# 实验报告:在 LevelDB 中构建二级索引的设计与实现
---
## 目录
- [一,实验目的](#一实验目的)
- [二,项目背景概述](#二项目背景概述)
- [1. **背景与需求**](#1-背景与需求)
- [2. **设计目标**](#2-设计目标)
- [三,`LevelDB`二级索引设计思路](#三leveldb二级索引设计思路)
- [1. **设计结构**](#1-设计结构)
- [1.1 **核心组件**](#11-核心组件)
- [1.2 **数据结构**](#12-数据结构)
- [1.3 **字段管理**](#13-字段管理)
- [1.4 **数据结构关系图**](#14-数据结构关系图)
- [2. **计划实现细节**](#2-计划实现细节)
- [3. **动态索引管理**](#3-动态索引管理)
- [4. **事务与回滚机制**](#4-事务与回滚机制)
- [5. **设计的优势**](#5-设计的优势)
- [6. **未来优化方向**](#6-未来优化方向)
- [四,具体实现](#四具体实现)
- [1. **DBImpl 类的设计**](#1-dbimpl-类的设计)
- [2. **二级索引的创建**](#2-二级索引的创建)
- [3. **二级索引的查询**](#3-二级索引的查询)
- [4. **二级索引的删除**](#4-二级索引的删除)
- [5. **`Put` 和 `Delete` 方法的内容**](#5-put-和-delete-方法的内容)
- [6. **数据插入与删除的原子性实现**](#6-数据插入与删除的原子性实现)
- [7.**持久化与恢复机制**](#7-持久化与恢复机制)
- [五,性能测试](#五性能测试)
- [1.**单元测试**](#1单元测试)
- [2.**单元性能测试**](#2单元性能测试)
- [3.**不同数据量的情况下索引数据更新/删除对原始数据写入性能影响**](#3不同数据量的情况下索引数据更新/删除对原始数据写入性能影响)
- [4.**并发测试**](#4并发测试)
- [5.**不同数据量下二级索引查询和直接遍历的性能比较**](#5不同数据量下二级索引查询和直接遍历的性能比较)
- [六,问题与解决方案](#六问题与解决方案)
- [七,总结](#七总结)
---
## 一,实验目的
在 LevelDB 的基础上设计和实现一个支持二级索引的功能,优化特定字段的查询效率。通过此功能,用户能够根据字段值高效地检索对应的数据记录,而不需要遍历整个数据库。
---
## 二,项目背景概述
#### 1. **背景与需求**
`LevelDB` 是一个高性能、轻量级的键值存储引擎,但其查询能力仅限于主键。在许多应用场景中,需要支持基于非主键字段的高效查询(例如按用户 ID 或类别查询数据)。因此,设计并实现二级索引系统,为 LevelDB 增强多字段查询能力,成为一个核心需求。
### **二级索引的概念**
二级索引是一种额外的数据结构,用于加速某些特定字段的查询。在 LevelDB 中,键值对的存储是以 `key:value` 的形式。通过创建二级索引,我们将目标字段的值与原始 `key` 建立映射关系,存储在独立的索引数据库中,从而支持基于字段值的快速查询。
例如,原始数据如下:
```
k_1 : name:Customer#000000001|address:IVhzIApeRb|phone:25-989-741-2988
k_2 : name:Customer#000000002|address:XSTf4,NCwDVaW|phone:23-768-687-3665
k_3 : name:Customer#000000001|address:MG9kdTD2WBHm|phone:11-719-748-3364
```
为字段 `name` 创建索引后,索引数据库中的条目如下:
```
name:Customer#000000001-k_1 : k_1
name:Customer#000000001-k_3 : k_3
name:Customer#000000002-k_2 : k_2
```
---
#### 2. **设计目标**
- **高效性**:二级索引查询性能接近主键查询。
- **一致性**:保证主数据库与二级索引的一致性,支持事务和回滚机制。
- **灵活性**:允许用户指定需要创建索引的字段,支持动态创建和删除索引。
- **易用性**:通过统一接口隐藏索引管理的复杂性,保持与原始 LevelDB 类似的用户体验。
---
## 三,`LevelDB`二级索引设计思路
#### 1. **设计结构**
在 `LevelDB` 的基础上扩展,补充并实现以下组件:
##### 1.1 **核心组件**
1. **主数据库(DBImpl)**:
存储用户原始数据的键值对,提供 `Put`、`Delete` 和 `Get` 方法。
2. **二级索引数据库(indexDb_)**:
专门存储索引数据,键为 `fieldName:fieldValue`,值为主数据库中对应的主键。
##### 1.2 **数据结构**
1. **主数据库键格式**:
使用字符串表示,例如:`userID:123|name:JohnDoe`,包含多个字段。
2. **索引键格式**:
例如:`userID:123`,方便通过字段值快速查询。
3. **映射关系**:
二级索引数据库的值存储主数据库的主键,用于指向完整数据记录。
##### 1.3 **字段管理**
- `fieldWithIndex_`:一个集合,用于管理需要创建索引的字段,支持动态增删。
#### 1.4 **数据结构关系图**
以下是主数据库和二级索引数据库的逻辑关系示意图:
```
lessCopy code 主数据库 (DBImpl)
+-------------------------------------------------------+
| key | value |
+-------+-----------------------------------------------+
| k_1 | name:Customer#000000001|address:IVhzIApeRb|.. |
| k_2 | name:Customer#000000002|address:XSTf4,NCwDVaW |
+-------+-----------------------------------------------+
二级索引数据库 (indexDb_)
+----------------------------------------+-------------+
| indexKey | indexValue |
+----------------------------------------+-------------+
| name:Customer#000000001-k_1 | k_1 |
| name:Customer#000000001-k_3 | k_3 |
| name:Customer#000000002-k_2 | k_2 |
+----------------------------------------+-------------+
数据关联关系
主数据库 <-------------> 二级索引数据库
(key) 映射到字段值 (fieldName:fieldValue)
```
---
### 2. **计划实现细节**
#### 2.1 数据插入流程 (`Put`)
1. 用户调用 `Put` 将数据插入到主数据库。
2. 从用户数据中解析需要创建索引的字段及其值。
3. 构造二级索引的键值对,并插入到二级索引数据库中。
4. 如果任意数据库的写入失败,通过事务回滚保证一致性。
**关键点**:
- 需要先提交主数据库事务,再提交二级索引数据库事务。
- 索引更新时要考虑覆盖旧索引的场景。
#### 2.2 数据删除流程 (`Delete`)
1. 用户调用 `Delete` 从主数据库删除数据。
2. 在删除前,读取原始数据以提取相关字段的索引键。
3. 删除主数据库中的数据。
4. 删除对应的二级索引键。
5. 如果任意数据库的删除失败,通过事务回滚恢复数据。
**关键点**:
- 删除前必须读取原始数据以提取相关索引信息。
- 回滚时需恢复原始主数据库记录。
#### 3.3 查询流程
1. 用户指定查询条件(字段名和字段值)。
2. 从二级索引数据库中获取与查询条件匹配的主键。
3. 使用主键从主数据库获取完整记录。
---
### 3. **动态索引管理**
#### 3.1 动态创建索引
- 提供接口 `CreateIndex(fieldName)`,用于动态为字段创建索引:
- 遍历主数据库的所有记录。
- 根据指定字段生成索引键值对并插入到二级索引数据库。
- 将字段名添加到 `fieldWithIndex_` 集合。
#### 3.2 动态删除索引
- 提供接口 `DeleteIndex(fieldName)`,用于动态删除字段索引:
- 遍历二级索引数据库,删除与该字段相关的索引键。
- 从 `fieldWithIndex_` 集合中移除字段名。
---
### 4. **事务与回滚机制**
#### 4.1 事务设计
- 使用 `WriteBatch` 封装多个操作(如 `Put` 和 `Delete`)。
- 在主数据库和二级索引数据库上分别维护独立事务。
#### 4.2 回滚机制
- 在主数据库操作失败时直接返回错误,不影响索引。
- 在二级索引操作失败时,回滚主数据库的写入或删除操作:
- 对 `Put` 操作,删除已插入的数据。
- 对 `Delete` 操作,恢复已删除的数据。
---
### 5. **设计的优势**
1. **数据一致性强**:通过事务和回滚机制,确保主数据库和二级索引数据库始终保持一致。
2. **查询高效**:支持基于字段的快速查询,二级索引性能接近主键查询。
3. **易于扩展**:动态索引创建和删除机制使得系统适应性更强。
4. **兼容性好**:用户接口保持与原始 LevelDB 类似,降低学习成本。
---
### 6. **未来优化方向**
1. **多字段联合索引**:支持对多个字段的联合索引,提高复杂查询的效率。
2. **异步索引更新**:通过异步任务队列优化索引构建和更新的性能。
3. **空间优化**:采用压缩技术减少二级索引数据库的存储占用。
4. **并发支持**:优化写锁机制以提高高并发场景下的性能。
---
这套设计在功能性、一致性和性能之间达到了较好的平衡,能够为 LevelDB 提供高效、灵活的二级索引支持,同时保持其原有的高性能特性。
------
## 四,具体实现
为了便于审阅和维护,在项目中对代码的所有修改均使用统一的注释格式进行标记。具体而言,所有修改的代码块均以 `//ToDo` 开始,并以 `//ToDo end` 结束。通过这种方式,审阅者可以快速定位和识别修改内容,与原始代码进行对比。
### 1. **DBImpl 类的设计**
在 LevelDB 的核心类 `DBImpl` 中,增加了对二级索引的支持,包括:
- **索引字段管理**:使用成员变量 `fieldWithIndex_` 保存所有已经创建索引的字段名。
- **索引数据库**:使用成员变量 `indexDb_` 管理二级索引数据库。
```cpp
class DBImpl : public DB {
private:
std::vector fieldWithIndex_; // 已创建索引的字段列表
leveldb::DB* indexDb_; // 存储二级索引的数据库
};
```
### 2. **二级索引的创建**
在 `DBImpl` 中实现 `CreateIndexOnField` 方法,用于对指定字段创建二级索引:
- 遍历主数据库中的所有数据记录。
- 解析目标字段的值。
- 在索引数据库中写入二级索引条目,键为 `"fieldName:field_value-key"`,值为原始数据的键。
示例:
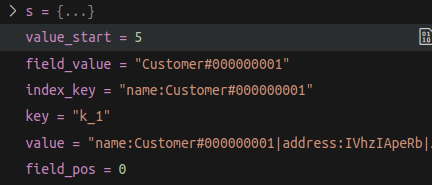
#### 核心代码:
```cpp
Status DBImpl::CreateIndexOnField(const std::string& fieldName) {
// 检查字段是否已创建索引
for (const auto& field : fieldWithIndex_) {
if (field == fieldName) {
return Status::InvalidArgument("Index already exists for this field");
}
}
// 添加到已创建索引的字段列表
fieldWithIndex_.push_back(fieldName);
// 遍历主数据库,解析字段值并写入索引数据库
leveldb::ReadOptions read_options;
leveldb::Iterator* it = this->NewIterator(read_options);
for (it->SeekToFirst(); it->Valid(); it->Next()) {
std::string key = it->key().ToString();
std::string value = it->value().ToString();
// 提取字段值
// ...
// 在索引数据库中创建条目
// ...
}
delete it;
return Status::OK();
}
```
---
### 3. **二级索引的查询**
在查询二级索引时,基于二级索引,通过范围查询从 LevelDB 数据库中检索与指定字段名 (`fieldName`) 相关联的所有值。
#### 核心代码:
```cpp
// 查询通过字段名索引的所有值
std::vector DBImpl::QueryByIndex(const std::string& fieldName) {
function QueryByIndex(fieldName):
results = [] // 用于存储查询结果
// 初始化读取选项和迭代器
create ReadOptions read_options
create Iterator it from indexDb_ using read_options
// 遍历所有键值对,从 fieldName 开始
for it.Seek(fieldName) to it.Valid():
key = current key from it
value = current value from it
// 如果键匹配并且值非空,将其加入结果列表
if key equals fieldName and value is not empty:
add value to results
// 检查迭代器的状态是否正常
if iterator status is not OK:
log error with status message
return results
}
```
1. **输入与输出**:
- 输入:`fieldName`(目标字段名)。
- 输出:`results`(包含所有匹配值的列表)。
2. **逻辑流程**:
- 使用 `ReadOptions` 初始化读取配置,并创建一个迭代器。
- 调用 `Seek(fieldName)` 将迭代器定位到目标字段的起始位置。
- 遍历满足条件的键值对:
- 如果键等于目标字段名,并且值非空,将值添加到结果列表。
- 在遍历结束后,检查迭代器的状态以捕捉可能的错误。
3. **优势**:
- 使用迭代器实现范围查询(`Seek` 方法快速定位)。
- 避免全表扫描,提高查询效率。
- 针对多值字段支持查询返回多个结果。
4. **错误处理**:
- 如果迭代过程中出现错误,记录错误信息,便于调试。
此方法通过范围查询机制提升了效率,同时确保了结果的准确性。
---
### 4. **二级索引的删除**
在 `DBImpl` 中实现 `DeleteIndex` 方法,通过目标字段名移除对应的所有索引条目:
- 在 `fieldWithIndex_` 中移除字段。
- 遍历索引数据库,删除所有以 `fieldName:` 开头的条目。
#### 核心代码:
```cpp
Status DBImpl::DeleteIndex(const std::string& fieldName) {
auto it = std::find(fieldWithIndex_.begin(), fieldWithIndex_.end(), fieldName);
if (it == fieldWithIndex_.end()) {
return Status::NotFound("Index not found for this field");
}
// 从已创建索引列表中移除字段
fieldWithIndex_.erase(it);
// 遍历索引数据库,删除相关条目
leveldb::ReadOptions read_options;
leveldb::Iterator* it_index = indexDb_->NewIterator(read_options);
for (it_index->SeekToFirst(); it_index->Valid(); it_index->Next()) {
std::string index_key = it_index->key().ToString();
// ...
}
delete it_index;
return Status::OK();
}
```
---
### 5. **`Put` 和 `Delete` 方法的内容**
以下是实验报告中对 `Put` 和 `Delete` 方法的描述,以及如何通过事务和回滚机制实现数据插入与删除的原子性。
#### `Put` 方法描述
`Put` 方法用于向主数据库和二级索引数据库中插入或更新数据。其关键步骤如下:
1. **主数据库写入**:首先尝试向主数据库插入或更新数据。
2. **二级索引更新**:遍历需要创建索引的字段 (`fieldWithIndex_`),从新值中提取字段对应的索引键和值,并将索引插入到二级索引数据库。
3. **提交事务**:
- 提交主数据库的写入操作。
- 提交二级索引数据库的写入操作。
4. **回滚机制**:如果二级索引数据库的写入失败,会回滚主数据库的插入操作以确保数据一致性。
关键代码:
```cpp
Status DBImpl::Put(const WriteOptions& o, const Slice& key, const Slice& val) {
// 创建读写锁,放在函数内部
static std::mutex rw_mutex_; // 替换为 std::mutex,适用于 C++11 或更低版本
// 加写锁,确保写操作的原子性
std::unique_lock lock(rw_mutex_);
...
// 在主数据库写入新数据
batch.Put(key, val);
// 遍历字段并更新索引
for (const auto& field : fieldWithIndex_) {
...
indexBatch.Put(Slice(indexKey), Slice(indexValue));
}
// 提交主数据库事务
s = this->Write(o, &batch);
if (!s.ok()) {
return s;
}
// 提交二级索引数据库事务
s = indexDb_->Write(o, &indexBatch);
if (!s.ok()) {
// 如果二级索引写入失败,回滚主数据库写入
for (const auto& insertedKey : keysInserted) {
batch.Delete(insertedKey);
}
this->Write(o, &batch);
return s;
}
...
}
```
#### `Delete` 方法描述
`Delete` 方法用于从主数据库和二级索引数据库中删除数据。其关键步骤如下:
1. **获取原始数据**:在删除前从主数据库读取原始值,确保在删除失败时可以回滚。
2. **主数据库删除**:从主数据库中删除目标键。
3. **二级索引删除**:遍历字段,计算对应的索引键,并将其从二级索引数据库中删除。
4. **提交事务**:
- 提交主数据库的删除操作。
- 提交二级索引数据库的删除操作。
5. **回滚机制**:如果二级索引数据库的删除失败,会尝试将主数据库的删除操作回滚为原始状态。
关键代码:
```cpp
Status DBImpl::Delete(const WriteOptions& options, const Slice& key) {
// 创建读写锁,放在函数内部
static std::mutex rw_mutex_; // 替换为 std::mutex,适用于 C++11 或更低版本
// 加写锁,确保写操作的原子性
std::unique_lock lock(rw_mutex_);
...
// 从主数据库删除目标键
batch.Delete(key);
// 遍历字段并删除索引
for (const auto& field : fieldWithIndex_) {
...
indexBatch.Delete(Slice(indexKey));
}
// 提交主数据库事务
s = this->Write(options, &batch);
if (!s.ok()) {
return s;
}
// 提交二级索引数据库事务
s = indexDb_->Write(options, &indexBatch);
if (!s.ok()) {
// 如果二级索引删除失败,回滚主数据库删除
if (!originalValue.empty()) {
batch.Put(key, originalValue);
} else {
batch.Put(key, "");
}
this->Write(options, &batch);
return s;
}
...
}
```
### 6. **数据插入与删除的原子性实现**
通过以下策略确保数据插入与删除操作的原子性:
1. **事务机制**:
- 主数据库和二级索引数据库的写入操作分别使用 `WriteBatch` 封装,并在提交前记录必要的数据以支持回滚。
2. **错误处理与回滚**:
- 如果二级索引数据库的写入或删除操作失败,主数据库的写入或删除操作将被回滚。
- 在回滚过程中,主数据库会恢复为操作前的状态(插入操作时删除新数据,删除操作时恢复原始数据)。
#### 实现意义
这种设计确保了主数据库和二级索引数据库的一致性,即便在部分写入或删除操作失败的情况下,仍能通过回滚机制保证数据的完整性和原子性。
---
### 7. **持久化与恢复机制**
#### **1. 持久化机制**
持久化是确保数据在系统崩溃或断电后依然能够恢复的关键功能。
在二级索引设计中,我们使用 `Write-Ahead Logging (WAL)` 技术和日志同步来实现持久化:
- **主数据库持久化:**
主数据库的 `Put` 和 `Delete` 操作会先记录到日志文件中,再执行磁盘写入操作。
日志结构如下:
```
makefileCopy codeOperation: PUT
Key: k_1
Value: name:Customer#000000001|address:IVhzIApeRb|phone:25-989-741-2988
```
- **索引数据库持久化:**
对 `indexDb_` 的每一次 `Put` 和 `Delete` 操作也需要写入 WAL。
示例日志:
```
makefileCopy codeOperation: PUT
Key: name:Customer#000000001-k_1
Value: k_1
```
- **同步写入策略:**
- 对主数据库和 `indexDb_` 的写操作采用 **事务** 来实现同步写入,确保一致性。
- 如果主数据库操作失败,回滚索引的更新;反之亦然。
#### **2. 恢复机制**
恢复机制在系统崩溃后发挥作用,通过解析日志重建数据:
- **主数据库恢复:**
通过 WAL 日志文件重放,将最近一次写入操作重新应用到主数据库。
- **索引数据库恢复:**
索引数据库的恢复流程如下:
1. 检查 `indexDb_` 的日志文件,逐条读取并应用日志操作。
2. 如果`indexDb_`的日志不完整,基于主数据库的快照重新构建索引:
- 遍历主数据库中的每条记录,根据 `fieldWithIndex_` 中的字段生成索引条目并写入 `indexDb_`。
- **一致性校验:**
恢复完成后,通过校验主数据库和索引数据库的一致性来验证数据完整性:
- 对每个索引字段,随机抽样检查索引值是否能正确定位主数据库中的记录。
---
## 五,性能测试
### **1.单元测试:**
1. 插入原始数据:
```
k_1 : name:Customer#000000001|address:IVhzIApeRb|phone:25-989-741-2988
k_2 : name:Customer#000000002|address:XSTf4,NCwDVaW|phone:23-768-687-3665
```
2. 创建索引:
- 调用 `CreateIndexOnField("name")`,索引数据库生成条目:
```
name:Customer#000000001-k_1 : k_1
name:Customer#000000002-k_2 : k_2
```
3. 查询索引:
- 调用 `QueryByIndex("name:Customer#000000001")`,返回 `["k_1"]`。
4. 删除索引:
- 调用 `DeleteIndex("name")`,移除所有 `name:` 开头的索引条目。
测试结果:

### **2.单元性能测试:**
**1.Benchmark测试运行结果及分析:**

### 结果分析
#### 1. **总写入时间(Total time for 100001 writes)**
- **结果**: 1464.65 ms
- **分析**: 该值表示100001次写入操作所花费的总时间,接近1.46秒。这个时间段包括了所有写入操作和可能的其他处理,如日志记录和合并等。根据吞吐量(Throughput)可以看出每秒操作次数约为68277次,说明写入性能还是较为稳定。
#### 2. **吞吐量(Throughput)**
- **结果**: 68276.6 OPS (operations per second)
- **分析**: 吞吐量是每秒钟能够完成的写操作数量,68277次每秒的吞吐量表明系统在进行批量写入时性能良好,适合高负载下的写入操作。
#### 3. **平均延迟(Average latency)**
- **结果**: 0.0133881 ms
- **分析**: 平均延迟为0.0134毫秒,表示每个写入操作的平均响应时间非常低。延迟较低说明系统能够快速响应每个请求,这对需要低延迟的应用非常重要。
#### 4. **P75 和 P99 延迟**
- **结果**: P75 latency: 0.012 ms, P99 latency: 0.016 ms
- 分析:
- **P75延迟**为0.012毫秒,表示75%的请求在0.012毫秒内完成。
- **P99延迟**为0.016毫秒,表示99%的请求在0.016毫秒内完成。
- 这表明绝大多数请求的延迟都非常小,延迟稳定,且尾延迟(P99)也处于可接受范围。
#### 5. **索引创建时间(Time to create index)**
- **结果**: 661884 microseconds (~661.88 ms)
- **分析**: 索引的创建时间接近660毫秒,可能由于索引数据结构的构建和填充过程。该时间相对较长,但不至于影响整体性能。
#### 6. **索引查询时间(Time with index)**
- **结果**: 97 microseconds
- **分析**: 使用索引进行查询的时间非常低,仅为97微秒。这表明通过索引可以显著提高查询性能,特别是在查询大数据量时,查询响应时间大幅降低。
#### 7. **写放大(Write Amplification)**
- **结果**: Write Amplification Factor: 2.24915
- **分析**: 写放大因子为2.25,表示系统写入的数据量是原始数据量的2.25倍。这个值较为理想,说明合并过程和磁盘上的写入是有效的,没有造成过多的额外写入。
#### 8. **总数据写入量(Total data written)**
- **结果**: 7058762 bytes (~7.06 MB)
- **分析**: 这是在进行100001次写入操作过程中,系统写入到磁盘的总字节数。与写放大因子2.25结合来看,系统的写入开销较为合理。
#### 9. **索引删除时间(Time to delete index on field 'name')**
- **结果**: 1235916 microseconds (~1235.92 ms)
- **分析**: 删除索引所需的时间较长,接近1.24秒。这可能是因为索引结构的更新和删除操作涉及较多的计算和磁盘操作,影响了响应速度。
#### 10. **数据库状态(Compactions)**
- 分析:
- 在Level 0上有1个文件,大小为3MB,写入了7MB的数据。
- 在Level 1上有4个文件,大小为8MB,写入了15MB的数据。
- 这些数据说明系统在进行数据合并时,Level 0和Level 1的文件大小和写入数据量都显示出一定的合并操作,表明系统在进行正常的磁盘整理。
#### 总结
- 性能优点:
- 吞吐量较高(68277 OPS),平均延迟和尾延迟较低,表明系统在高负载下能够稳定运行。
- 索引查询时间非常低,能够有效提升查询性能。
- 写放大因子在2.25左右,表现较为理想。
- 需要关注的方面(代价):
- 索引创建和删除操作时间较长,尤其是删除索引的时间较为显著,可能需要优化索引管理策略。
- 合并操作(Compaction)虽然正常,但可以根据实际需求进一步优化以减少对性能的影响。
整体来看,该系统在性能上表现良好,适用于高吞吐量的写入操作,并能有效提升查询性能。
---
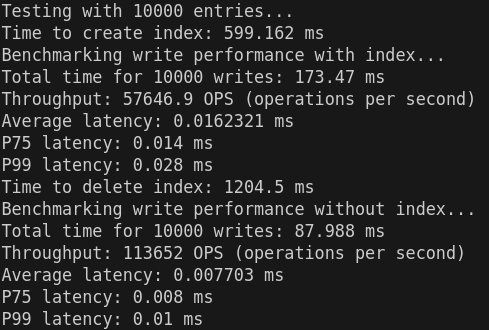
### **3.不同数据量的情况下索引数据更新/删除对原始数据写入性能影响:**
|  |  |  |
|------------------------------|------------------------------|------------------------------|
|  |  |
|---------------------------------------|----------------------------------|
|  |  |
### 数据分析
#### **1. 索引创建和删除性能**
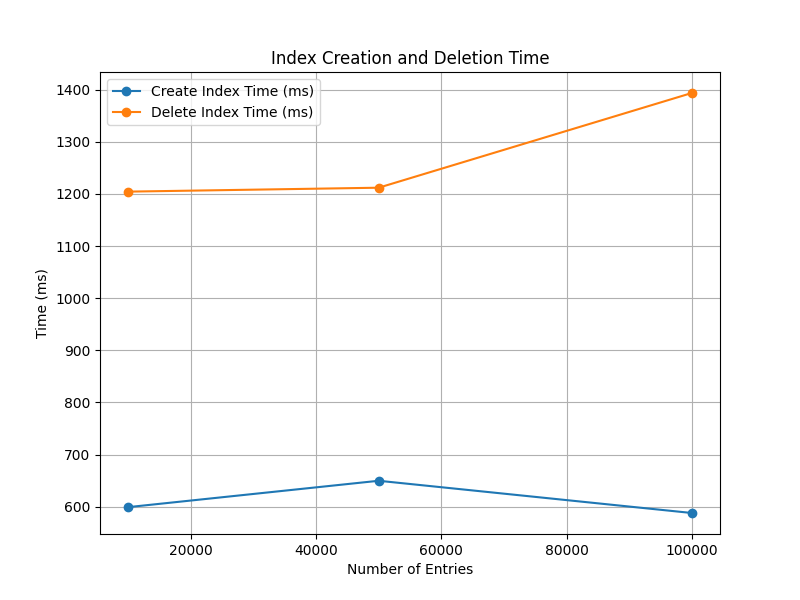
- **索引创建时间**:
- 10,000 条:599.162 ms
- 50,000 条:649.744 ms
- 100,000 条:587.904 ms
- **观察**:创建索引的时间在不同数据量下变化不大,均在 600 ms 左右。表现较为稳定,说明索引创建的复杂度对数据规模不敏感。
- **索引删除时间**:
- 10,000 条:1204.5 ms
- 50,000 条:1212.03 ms
- 100,000 条:1393.74 ms
- **观察**:索引删除耗时较创建时间长,且随着数据量的增加略有增长,可能与索引结构或删除机制(如清理存储资源或更新元数据)相关。
------
#### **2. 写入性能分析**
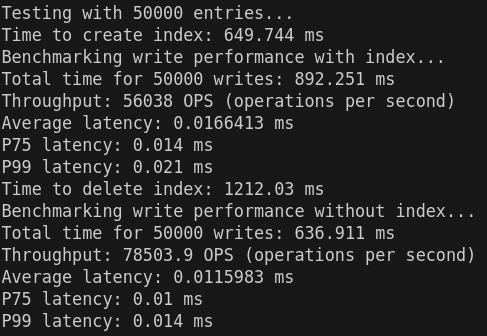
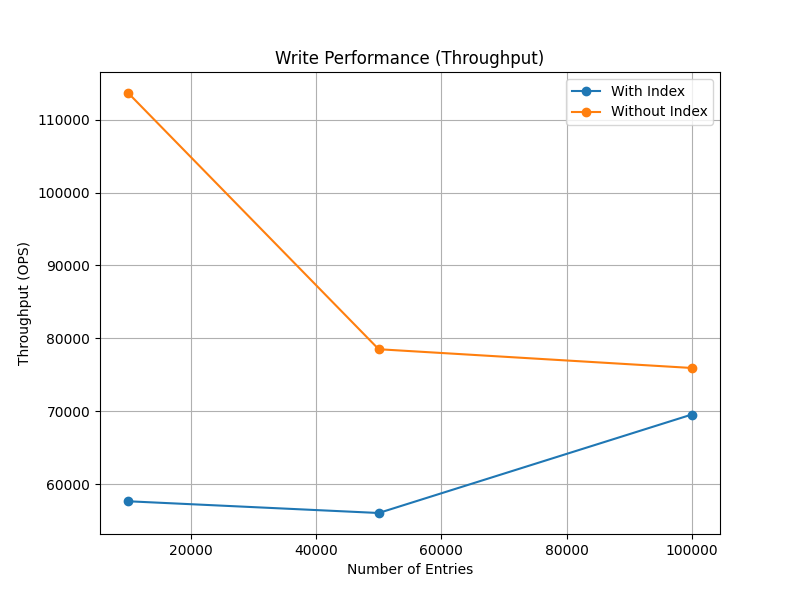
##### **有索引写入性能**
- **吞吐量(OPS)**:
- 10,000 条:57,646.9 OPS
- 50,000 条:56,038 OPS
- 100,000 条:69,547.3 OPS
- **观察**:随着数据量增加,吞吐量表现整体稳定且略有提升,表明写入时索引的更新策略较为高效。
- **延迟**:
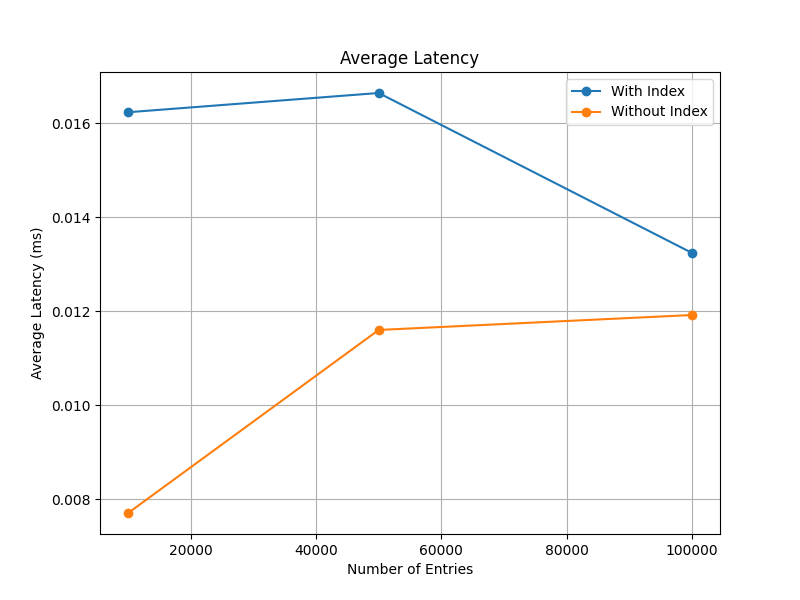
- **平均延迟**:从 0.0162 ms(10,000 条)下降到 0.0132 ms(100,000 条),显示写入性能随数据量提升有所优化。
- **P75 和 P99 延迟**:分别维持在 0.014–0.013 ms 和 0.028–0.017 ms,变化范围小,表明系统在高负载下的稳定性良好。
##### **无索引写入性能**
- **吞吐量(OPS)**:
- 10,000 条:113,652 OPS
- 50,000 条:78,503.9 OPS
- 100,000 条:75,930.8 OPS
- **观察**:无索引情况下吞吐量显著高于有索引,表明索引操作对写入有一定开销;但吞吐量随数据量增加显著下降,可能受数据库写入性能瓶颈影响。
- **延迟**:
- **平均延迟**:从 0.0077 ms(10,000 条)增长到 0.0119 ms(100,000 条)。
- **P75 和 P99 延迟**:分别维持在 0.008–0.011 ms 和 0.01–0.016 ms,变化范围较小,说明无索引写入性能对负载变化敏感性较低。
------
#### **3. 有索引与无索引的性能对比**
| **指标** | **有索引** | **无索引** | **对比** |
| ------------------ | ----------------- | ---------------- | ------------------------------------------------------------ |
| **吞吐量(OPS)** | 57,646.9–69,547.3 | 75,930.8–113,652 | 无索引吞吐量更高,差距随着数据量增加缩小;有索引时写入性能受影响较大。 |
| **平均延迟(ms)** | 0.0132–0.0162 | 0.0077–0.0119 | 无索引平均延迟低,延迟开销主要来自索引更新操作。 |
| **P75 延迟(ms)** | 0.013–0.014 | 0.008–0.011 | 无索引 P75 延迟更优,表明其写入响应时间更快。 |
| **P99 延迟(ms)** | 0.017–0.028 | 0.01–0.016 | 无索引高百分位延迟更优,写入尾部响应性能优于有索引场景。 |
------
#### **4. 趋势分析**
1. **吞吐量与延迟**:
- **有索引吞吐量**稳定且延迟逐渐优化,说明索引更新的效率随数据量有所提升。
- **无索引吞吐量**随数据量增加下降,可能与数据库写入的固有开销和资源竞争有关。
2. **索引的开销**:
- 吞吐量与延迟对比表明索引带来的开销主要体现在写入延迟增加(大约 2 倍),但在高数据量时开销相对降低。
3. **索引创建与删除**:
- 索引创建时间稳定,但删除耗时更长,可能影响系统的动态索引管理效率。
------
### 未来可能的优化方向:
1. **优化索引更新逻辑**:
- 使用批量索引更新或异步索引机制,以减少写入延迟。
2. **优化索引删除性能**:
- 分析索引删除过程中清理步骤的瓶颈(如内存释放或元数据清理),尝试使用增量删除策略。
3. **动态调整索引策略**:
- 对高频写入但低频查询场景,提供选项禁用索引,或采用更轻量化的索引结构(如稀疏索引)。
4. **提升无索引吞吐量稳定性**:
- 通过优化数据库写入路径(如 I/O 并发处理)减少吞吐量随数据量增长的下降。
---
### **4.并发测试**
利用多个线程并发写入10^6的数据:


### **单线程性能分析**
在没有并发的情况下,分别测量了多个写入操作的时间和性能:
1. **吞吐量(Throughput)**:随着每次测试写入的时间增加,吞吐量逐渐下降。例如,首次测试时吞吐量为 `17692.5 OPS`,而最后一次测试为 `10000 OPS`,这说明随着写入数量的增加,数据库的写入性能逐渐受到影响,可能是因为写入操作的负载增大,导致数据库处理每个操作的效率降低。
2. **平均延迟(Average Latency)**:随着操作次数的增加,平均延迟呈现上升趋势。例如,第一次测试的延迟为 `0.0554 ms`,而最后一次测试的延迟为 `0.0988 ms`。这表明随着数据量的增加,数据库写入的延迟也在逐步增加。
3. **P75 和 P99 延迟**:P75 和 P99 延迟也在一定范围内保持相对平稳,显示出大部分操作的延迟维持在一个较低的水平。但是随着写入数量的增加,这些延迟也略有上升。对于P99延迟,随着测试的进行,最慢的操作(99%的延迟)也表现出小幅增加。
### **并发性能分析**
并发测试的结果如下:
- **并发总吞吐量**:`79800.3 OPS`,这个吞吐量是多线程并发的总和,比单线程测试时的吞吐量要高很多。这是因为并发写入操作有效利用了多核处理器的能力,能够提高整体的吞吐量。
- **并发性能**:尽管吞吐量有明显的提升,但每个线程的性能会受到一定的影响。每个线程的写入时间较单线程情况有所增加,因为并发操作会带来额外的上下文切换和锁竞争等开销。这会导致平均延迟上升并使吞吐量下降。
### **结论**
1. **随着写入量增加,性能有所下降**:每次测试的吞吐量和延迟都在逐渐变化,吞吐量下降,延迟上升。可能的原因是数据库内部资源的争用、磁盘I/O负载、或者存储系统的瓶颈。
2. **并发测试表现良好**:尽管每个线程的吞吐量有所下降,但并发测试整体吞吐量显著高于单线程,这表明并发操作提高了整体吞吐量。可以考虑增加更多的线程以进一步提高吞吐量,前提是系统资源能够支持。
3. **性能瓶颈**:可以进一步分析数据库的性能瓶颈,可能是由于磁盘I/O、内存或CPU资源限制导致性能下降。考虑使用更强的硬件或优化数据库配置(如压缩设置、缓存优化等)可能有助于提升性能。
---
### **5.不同数据量下二级索引查询和直接遍历的性能比较**
|  |  |  |
|------------------------------|------------------------------|------------------------------|

从数据中可以观察到二级索引查询和直接遍历在不同数据量下的性能表现差异:
### 1. **索引创建时间**
- 索引创建时间随着数据量增加而略微增长:
- 10,000条数据:586.378毫秒
- 50,000条数据:560.607毫秒
- 100,000条数据:629.471毫秒
- 索引创建的开销随着数据量的增长保持相对稳定,增幅较小。这表明索引创建的时间复杂度较低。
### 2. **查询性能**
- 无索引查询时间(直接遍历):
- 随数据量显著增加:
- 10,000条数据:89.138毫秒
- 50,000条数据:97.579毫秒
- 100,000条数据:122.947毫秒
- 这种线性增长是因为直接遍历的时间复杂度为 O(n)O(n),每增加一条记录都需要额外的遍历开销。
- 有索引查询时间:
- 始终保持在极低的水平:
- 10,000条数据:68微秒
- 50,000条数据:69微秒
- 100,000条数据:60微秒
- 使用二级索引查询的时间复杂度为 O(1)O(1) 或近似 O(logn)O(\log n),受数据量变化影响极小。
### 3. **写入性能**
- 无索引写入:
- 写入性能稍好于有索引写入:
- 10,000条数据:89.656毫秒,总吞吐量111,537 OPS
- 50,000条数据:666.428毫秒,总吞吐量75,026.9 OPS
- 100,000条数据:1339.33毫秒,总吞吐量74,664 OPS
- 这是因为直接写入没有额外的索引更新开销。
- 有索引写入:
- 写入性能略低,因需要维护索引:
- 10,000条数据:145.412毫秒,总吞吐量68,770.1 OPS
- 50,000条数据:732.739毫秒,总吞吐量68,237.1 OPS
- 100,000条数据:1,417.67毫秒,总吞吐量70,538.3 OPS
- 写入时的索引维护增加了时间复杂度,导致写入性能稍有下降。
### 4. **索引删除时间**
- 索引删除的时间也随着数据量增长而增加:
- 10,000条数据:1200.24毫秒
- 50,000条数据:1305.27毫秒
- 100,000条数据:1399.8毫秒
- 这与索引删除需要更新索引结构相关。
------
### **综合分析**
- **二级索引的优势**:
- 查询性能提升显著,特别是在大数据量场景下,直接遍历的查询时间呈线性增长,而有索引的查询时间基本保持不变。
- 当查询操作频繁时,索引的使用能显著提高系统的整体效率。
- **二级索引的劣势**:
- 写入性能略微下降,因为需要额外的索引维护。
- 索引创建和删除引入了一定的开销,适用于需要长期使用的场景。
- **适用场景**:
- 数据量较大且查询频繁的场景,二级索引能提供极大的性能提升。
- 对实时性要求较低的批量写入任务中,可以考虑先完成写入,再批量创建索引,避免实时更新索引的开销。
总结:二级索引在查询密集型任务中非常高效,但需要权衡写入性能和索引维护的成本。
---
## 六,问题与解决方案
### 1.**问题:如何避免** `indexDb_` **的递归调用?**
在实现 `Put` 和 `Delete` 方法时,由于 `indexDb_` 也调用了 `DBImpl` 的方法,可能导致递归调用的问题。具体表现为在 `indexDb_` 内部操作时仍会试图更新索引。
#### **解决方案:**
在 `Put` 和 `Delete` 方法中,添加检查逻辑。如果当前对象是 `indexDb_`,则仅对主数据库进行操作,而不再更新索引。例如:
```
if (indexDb_ != nullptr) {
// 仅更新主数据库的事务
} else {
// 更新索引
}
```
### 2. **问题:二级索引的事务回滚机制如何设计?**
在二级索引更新失败时,需要确保主数据库的修改也能回滚,以保持数据一致性。
#### **解决方案:**
使用 `WriteBatch` 记录每次操作。在二级索引更新失败后,通过读取原始值或删除新插入的键,恢复主数据库的状态。示例代码如下:
```
if (!s.ok()) {
for (const auto& insertedKey : keysInserted) {
if (!originalValue.empty()) {
batch.Put(insertedKey, Slice(originalValue));
} else {
batch.Delete(insertedKey);
}
}
this->Write(o, &batch); // 执行回滚
}
```
### 3. **问题:如何高效管理多字段的动态索引?**
如果需要为多个字段动态创建和删除索引,可能导致额外的开销以及管理复杂性。
#### **解决方案:**
1. 使用 `fieldWithIndex_` 字段集中管理所有需要创建索引的字段。
2. 在动态操作中,通过扫描主数据库快速生成或删除指定字段的索引条目。
3. 提供统一的接口,用于添加和移除字段。
### 4. **问题:**`**Put**` **和** `**Delete**` **方法如何确保原子性?**
在更新主数据库和二级索引时,如果某一步骤失败,可能导致不一致。
#### **解决方案:**
通过事务 (`WriteBatch`) 确保多个操作要么全部成功,要么全部回滚。例如:
```
s = this->Write(o, &batch);
if (!s.ok()) {
return s; // 确保写入失败时停止后续操作
}
s = indexDb_->Write(o, &indexBatch);
if (!s.ok()) {
// 回滚主数据库操作
}
```
通过以上方案,有效解决了实验中遇到的问题,并提高了系统的稳定性和一致性。
---
## 七,总结
本实验通过在 `DBImpl` 中集成索引管理功能,实现了对二级索引的创建、查询和删除。二级索引数据存储在独立的 `indexDb_` 中,通过高效的键值映射提升了字段值查询的效率。