_vlog_num, size_t new_vlog_num) {
// 判断旧的 vlog 是否正在进行gc,如果是,直接返回
if (vlog_in_gc(old_vlog_num)) {
return ;
}
// 否则将当前old_vlog_num设置为正在gc
add_vlog_in_gc(old_vlog_num);
// 增加全局GC计数器,并获取当前的GC编号
gc_counter_increment();
size_t _gc_num_ = get_gc_num();
// 创建一个结构体 executor_param,包含当前对象指针、旧日志编号和新日志编号
struct executor_param ep = {this, old_vlog_num, new_vlog_num};
add_executor_params(_gc_num_, ep);
add_vlog_gc(_gc_num_, this);
// FIXME: 线程的信息必须被保存在函数栈之外,否则函数栈销毁之后,线程会报错exc_bad_access, 这里需要有一个gc_hanlder线程一直运行并处理各个gc请求
std::thread gc_thread([_gc_num_, this]() mutable {
auto _vlog_gc_ = get_vlog_gc(_gc_num_);
assert(_vlog_gc_ != nullptr);
_vlog_gc_->exec_gc(_gc_num_);
gc_counter_decrement();
});
gc_thread.detach();
}
void VlogGC::exec_gc(size_t gc_num_)
功能: GC 相关线程调度,并执行GC任务
实现步骤:
- 增加当前线程数量,并判断是否需要等待其他线程完成GC任务;
- 获取执行参数,包括 GC编号、旧日志编号和新日志编号;
- 调用 gc_executor::exec_gc 方法开始执行GC任务;
- 检查当前线程数是否仍然大于等于最大线程数;
- 减少线程数;
- 清理资源。 具体实现如下:
void VlogGC::exec_gc(size_t gc_num_) {
// FIXME: might break, due to unknown concurrency problem
// 线程数控制
curr_thread_nums_latch_.lock();
curr_thread_nums_ ++;
if (curr_thread_nums_ >= max_thread_nums_) {
full_latch_.lock();
}
curr_thread_nums_latch_.unlock();
// start gc process
auto ep = get_executor_params(gc_num_);
gc_executor::exec_gc(ep.vg, ep.old_vlog_num, ep.new_vlog_num);
// test_func(ep.vg, ep.old_vlog_num, ep.new_vlog_num);
curr_thread_nums_latch_.lock();
if (curr_thread_nums_ >= max_thread_nums_) {
full_latch_.unlock();
}
curr_thread_nums_ --;
curr_thread_nums_latch_.unlock();
// std::cout << "vlog_gc.cpp line 138" << std::endl;
del_executor_params(gc_num_);
// std::cout << "vlog_gc.cpp line 140" << std::endl;
del_vlog_gc(gc_num_);
// std::cout << "vlog_gc.cpp line 142" << std::endl;
del_vlog_in_gc(ep.old_vlog_num);
// FIXME: dead lock here (fixed, i think)
// FIXME: remove vlog physically
vlog_set->remove_old_vlog(ep.old_vlog_num);
}
void gc_executor::exec_gc(VlogGC *vlog_gc_, size_t old_vlog_num, size_t new_vlog_num)
功能: 执行GC任务
具体实现如下:
void gc_executor::exec_gc(VlogGC *vlog_gc_, size_t old_vlog_num, size_t new_vlog_num) {
// 从 vlog_gc_ 对象中提取旧 vlog 和新 vlog 的相关信息,这些信息用于后续的操作
auto vlog_set = vlog_gc_->vlog_set;
auto slot_page_ = vlog_gc_->slot_page_;
// 锁定互斥锁
vlog_set->mtx.lock();
// 获取旧 vlog 和新 vlog 的信息
auto old_vlog_name = vlog_set->get_vlog_name(old_vlog_num);
auto new_vlog_name = vlog_set->get_vlog_name(new_vlog_num);
auto old_vlog_info = vlog_set->get_vlog_info(old_vlog_num);
auto new_vlog_info = vlog_set->get_vlog_info(new_vlog_num);
auto old_vlog_handler = vlog_set->get_vlog_handler(old_vlog_num);
auto new_vlog_handler = vlog_set->get_vlog_handler(new_vlog_num);
// 锁机制
old_vlog_info->vlog_info_latch_.lock();
old_vlog_handler->vlog_latch_.soft_lock();
new_vlog_info->vlog_info_latch_.lock();
new_vlog_handler->vlog_latch_.hard_lock();
vlog_set->mtx.unlock();
// 打开旧 vlog 和新 vlog 文件
auto old_vlog = std::fstream(old_vlog_name, std::ios::in | std::ios::out);
auto new_vlog = std::fstream(new_vlog_name, std::ios::in | std::ios::out);
// char old_vlog_buff[VLOG_SIZE];
// char new_vlog_buff[VLOG_SIZE];
// 动态分配内存用于存储旧 vlog 和新 vlog 的内容,可以在内存中高效地处理日志数据
char *old_vlog_buff = static_cast<char*>(malloc(VLOG_SIZE));
char *new_vlog_buff = static_cast<char*>(malloc(VLOG_SIZE));
// 读取旧日志文件内容
old_vlog.seekp(0);
old_vlog.read(old_vlog_buff, VLOG_SIZE);
// 初始化参数:初始化偏移量和新 vlog 中的条目计数,为遍历做准备
size_t value_nums = old_vlog_info->value_nums;
size_t ovb_off = 2 * sizeof(size_t);
size_t nvb_off = 2 * sizeof(size_t);
size_t new_vlog_value_nums = 0;
// 遍历旧 vlog 中的 value 并逐个处理
for (auto i = 0; i < value_nums; i++) {
char *value = &old_vlog_buff[ovb_off];
uint16_t value_len = get_value_len(value);
size_t slot_num = get_value_slotnum(value);
// 如果当前 value 未被设置为删除,则将其复制到新 vlog 的缓冲区中,并更新相关参数
if (!value_deleted(value_len)) {
memcpy(&new_vlog_buff[nvb_off], &old_vlog_buff[ovb_off], value_len);
memcpy(&new_vlog_buff[nvb_off+sizeof(uint16_t)], &(new_vlog_info->vlog_num), sizeof(size_t));
struct slot_content scn(new_vlog_info->vlog_num, nvb_off);
slot_page_->set_slot(slot_num, &scn);
nvb_off += value_len;
new_vlog_value_nums ++;
}
ovb_off += value_len;
}
// 更新新 vlog 信息, 包括条目数量和当前大小
new_vlog_info->value_nums = new_vlog_value_nums;
new_vlog_info->curr_size = nvb_off;
// 写入将新 vlog 缓冲区中的内容写入新 vlog 文件
memcpy(new_vlog_buff, &nvb_off, sizeof(size_t));
memcpy(&new_vlog_buff[sizeof(size_t)], &new_vlog_value_nums, sizeof(size_t));
new_vlog.seekp(0);
new_vlog.write(new_vlog_buff, VLOG_SIZE);
new_vlog.flush();
free(old_vlog_buff);
free(new_vlog_buff);
old_vlog.close();
new_vlog.close();
old_vlog_info->vlog_valid_ = false;
old_vlog_info->vlog_info_latch_.unlock();
old_vlog_handler->vlog_latch_.soft_unlock();
new_vlog_info->vlog_info_latch_.unlock();
new_vlog_handler->vlog_latch_.hard_unlock();
// vlog_gc_->gc_counter_decrement();
}
void SlotPage::dealloc_slot(size_t slot_num)
功能: 释放 slot_num 中对应的 slot
实现步骤:
具体实现如下:
void dealloc_slot(size_t slot_num) {
mtx.lock();
const size_t byte = slot2byte(slot_num);
const size_t off = slot2offset(slot_num);
char *target_byte = get_bitmap_byte(byte);
assert(*target_byte & POSMASK(off));
RESETBIT(target_byte, off);
// set_bitmap_byte(byte, target_byte);
first_empty_slot = first_empty_slot < slot_num ? first_empty_slot:slot_num;
mtx.unlock();
}
3. 功能测试
3.1 在 LevelDB 的 value 中实现字段功能
- 以字段形式插入,读取数据
- 根据 key 删除数据
- 通过字段值查询对应的 key
测试流程:
- 写入4条数据;
- 读取这四条数据;
- 检查读取的数据跟写入的是否一致;
- 通过字段值查询对应的 key;
- 删除查找到的 keys 中的第一个key;
- 通过4中的字段值查询对应的 key,查找到的数目比4中少一个。
测试代码:
代码文件为 /test/db_test3.cc
TEST(TestSchema, Basic) {
DB* db;
WriteOptions writeOptions;
ReadOptions readOptions;
if (!OpenDB("testdb_function", &db).ok()) {
std::cerr << "open db failed" << std::endl;
abort();
}
std::string key0 = "k_0";
std::string key1 = "k_1";
std::string key2 = "k_2";
std::string key3 = "k_3";
FieldArray fields0 = {{"name", "myc&wxf"}};
FieldArray fields1 = {
{"name", "Customer1"},
{"address", "IVhzIApeRb"},
{"phone", "25-989-741-2988"}
};
FieldArray fields2 = {
{"name", "Customer1"},
{"address", "ecnu"},
{"phone", "123456789"}
};
FieldArray fields3 = {
{"name", "Customer2"},
{"address", "ecnu"},
{"phone", "11111"}
};
db->Put_Fields(leveldb::WriteOptions(), key0, fields0);
db->Put_Fields(leveldb::WriteOptions(), key1, fields1);
db->Put_Fields(leveldb::WriteOptions(), key2, fields2);
db->Put_Fields(leveldb::WriteOptions(), key3, fields3);
FieldArray fields_ret_0;
FieldArray fields_ret_1;
FieldArray fields_ret_2;
FieldArray fields_ret_3;
db->Get_Fields(leveldb::ReadOptions(), key0, fields_ret_0);
db->Get_Fields(leveldb::ReadOptions(), key1, fields_ret_1);
db->Get_Fields(leveldb::ReadOptions(), key2, fields_ret_2);
db->Get_Fields(leveldb::ReadOptions(), key3, fields_ret_3);
// 检查反序列化结果
ASSERT_EQ(fields_ret_0.size(), fields0.size());
for (size_t i = 0; i < fields_ret_0.size(); ++i) {
ASSERT_EQ(fields_ret_0[i].name, fields0[i].name);
ASSERT_EQ(fields_ret_0[i].value, fields0[i].value);
}
ASSERT_EQ(fields_ret_1.size(), fields1.size());
for (size_t i = 0; i < fields_ret_1.size(); ++i) {
ASSERT_EQ(fields_ret_1[i].name, fields1[i].name);
// ASSERT_EQ(fields_ret_1[i].value, fields1[i].value);
}
// 测试查找功能
Field query_field = {"name", "Customer1"};
std::vector<std::string> found_keys = FindKeysByField(db, query_field);
// 删除查找到的第一个 key
const std::string& key = found_keys[0];
db->Delete(leveldb::WriteOptions(), key);
// 再次查找
std::vector<std::string> found_deleted_keys = FindKeysByField(db, query_field);
// 关闭数据库
delete db;
}
int main(int argc, char** argv) {
testing::InitGoogleTest(&argc, argv);
return RUN_ALL_TESTS();
}
测试结果:
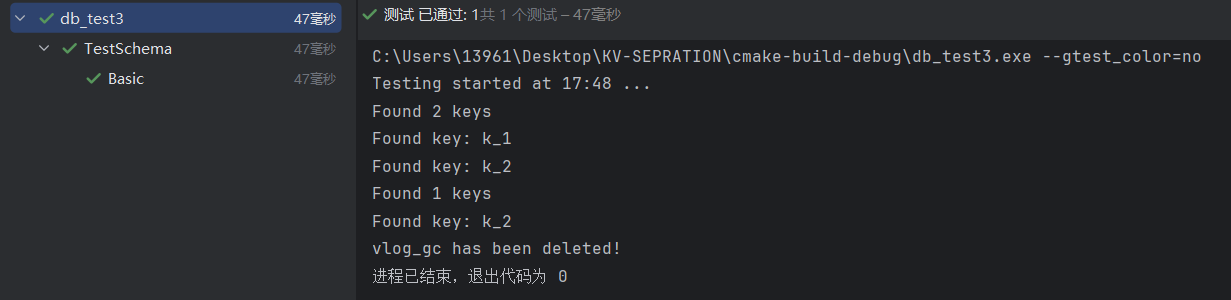
3.2 测试并发插入和读取数据
测试流程: 创建 10 个线程,5 个线程为写线程,5 个线程为读线程,每个写线程写入 100 条数据,每个读线程读取 100 条数据。
代码文件为 /test/db_test6.cc
测试结果:

4. 性能测试:
4.1 测试吞吐量和延迟
测试内容:
小 value 场景:value 大小为 10 字节左右
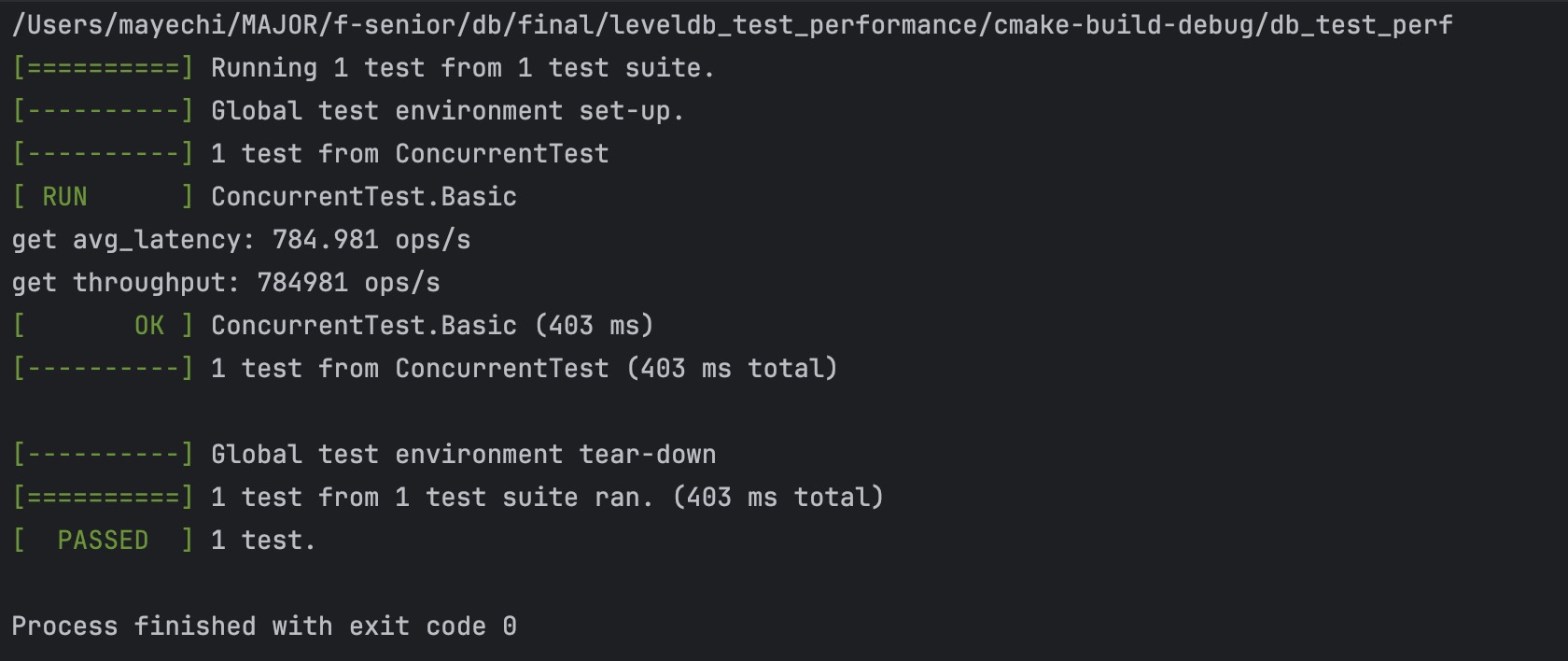
- 并发,10个线程,全部读
leveldb结果:
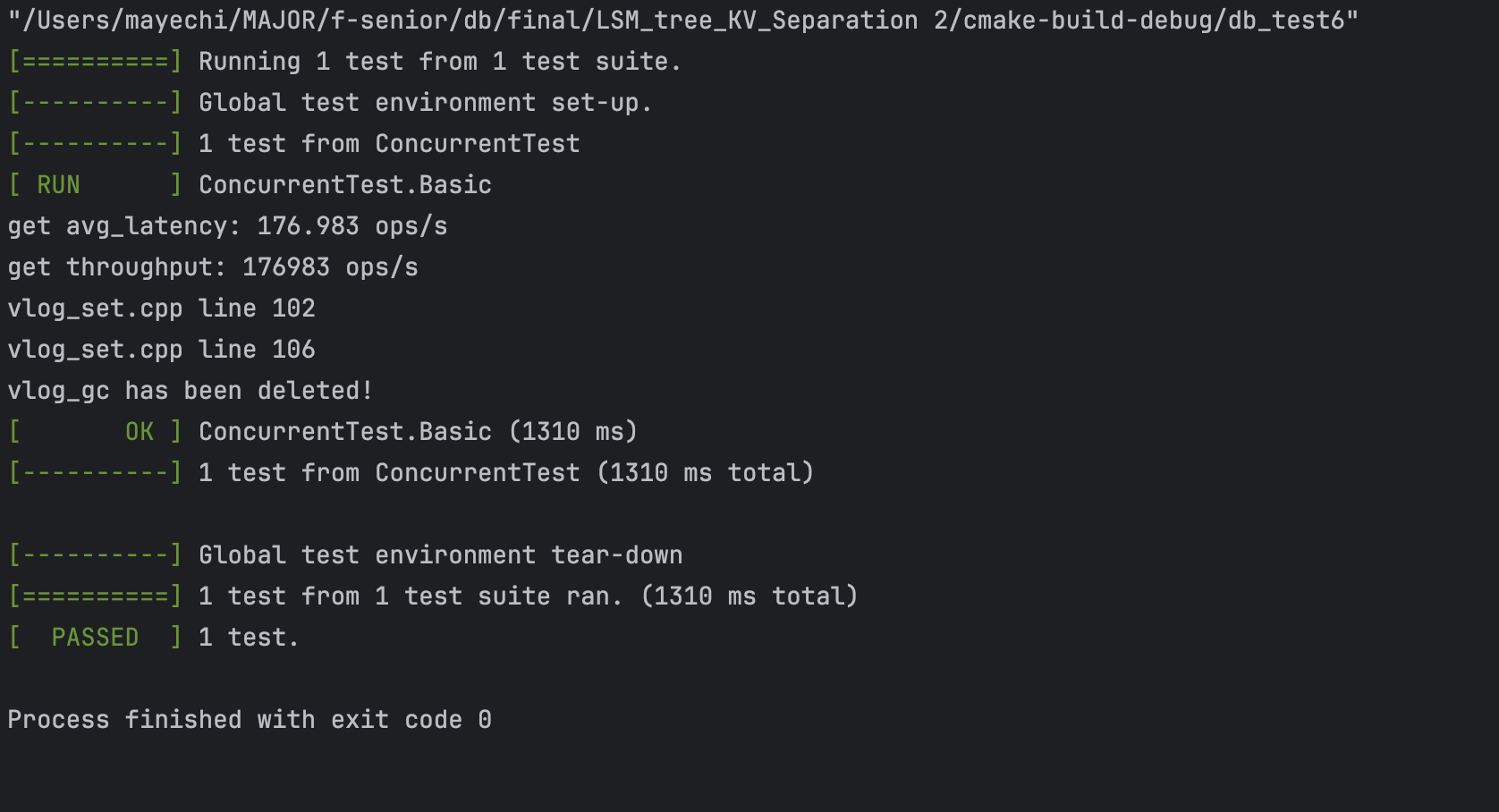
KV 分离结果:
- 并发,10个线程,全部写
leveldb结果:
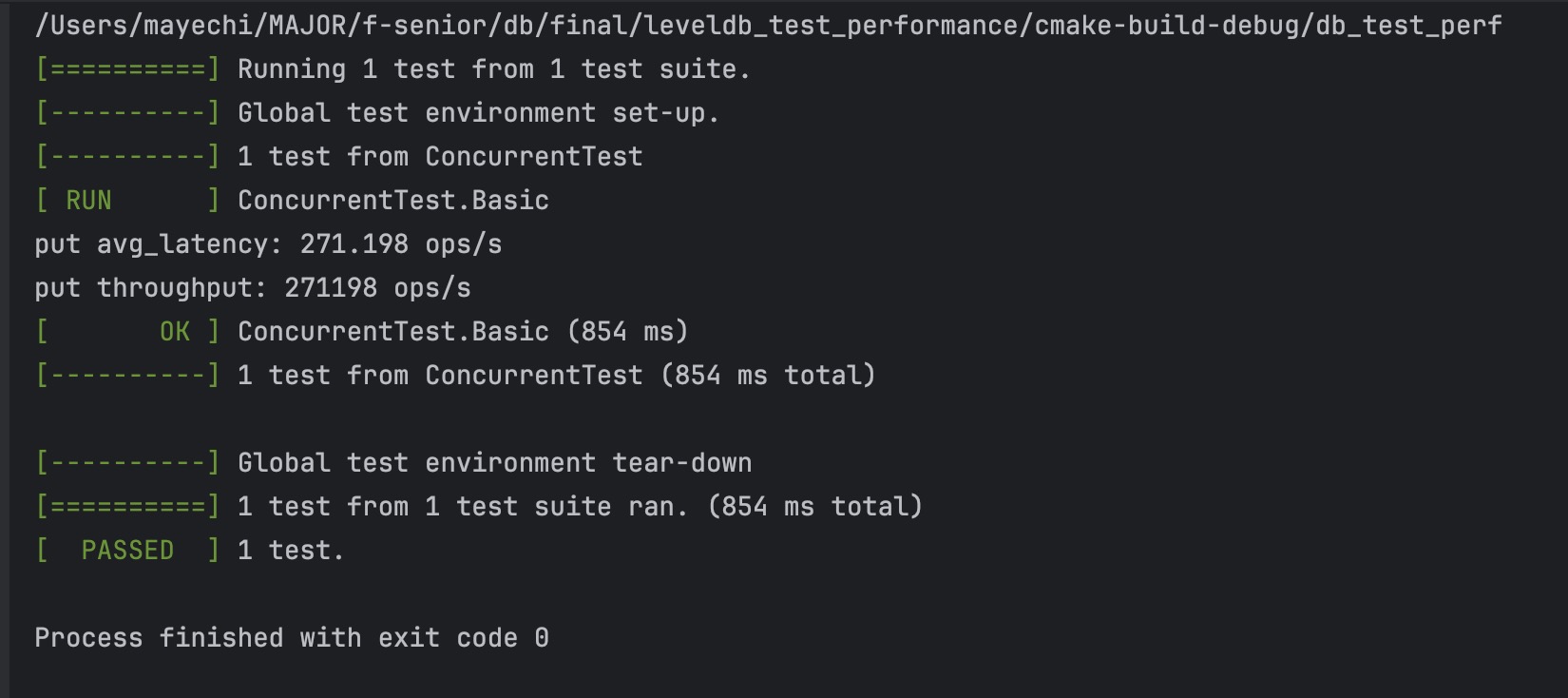
KV 分离结果:
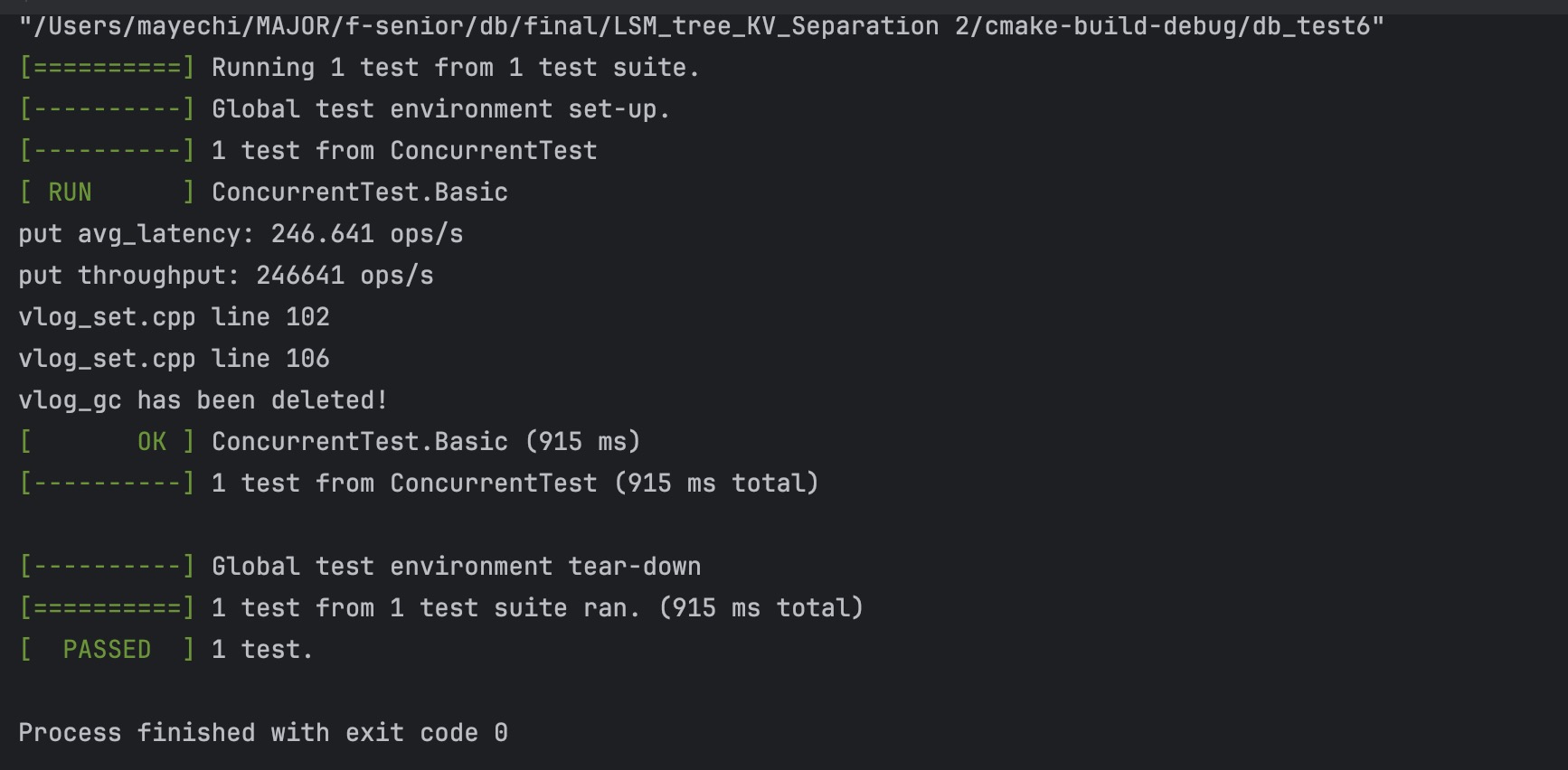
- 并发,10个线程,一半读,一半写
leveldb结果:

KV 分离结果:
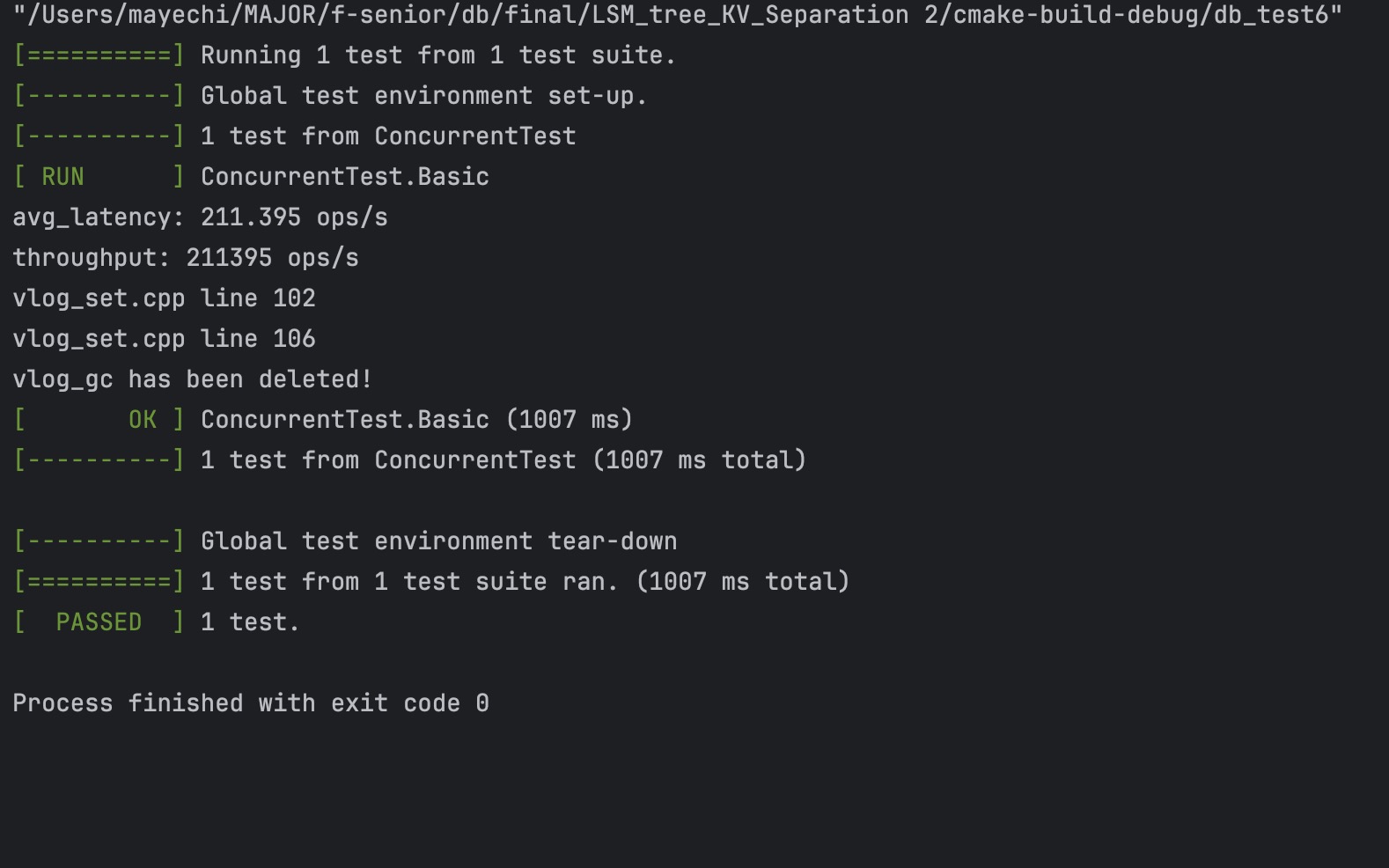
大 value 场景: value 大小为 4 KB
- 五个线程,每个线程有 20000 次写入:
KV 分离结果:

leveldb 结果:
- 五个线程,每个线程有 5000 次读数据:
KV 分离结果:
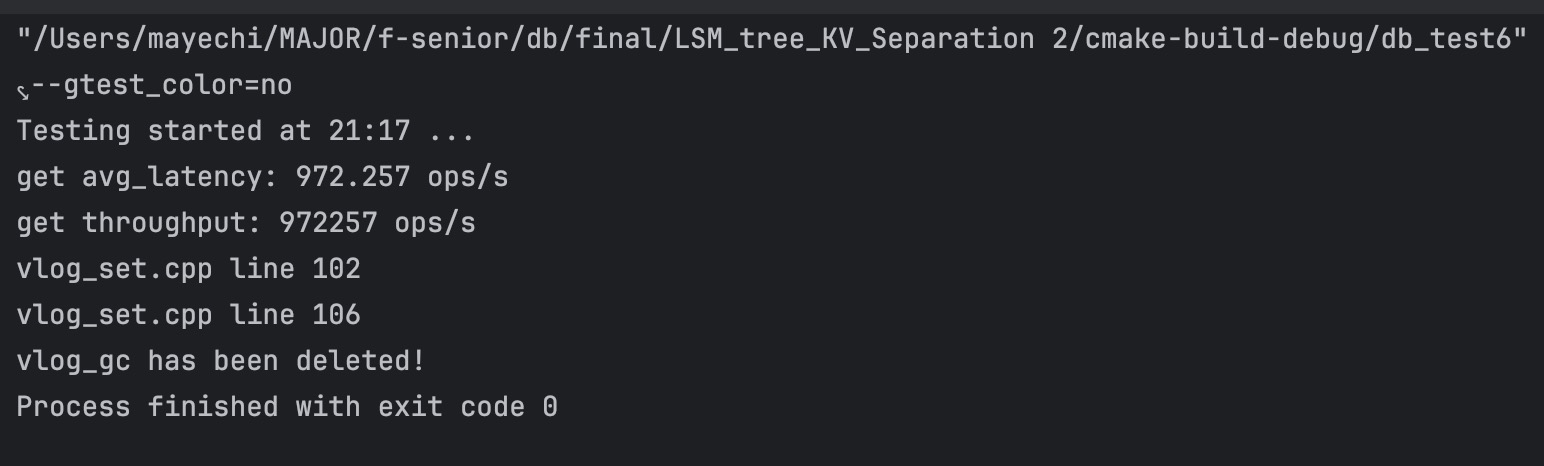
leveldb 结果:

4.2 测试写放大
参数设置为:
constexpr int value_size = 2048;
constexpr int data_size = 512 << 20;`
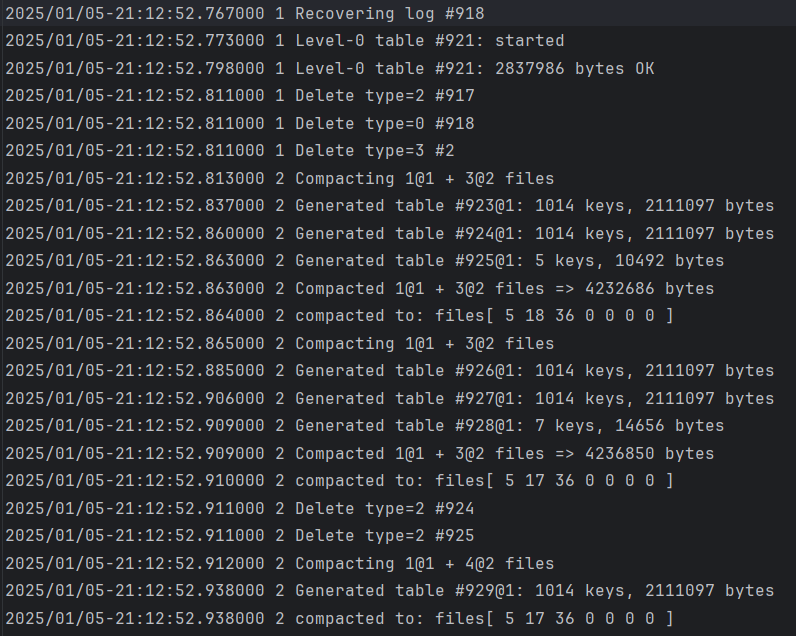
- 初始版本的leveldb:
CURRENT 内容为: MANIFEST-000920
写放大为:4232686 + 4236850 = 8465426
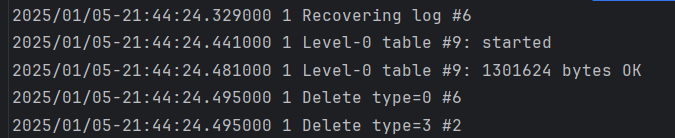
- KV 分离版本:
CURRENT 内容为: MANIFEST-000008
写放大为:
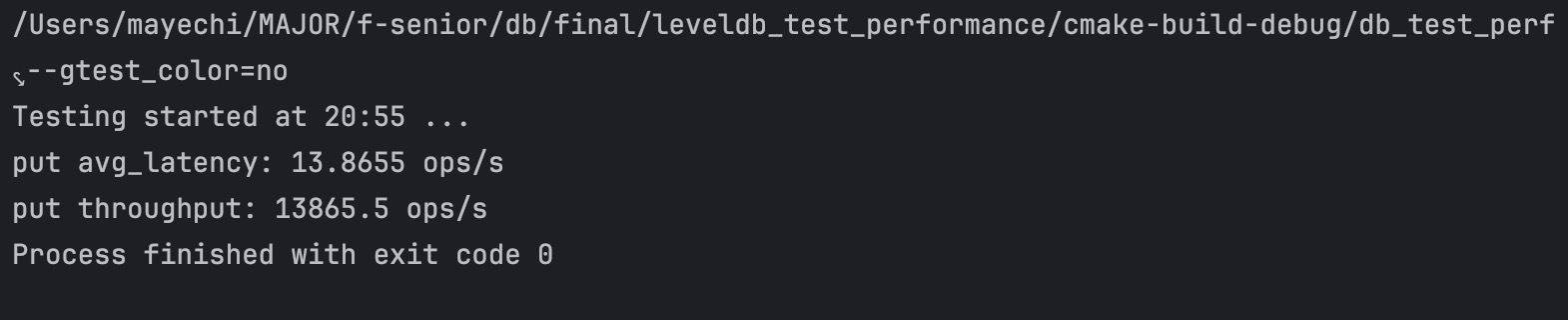
总结: 通过上面的测试可以看出,当 value 设置的比较小时,我们的 KV 分离方案性能与原本的leveldb 相比,有一定程度的下降,并且读性能下降较多,是原本的 1/4;但当我们把 value 的大小设置为 4 KB 时,我们的 KV 分离方案性能与原本的 leveldb 相比,读写性能提升非常大,写性能由 13.9 ops/s 提升到 177 ops/s, 提升大概 12 倍,而 读性能由 19.3 ops/s 提升到 972 ops/s,提升更加明显。
综上所述,当 写入的 value 较小时,我们的 KV 分离方案读写性能比原始版本的 leveldb 要低;但当写入的 value 较大时,我们的 KV 分离版本性能会远远优于原始版本的 leveldb。
5. 实验中遇到的问题和解决方案
- 对于每一次读取,用户线程先读取lsm tree中key的slot_num下标,然后到slot_page中读取对应的slot内容(每一个slot都是定长的),之后再在这个slot中读取value所在的vlog文件号和偏移量offset,之后到对应的vlog文件中读取value。 但是这又带来了一个问题,我们该如何管理slot_page这个文件?当插入新的kv时,我们需要在这个slot_page中分配新的slot,在GC删除某个kv时,我们需要将对应的slot进行释放。
这里我们选择在内存中维护一个可线性扩展的bitmap。这个bitmap中每一个bit标识了当前slot_page文件中对应slot是否被使用,是为1,不是为0。这样一来,在插入新kv时,我们可以用bitmap来分配一个新的slot(将bitmap中第一个为0的bit设置为1),将内容进行写入;在GC删除某个kv时,我们将这个slot对应的bitmap中的bit重置为0即可。
- KV 分离的最初版本,我们没有实现 vlog_cache,读写性能很差,于是我们就考虑能不能再实现一个 vlog_cache,来优化读写性能。 在经过尝试之后,发现确实能提高读写性能,我们便在原本的实现之上添加了 vlog_cache。
6. 分工和进度安排
| 功能 | 完成日期 | 分工 |
|---|---|---|
| Field相关接口实现 | 12.8 | 王雪飞 |
| value_log中value的存储格式 | 12.8 | 王雪飞 |
| slot_page 相关接口 | 12.8 | 马也驰 |
| slot_page 实现 | 12.8 | 马也驰 |
| 修改leveldb的接口实现字段功能 | 12.17 | 王雪飞 |
| vlog的GC实现 | 12.29 | 马也驰 |
| vlog_cache 实现 | 12.29 | 马也驰 |
| 性能测试 | 1.5 | 王雪飞, 马也驰 |
| 功能测试 | 1.5 | 王雪飞, 马也驰 |
| 写实验报告 | 1.5 | 王雪飞, 马也驰 |