# LevelDB-kv分离--实验报告
#### 完成人:曹可心、朴祉燕
## 一、功能设计v1.0
### 1.1. 字段设计
#### 设计目标:
- 提供一个key能对应多个字段作为value,且只用作为一个条目存储的功能
- 为了保证自由度,字段数目和字段名都可以由用户决定
- 增强数据库查询灵活性,可以通过value中的字段值来查询key
#### 实现思路:
为了保证可变的字段数目和字段名,除了使用leveldb中提供的变长整数编码外,我们还提出了两种新的方法,但它们存在各自的局限性。
#### (1) 用特殊符号分隔开每个字段名和字段值
图1
如将 fields{{"name", "Customer#000000001"},{"address", "IVhzIApeRb"}, {"phone", "25-989-741-2988"}} 转化为字符串 "name*Customer#000000001*address*IVhzIApeRb*phone*25-989-741-2988"
**局限性**:如何选择特殊符号才能保证字段名和字段值中不包含特殊符号
#### (2) 用偏移量标识
图2
如将 fields{{"name", "Customer#000000001"},{"address", "IVhzIApeRb"}, {"phone", "25-989-741-2988"}} 转化为字符串 "22name0address18phone28Customer#000000001IVhzIApeRb25-989-741-2988"
**局限性**:字段名如果包含数字可能会导致解析错误
#### (3) 记录字段个数、字段名和字段值的长度
这种方法依赖于特殊的编码方式Varint32/Varint64,在获得解码后的属性长度后可以直接获得属性值,节省空间且简洁高效,能够较好的进行数据压缩,但在大值处理上可能存在某些局限。具体结构见本文档3.1部分。
### 1.2. KV分离
#### 设计目标:
- 优化LevelDB的写放大问题
- 提高数据库查询效率,通过键值对的方式快速定位所需数据。
- 优化数据存储结构,减少不必要的数据冗余和重复。
#### KV 分离的好处
1. compact 不需要重写 value,大大减少了无效 IO。
2. LSM-Tree 不存储 value,体积更小,一个 SST 文件能存更多的 key,有利于减少读 LSM-Tree 的 I/O。
3. LSM-Tree 的体积小,操作系统的文件缓存效果会更好。LSM-Tree 基本都可以 cache 在内存中。
#### KV 分离后存在的问题
1. 当 value 较小时,重写 value 这部分的开销就比较小,KV 分离存储带来的好处就不足以抵消它带来开销。
2. 如何对删除 value 中的垃圾数据
3. 怎么分key和value?需要在“根据 key 迅速定位到 value 的位置”和“降低写放大性能”中trade-off。
4. 新生成的valueLog要怎么进行合并?
#### 方案设计
图3
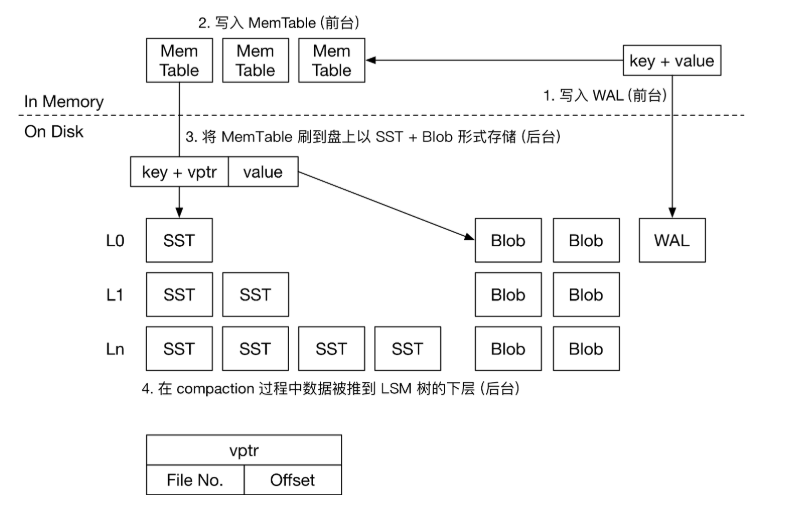
我们将 key 和 value 对应的索引还是存储在 SST 文件中,将真正的 value 存储在 blob 文件中。
key 和 value 分离的时机是在内存数据 flush 到磁盘的时候。
- 当 value 小于分离阈值时,将 key 和 value 都存储在 SST 文件中;
- 当 value 大于分离阈值时,将 key 和 value 索引存储在 SST 文件中,value 存储在 blob 文件中。
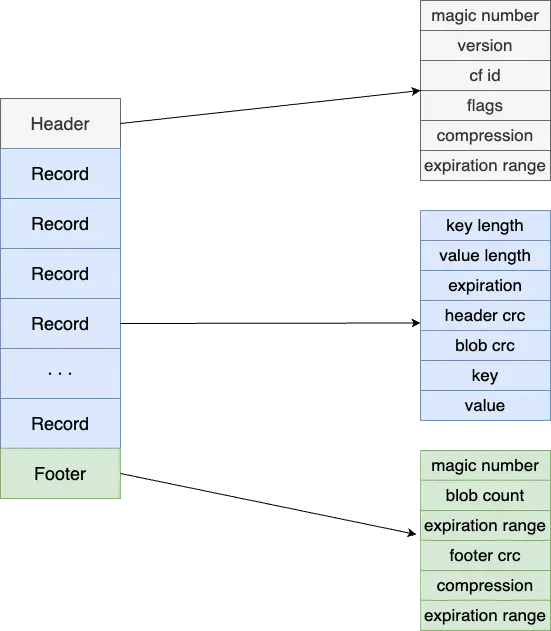
BlobFile 中包含了按key顺序的有序存储的 KV 对,KV 对按单个记录压缩。因此,在 Flush 的过程中,大 value 在 LSM 树中的存储形式为 >。
#### 如何删除 blob 文件中的垃圾数据
我们知道 compaction 会删除 SST 文件中的垃圾数据,但并不会删除 blob 中真正的 value,那我们如何删除 blob 文件中的垃圾数据呢,这就要引入 blob 文件的 GC 机制。blob 文件的 GC 要解决两个问题:
1. 何时进行 GC?
2. 挑选哪些文件进行 GC?
3. 合并就能保证所有垃圾数据就被删除掉了吗?
**-- 首先看第一个问题,何时 GC ?**
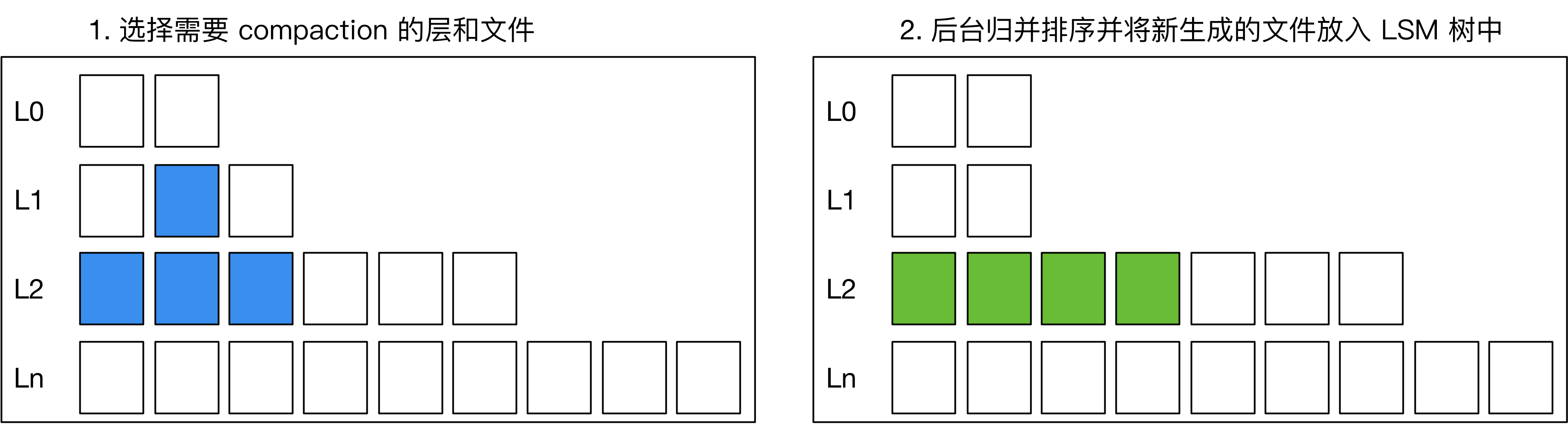
LevelDB是通过Compact来丢弃旧版本数据以回收空间的,因此每次Compact完成后,某些Blob文件中便可能有部分或全部数据过期,因此可以在每次Compact结束后进行GC。
**-- 挑选哪些文件进行GC?**
垃圾数据最多的文件进行GC。
那么问题又来了,如何判断文件的垃圾数据大小?
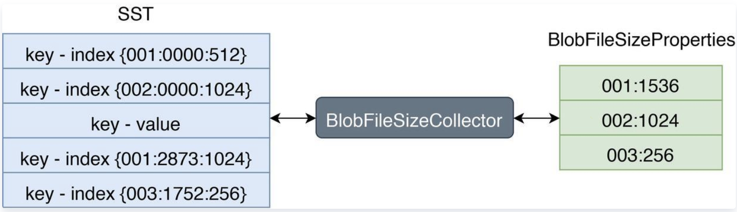
RocksDB 允许用户使用自定义的TablePropertiesCollector(文件信息搜集器)来搜集 SST 文件上的用户所关心的数据。我们可以通过这个特性来搜集 SST 文件上的 Blob 文件信息。如下图:
图4
左边 SST 中 Index 的格式为:
第一列代表 BlobFile 的文件 ID,第二列代表 blob record 在 BlobFile 中的 offset,第三列代表 blob record 的 size。
右边 BlobFileSizeProperties 中的每一行代表一个 BlobFile 以及 SST 中有多少数据保存在这个 BlobFile 中,第一列代表 BlobFile 的文件 ID,第二列代表数据大小。
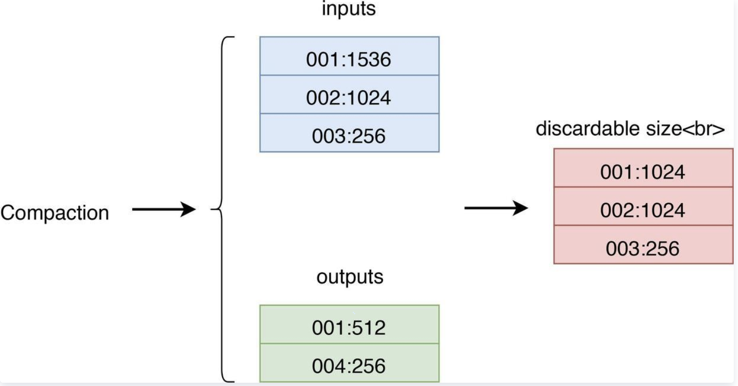
每次 compact 都会记录输入文件和输出文件
图5
- inputs 代表参与 Compaction 的所有 SST 的 BlobFileSizeProperties,
- outputs 代表 Compaction 生成的所有 SST 的 BlobFileSizeProperties,
- discardable size 是通过计算 inputs 和 outputs 得出的每个 BlobFile 被丢弃的数据大小,第一列代表 BlobFile 的文件 ID,第二列代表被丢弃的数据大小。
**LevelDB有没有类似的?--好像没有**
这样,我们就可以计算出每个 blob 文件的垃圾数据大小,然后排序,优先 GC 垃圾数据最多的 blob 文件。
KV 分离存储除了 GC 的问题,还有很多问题需要解决,如 blob 文件的多版本并发访问、服务重启后如何重新计算 blob 文件的垃圾数据量等。
**可能存在的问题**
- GC 速度自动调节
- Blob 文件存储优化
- blob 文件的多版本并发访问
- 服务重启后如何重新计算 blob 文件的垃圾数据量
## 二、数据结构设计 v1.0
### 2.1 字段数据结构
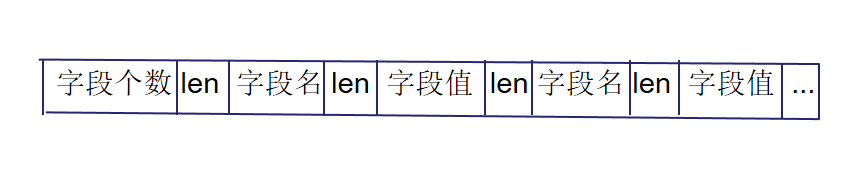
图6
将字段个数、每个字段名与字段值的长度都作为无符号32位整数进行变长编码(Varint32),与字段名、字段值按顺序排列在一起作为value。
借助函数PutLengthPrefixedSlice(),该函数对参数字符串的长度进行编码,同时将编码后的长度和字符串追加到目标字符串中,从而形成value。
### 2.2 KV分离
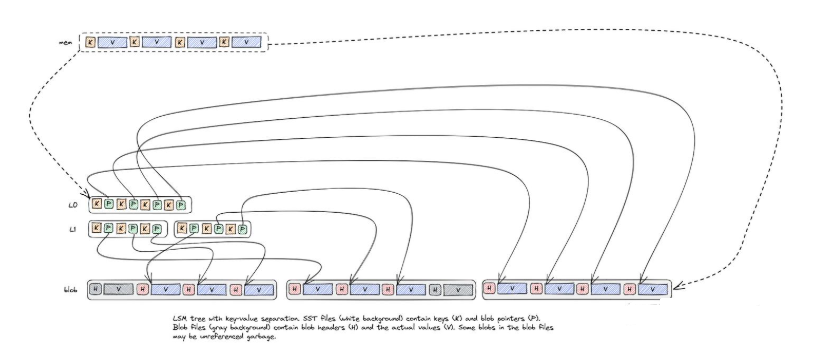
图7
图8
将 blob 文件构建卸载到 DB 的后台作业(即flush和compaction)有几个优点。它使 BlobDB 能够提供与 DB 本身相同的一致性保证。还有一些性能优势:
- 与 SST 类似,任何给定的 blob 文件都是由单一后台线程写入的,这消除了多线程之间一致性风险。
- Blob 文件可以使用大 I/O 写入;无需像旧 BlobDB 那样在每次写入后刷新它们。这种方法也更适合基于网络的文件系统,其中小量写入可能会很昂贵。
- 在后台compaction blob 可以改善延迟。
- 与 SST 文件类似,blob 文件按key排序,这可以提高性能,例如在compaction和迭代期间使用预读。
- 当涉及到垃圾收集时,可以重新定位 blob,同时可以更新相应的 blob 引用,因为它们是在compaction过程中遇到的(无需任何额外的 LSM-Tree操作)。
如上所述,结合示意图,我们可以看到blob file在一开始的时候(memtable flush成SST的时候)跟SST是一一映射的。在后续的SST compaction的时候,blob file有两种选择:
1. 保持不变,这样SST compaction的时候value不需要重写,降低了写放大,但是会导致空间放大。
2. 开启blob file的compaction,将compaction期间需要keep的key的value读取出来重新写入到一个新的Blob file中,同时compaction产生的SST会使用这个新的blob file中的value-index。这样old blob file就可以异步物理删除了(简化讨论,暂时先不讨论blob file被引用的情况)
### 2.3 GC的实现
在用户删除或更新 key 后,常见 LSM 引擎会在 compaction 过程中把旧的记录删除,如下图所示:如果在做 compaction 时,发现上下层有相同的 key,或者上层有 delete tombstone,引擎则会将下层的 key 删除,在新生成的 SST 中只保留一份 KV。
图9
将大 value 分离出 LSM 树后,我们需要处理大 value 的垃圾回收,减少盘上存在的垃圾数据,减少 KV 分离导致的空间放大。
普通垃圾回收 (Regular GC) ,用统计信息确定要回收的 BlobFile,而后重写对应的 BlobFile,将新的 vptr 写回 LSM 树。整个流程如下图所示。
图10
由于没有类似内置 MVCC 多版本并发控制功能,在回写 LSM 树时,需要注册 WriteCallback,在 callback 中检测当前回写的 key 是否已经被删除或更新。这会对引擎 GC 过程中的用户写入吞吐造成巨大的影响。
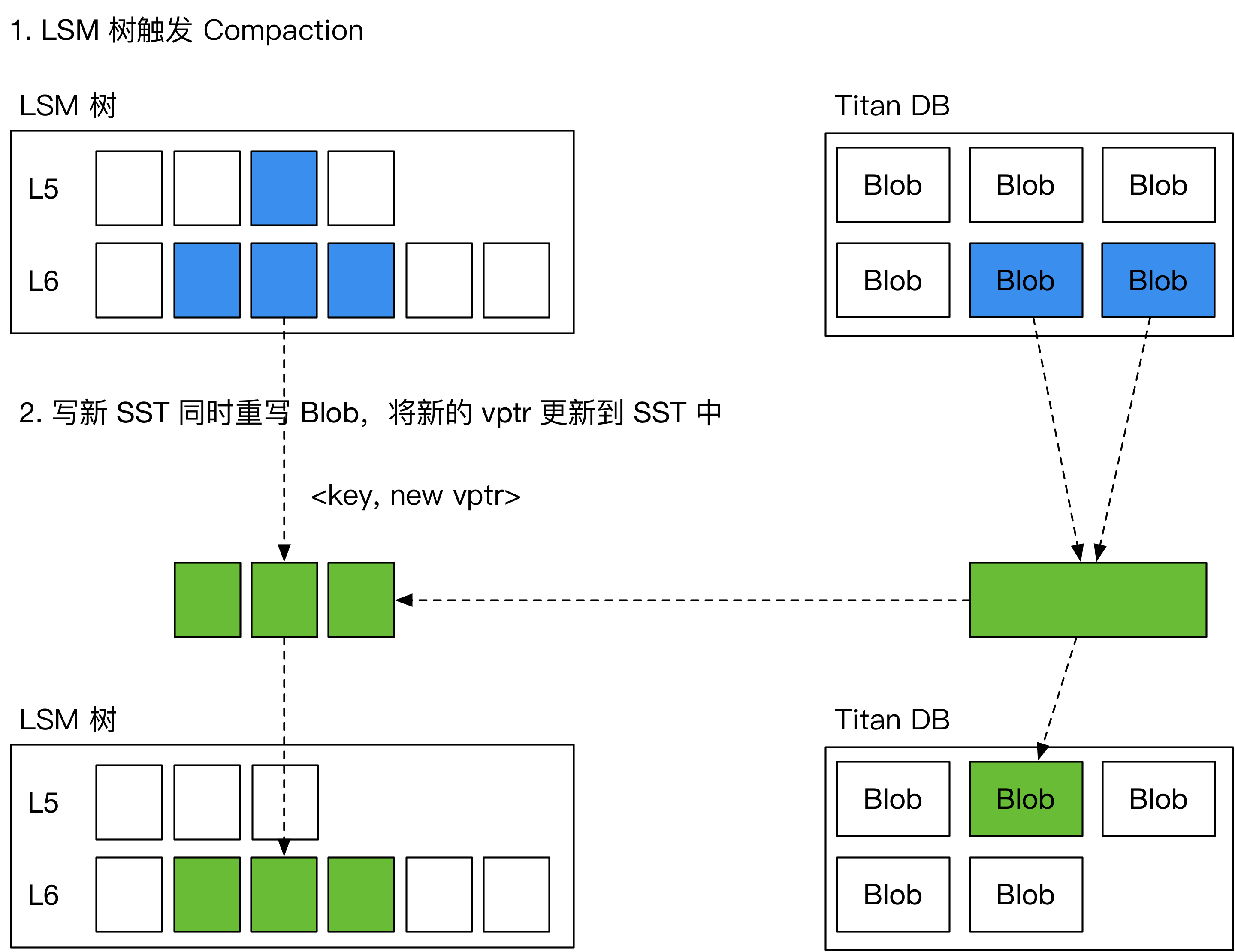
为了解决这一问题,引入了一种新的 GC 方案,名为“Level Merge”,如下图所示,在 LSM 树做 compaction 的过程中,将对应的 BlobFile 重写,并顺便更新 SST 中的 vptr。由此减少了对前台用户写入的影响。
图11
Level Merge 仅在 LSM 树的最后两层启用。
具体的数据结构可能需要等BlobFile落实才能进一步设计。
#### BlobDB的GC具体设计:
1. 在compaction过程中,迭代器 处理 类型 kTypeBlobIndex 的key时会进入到GarbageCollectBlobIfNeeded,因为分离存储的时候LSM-Tree中存放的value 是key-index,即这个value能够索引的到blob file的一个index。
2. 确认当前blob能够参与GC 且 当前key需要被保留,则根据key-index 读取到blob_value 并直接写入到新的blob-file中。并且将新的blob-index 作为当前key的value,提取出来。
3. key 和 新的key-index 继续参与compaction后续的落盘行为,形成新的SST。
4.
重点是第二步,也就是想要GC的话会在compaction过程中直接将过期的blob-value直接回收,compaction完成之后 LSM-Tree的sst 以及 blob都会被更新到,只需要维护后续的旧的blob回收即可。
BlobDB通过参数blob_garbage_collection_age_cutoff来判定哪些old blob file需要被回收,例如,默认值 0.25 向 RocksDB 发出信号,表明 GC 应该重新定位最旧 25% 的 Blob 文件中的 Blob。可以调整该参数来调整写入放大和空间放大之间的权衡。
也就是说blob file的物理删除是异步进行,根据blob_garbage_collection_age_cutoff来决定哪些blob file足够老,可以被删除。
## 三、接口/函数设计 v1.0
描述实现功能要新增的函数及其功能说明。例如Value log的GC,二级索引的建立、查询、删除等操作。
### 3.1 字段分离
#### (1) std::string SerializeValue(const FieldArray& fields)
用于将字段数组序列化为字符串。实现方法:
```C/C++
std::string SerializeValue(const FieldArray& fields)
{
定义空字符串dst;
获取字段数组的长度size;
将size编码为Varint32并加入dst;
遍历fields中的field_name, field_value
{
将field_name编码为Varint32并加入dst;
将field_value编码为Varint32并加入dst;
}
返回dst;
}
```
#### (2) FieldArray ParseValue(const std::string& value_str)
用于将字符串反序列化为字段数组,主要借助函数GetLengthPrefixedSlice解码字符串前缀的变长整数同时移除相应长度的字符串。实现方法:
```C/C++
FieldArray ParseValue(const std::string& value_str)
{
定义空的FieldArray fields;
解码得到字段数组的长度size;
循环size次
{
解码得到字段名;
解码得到字段值;
将字段名和字段值组成pair加入到fields中;
}
返回fields;
}
```
#### (3) std::vector FindKeysByField(leveldb::DB* db, Field &field)
用于通过指定的字段名和字段值查找key。实现方法:
```C/C++
std::vector FindKeysByField(leveldb::DB* db, Field &field)
{
新建一个std::vector ret存储找到的key;
新建一个DBIter it;
it指向数据库中第一个key;
while it 有效
{
取出it对应的value;
对value进行解析,获得字段数组fields;
遍历fields
{
如果字段名等于field的字段名且字段值等于field的字段值
{
将it的key加入ret中;
}
}
}
返回ret;
}
```
### 3.2 ValueLog-BlobFile
#### 3.2.1 是否开启kv分离并实现接口
是在刷盘flush的时候进入kv分离,有flush函数的文件table/table_builder.cc:
```c++
void TableBuilder::Flush() {
Rep* r = rep_;
assert(!r->closed);
if (!ok()) return;
if (r->data_block.empty()) return; //朴,正常判断
assert(!r->pending_index_entry);
if (DBImpl::key_value_separated_) {
// 这里获取数据块内容并初始化 Block 对象,朴
Slice block_content = r->data_block.Finish();
BlockContents contents;
contents.data = block_content;
contents.heap_allocated = false;
contents.cachable = false;
// 初始化 Block
Block data_block(contents);
std::unique_ptr iter(data_block.NewIterator(Options().comparator));
// 遍历数据块中的键值对
for (iter->SeekToFirst(); iter->Valid(); iter->Next()) {
const Slice& key = iter->key();
const Slice& value = iter->value();
// 检查值是否大于阈值
if (value.size() > min_blob_size) {
// 将值存储到 blobfile 中
Status status = blobfile->Put(key, value);
if (!status.ok()) {
r->status = status;
}
}
}
}
WriteBlock(&r->data_block, &r->pending_handle); //将数据块写入文件,并获取数据块的句柄。
if (ok()) {
r->pending_index_entry = true;
r->status = r->file->Flush(); //刷新
}
if (r->filter_block != nullptr) {
r->filter_block->StartBlock(r->offset);
}
}
```
#### 3.2.2 BlobFile数据结构
kv分离相关配置参数,均支持动态调节。在和有flush函数的文件table_builder.cc想同文件夹下创建blob_file.cc和.h文件,创建相关数据结构:
```
enable_blob_files: 是否开启KV分离。
min_blob_size: KV分离阈值,大于等于该阈值的value在Flush/Compaction时写到Blob文件。
blob_file_size: Blob文件大小。
blob_compression_type: blob文件压缩算法,每个blobfile使用相同的压缩算法。
enable_blob_garbage_collection: 设置该值之后,引擎会在compaction时重写遇到的位于
最老的一批Blob文件中的value到新的Blob文件。
blob_garbage_collection_age_cutoff: 定义旧的Blob文件的阈值,默认为0.25,
表示所有Blob文件中最先生成的25% Blob文件即为旧的Blob文件。
blob_garbage_collection_force_threshold: 引擎主动GC的一个阈值。除了在compaction过程中
重写老的blob value以外,引擎还支持主动发起GC。当最旧的一批blob文件garbage所占比值>=该值,
会触发一次compaction清理blob文件。
blob_compaction_readahead_size: 从blob文件中预读数据大小。如果设置了该值,会在compaction
中预读blob文件,预读大小为blob_compaction_readahead_size。
```
具体实现:
```
key_value_separated_: 是否开启KV分离。
min_blob_size: KV分离阈值,大于等于该阈值的value在Flush/Compaction时写到Blob文件。
blob_num: Blob文件大小。
bfid:文件id
offset:偏移量
```
blob_file.h :
```
#ifndef LEVELDB_BLOB_FILE_H_
#define LEVELDB_BLOB_FILE_H_
#include
#include "leveldb/status.h"
#include "leveldb/slice.h"
#include "leveldb/env.h"
namespace leveldb {
namespace blob {
class BlobFile {
public:
explicit BlobFile(WritableFile* dest);
BlobFile(WritableFile* dest, uint64_t dest_length);
~BlobFile();
// 添加一条记录,记录写入的偏移量
Status AddRecord(const Slice& key, const Slice& value, uint64_t& offset);
private:
WritableFile* dest_; // 用于写入数据的目标文件
uint64_t head_; // 当前写入位置的偏移量
uint64_t bfid_; // 用于标识 BlobFile 的唯一 ID
// uint64_t head_; // 当前写入文件的偏移量
Status EmitDynamicRecord(const Slice& key, const Slice& value, uint64_t& offset);
};
} // namespace blob
} // namespace leveldb
#endif // LEVELDB_BLOB_FILE_H_
```
### 3.3 写
实现`TableBuilder`的`Flush`写操作,当`DBImpl::key_value_separated_`开启时,遍历数据块键值对,大于`min_blob_size`的`value`存入`BlobFile`并记录偏移量和文件 ID,更新`value`为编码后的偏移量和 ID,小于阈值的`value`直接处理,最后将数据块写入文件并执行相关刷新及过滤操作,`BlobFile`通过特定格式记录键值对并更新偏移量。
table_builder.cc :
```
void TableBuilder::Flush() {
Rep* r = rep_;
assert(!r->closed);
if (!ok()) return;
if (r->data_block.empty()) return; //朴,正常判断
assert(!r->pending_index_entry);
if (DBImpl::key_value_separated_) {
// 这里获取数据块内容并初始化 Block 对象,朴
Slice block_content = r->data_block.Finish();
BlockContents contents;
contents.data = block_content;
contents.heap_allocated = false;
contents.cachable = false;
Rep* new_rep = new Rep(r->options, r->file); // 创建一个新的 Rep 实例
new_rep->offset = r->offset; // 新的 offset 初始化为当前的 offset
new_rep->num_entries = r->num_entries;
// 初始化 Block
Block data_block(contents);
leveldb::WritableFile* dest = nullptr;
leveldb::blob::BlobFile blobfile(dest); // 可以动态生成文件名以防止重复 // 初始化 BlobFile 对象,朴
leveldb::WritableFile* file;
int bfid = DBImpl::NewBlobNum(); // 生成唯一的 blobfile id
std::unique_ptr iter(data_block.NewIterator(Options().comparator));
// 遍历数据块中的键值对
for (iter->SeekToFirst(); iter->Valid(); iter->Next()) {
const Slice& key = iter->key();
const Slice& value = iter->value();
// 检查值是否大于阈值
if (value.size() > min_blob_size) {
// 将值存储到 blobfile 中
uint64_t offset; // 局部变量存储偏移量
Status status = blobfile.AddRecord(key, value, offset);
if (!status.ok()) {
r->status = status;
}
// 这里修改 value,存储 Blob 的 offset 和 bfid
std::string new_value = EncodeBlobValue(offset, bfid);
new_rep->data_block.Add(key, Slice(new_value));
}
else{
// 不需要 Blob 存储,直接处理普通值
new_rep->data_block.Add(key, value);
}
}
}
WriteBlock(&r->data_block, &r->pending_handle); //将数据块写入文件,并获取数据块的句柄。
if (ok()) {
r->pending_index_entry = true;
r->status = r->file->Flush(); //刷新
}
if (r->filter_block != nullptr) {
r->filter_block->StartBlock(r->offset);
}
}
std::string TableBuilder::EncodeBlobValue(uint64_t offset, int bfid) {
// 自定义方法:编码新的 Blob 值
std::string result;
// 为 result 分配空间
result.resize(8 + 4); // 64位 (8字节) + 32位 (4字节)
// 将 offset 和 bfid 编码成一个新的值
std::string result;
EncodeFixed64(&result[0], offset); // 编码 offset
EncodeFixed32(&result[8], bfid); // 编码 bfid
return result;
}
```
blob_file.cc :
```
#include "table/blob_file.h"
#include "util/coding.h"
#include "util/crc32c.h"
#include
namespace leveldb {
namespace blob {
BlobFile::BlobFile(WritableFile* dest) : dest_(dest), head_(0) {}
BlobFile::BlobFile(WritableFile* dest, uint64_t dest_length)
: dest_(dest), head_(dest_length) {}
BlobFile::~BlobFile() = default;
Status BlobFile::AddRecord(const Slice& key, const Slice& value, uint64_t& offset) {
// 动态写入记录,返回写入的偏移量
return EmitDynamicRecord(key, value, offset);
}
Status BlobFile::EmitDynamicRecord(const Slice& key, const Slice& value, uint64_t& offset) {
// 记录头部,包括 key 和 value 的长度
char header[8]; // 4 字节 key 长度 + 4 字节 value 长度
uint32_t key_size = static_cast(key.size());
uint32_t value_size = static_cast(value.size());
// 编码 key 和 value 长度
EncodeFixed32(header, key_size);
EncodeFixed32(header + 4, value_size);
// 写入头部
Status s = dest_->Append(Slice(header, sizeof(header)));
if (!s.ok()) {
return s;
}
// 写入 key 和 value 数据
s = dest_->Append(key);
if (!s.ok()) {
return s;
}
s = dest_->Append(value);
if (!s.ok()) {
return s;
}
// 刷新文件到磁盘
s = dest_->Flush();
if (!s.ok()) {
return s;
}
// 更新偏移量
offset = head_;
head_ += sizeof(header) + key_size + value_size;
return Status::OK();
}
} // namespace blob
} // namespace leveldb
```
### 3.4 读
仿照写过程,实际可能有别的问题,例如增加blob的参数。读操作需要从 SST 文件和 Blob 文件中获取数据,考虑到持久化、恢复和并发等问题。在实现中,要确保数据的一致性和完整性,同时尽量优化性能。
在`table_builder.cc`中添加读取函数:
```
class DBImpl {
public:
static bool key_value_separated_;
static int NewBlobNum();
// 其他成员变量和函数...
private:
static std::mutex read_mutex_;
};
std::string TableBuilder::DecodeBlobValue(const Slice& stored_value) {
uint64_t offset;
int bfid;
DecodeFixed64(stored_value.data(), &offset);
DecodeFixed32(stored_value.data() + 8, &bfid);
// 从Blob文件中读取实际的value
leveldb::SequentialFile* blob_file;
Status s = env_->NewSequentialFile(BlobFileName(bfid), &blob_file);
if (!s.ok()) {
return "";
}
s = blob_file->Skip(offset);
if (!s.ok()) {
delete blob_file;
return "";
}
char header[8];
s = blob_file->Read(header, sizeof(header), nullptr);
if (!s.ok()) {
delete blob_file;
return "";
}
uint32_t key_size, value_size;
DecodeFixed32(header, &key_size);
DecodeFixed32(header + 4, &value_size);
std::string blob_value;
blob_value.resize(value_size);
s = blob_file->Read(blob_value.data(), value_size, nullptr);
if (!s.ok()) {
delete blob_file;
return "";
}
delete blob_file;
return blob_value;
}
Status TableBuilder::Read(const Slice& key, std::string* value) {
Rep* r = rep_;
assert(!r->closed);
{
std::lock_guard guard(DBImpl::read_mutex_);
if (DBImpl::key_value_separated_) {
// 从SST文件中查找key
BlockContents contents;
// 从SST文件中获取对应key的数据块内容并初始化Block对象
//contents = 获取对应key的数据块内容();
Block data_block(contents);
std::unique_ptr iter(data_block.NewIterator(Options().comparator));
iter->Seek(key);
if (iter->Valid() && iter->key() == key) {
Slice stored_value = iter->value();
if (stored_value.size() == 12) {
*value = DecodeBlobValue(stored_value);
} else {
*value = std::string(stored_value.data(), stored_value.size());
}
} else {
return Status::NotFound("Key not found");
}
} else {
// 未开启KV分离,直接从SST文件中读取
}
}
return Status::OK();
}
```
### 3.5 合并
#### (1) ST 文件合并
在 LevelDB 的常规 SST 文件合并过程中,会涉及到多个 SST 文件的整合。在 KV 分离的情况下,需要额外处理 Blob 文件的引用。
- 当进行 SST 文件合并时,遍历所有参与合并的 SST 文件中的键值对。对于键值对中的值,如果是 Blob 引用(根据值的长度或者特定标识判断),则需要根据引用从相应的 Blob 文件中获取实际值。
- 对于 Blob 文件,在合并过程中有两种处理方式:
- **保持不变**:这种方式下,SST 文件合并时,Blob 文件中的数据无需重写,从而降低写放大。但随着时间推移,可能会导致空间放大,因为旧的 Blob 文件不会被清理,其中可能包含已删除或被更新键对应的值。
- **开启 Blob 文件的 Compaction**:在这种方式下,在 SST 文件合并期间,对于需要保留的键,从旧的 Blob 文件中读取其对应的值,然后将这些值重新写入到一个新的 Blob 文件中。同时,更新新生成的 SST 文件,使其引用新的 Blob 文件中的值索引。完成后,旧的 Blob 文件可以在适当的时候异步删除(前提是没有其他 SST 文件引用它)。
#### (2) Blob 文件合并
- 当选择开启 Blob 文件的 Compaction 时,在 SST 文件合并过程中,为每个参与合并的 SST 文件中的 Blob 引用维护一个映射表,记录每个 Blob 引用对应的键。
- 遍历所有参与合并的 SST 文件,对于每个 Blob 引用,根据映射表判断该键是否需要保留(例如,是否在新的 SST 文件中有对应的更新或删除操作)。如果需要保留,则从旧的 Blob 文件中读取对应的值,并写入到新的 Blob 文件中。
- 为新写入的 Blob 数据生成新的偏移量和文件 ID,更新 SST 文件中的 Blob 引用,使其指向新的 Blob 文件中的位置。
#### (3) 代码实现
在table_builder.cc中添加合并相关代码
```
void TableBuilder::CompactSSTAndBlobFiles() {
// 假设这里有获取参与合并的SST文件列表的逻辑
std::vector inputSSTFiles = GetInputSSTFilesForCompaction();
std::vector outputSSTFiles;
std::vector inputBlobFiles;
std::vector outputBlobFiles;
// 初始化输出Blob文件
for (size_t i = 0; i < inputBlobFiles.size(); ++i) {
leveldb::WritableFile* outputBlobDest = nullptr;
// 生成唯一的Blob文件名
std::string outputBlobFileName = GenerateUniqueBlobFileName();
env_->NewWritableFile(outputBlobFileName, &outputBlobDest);
BlobFile* outputBlobFile = new BlobFile(outputBlobDest);
outputBlobFiles.push_back(outputBlobFile);
}
// 遍历每个输入SST文件
for (SSTFile* inputSST : inputSSTFiles) {
std::unique_ptr iter(inputSST->NewIterator(Options().comparator));
std::vector> newKeyValues;
for (iter->SeekToFirst(); iter->Valid(); iter->Next()) {
const Slice& key = iter->key();
const Slice& value = iter->value();
if (DBImpl::key_value_separated_ && value.size() == 12) { // 假设Blob引用长度为12
uint64_t offset;
int bfid;
DecodeFixed64(value.data(), &offset);
DecodeFixed32(value.data() + 8, &bfid);
// 从旧的Blob文件中读取实际值
BlobFile* inputBlobFile = inputBlobFiles[bfid];
std::string actualValue = ReadValueFromBlobFile(inputBlobFile, offset);
// 判断是否需要保留该键值对
if (ShouldKeepKeyValue(key, actualValue)) {
// 将实际值写入新的Blob文件
uint64_t newOffset;
BlobFile* outputBlobFile = outputBlobFiles[bfid];
Status status = outputBlobFile->AddRecord(key, Slice(actualValue), newOffset);
if (!status.ok()) {
// 处理错误
continue;
}
// 更新SST文件中的Blob引用
std::string newBlobValue = EncodeBlobValue(newOffset, bfid);
newKeyValues.emplace_back(key, Slice(newBlobValue));
}
} else {
// 非Blob引用,直接处理
if (ShouldKeepKeyValue(key, value)) {
newKeyValues.emplace_back(key, value);
}
}
}
// 创建新的SST文件并写入更新后的键值对
SSTFile* newSSTFile = CreateNewSSTFile();
for (const auto& pair : newKeyValues) {
newSSTFile->Add(pair.first, pair.second);
}
outputSSTFiles.push_back(newSSTFile);
}
// 清理旧的Blob文件(假设无其他引用)
for (BlobFile* inputBlobFile : inputBlobFiles) {
delete inputBlobFile;
}
}
std::string TableBuilder::ReadValueFromBlobFile(BlobFile* blobFile, uint64_t offset) {
char header[8];
Status s = blobFile->Seek(offset);
if (!s.ok()) {
return "";
}
s = blobFile->Read(header, sizeof(header), nullptr);
if (!s.ok()) {
return "";
}
uint32_t key_size, value_size;
DecodeFixed32(header, &key_size);
DecodeFixed32(header + 4, &value_size);
std::string actualValue;
actualValue.resize(value_size);
s = blobFile->Read(actualValue.data(), value_size, nullptr);
if (!s.ok()) {
return "";
}
return actualValue;
}
bool TableBuilder::ShouldKeepKeyValue(const Slice& key, const Slice& value) {
// 判断键值对是否需要保留的逻辑,例如根据删除标记或版本号等
return true;
}
```
### 3.6 垃圾回收
#### (1) 确定垃圾数据
- 借助类似 RocksDB 的`TablePropertiesCollector`特性(虽然 LevelDB 原生没有直接类似的,但可自行实现类似功能),在每次 SST 文件 Compaction 完成后,搜集 SST 文件上的 Blob 文件信息。
- 记录每个 Blob 文件在 Compaction 前后的使用情况,通过对比参与 Compaction 的输入和输出 SST 文件中的 Blob 文件信息,计算出每个 Blob 文件中被丢弃的数据大小,即垃圾数据大小。
#### (2) 选择回收对象并执行回收
- 对所有 Blob 文件按垃圾数据大小进行排序,优先选择垃圾数据最多的 Blob 文件进行 GC。
- 对于选定的 Blob 文件,在下次 SST 文件 Compaction 时,开启 Blob 文件的 Compaction 过程。在这个过程中,重新写入 Blob 文件,只保留仍被引用的数据,丢弃垃圾数据。
- 更新 SST 文件中的 Blob 引用,使其指向新的 Blob 文件中的正确位置。
#### (3) 代码实现
table_builder.cc:
```
void TableBuilder::GarbageCollectBlobFiles() {
// 获取所有Blob文件及其垃圾数据大小
std::map blobFileGarbageSizes = CalculateBlobFileGarbageSizes();
// 按垃圾数据大小排序
std::vector> sortedBlobFiles(blobFileGarbageSizes.begin(), blobFileGarbageSizes.end());
std::sort(sortedBlobFiles.begin(), sortedBlobFiles.end(), [](const auto& a, const auto& b) {
return a.second > b.second;
});
// 选择垃圾数据最多的Blob文件进行GC
if (!sortedBlobFiles.empty()) {
int bfidToGC = sortedBlobFiles[0].first;
BlobFile* inputBlobFile = GetBlobFile(bfidToGC);
// 创建新的Blob文件
leveldb::WritableFile* outputBlobDest = nullptr;
std::string outputBlobFileName = GenerateUniqueBlobFileName();
env_->NewWritableFile(outputBlobFileName, &outputBlobDest);
BlobFile* outputBlobFile = new BlobFile(outputBlobDest);
// 遍历所有SST文件,重新写入需要保留的数据
std::vector allSSTFiles = GetAllSSTFiles();
for (SSTFile* sstFile : allSSTFiles) {
std::unique_ptr iter(sstFile->NewIterator(Options().comparator));
for (iter->SeekToFirst(); iter->Valid(); iter->Next()) {
const Slice& key = iter->key();
const Slice& value = iter->value();
if (DBImpl::key_value_separated_ && value.size() == 12) { // 假设Blob引用长度为12
uint64_t offset;
int bfid;
DecodeFixed64(value.data(), &offset);
DecodeFixed32(value.data() + 8, &bfid);
if (bfid == bfidToGC) {
std::string actualValue = ReadValueFromBlobFile(inputBlobFile, offset);
if (ShouldKeepKeyValue(key, actualValue)) {
uint64_t newOffset;
Status status = outputBlobFile->AddRecord(key, Slice(actualValue), newOffset);
if (!status.ok()) {
// 处理错误
continue;
}
// 更新SST文件中的Blob引用
std::string newBlobValue = EncodeBlobValue(newOffset, bfid);
sstFile->UpdateBlobReference(key, Slice(newBlobValue));
}
}
}
}
}
// 清理旧的Blob文件
delete inputBlobFile;
}
}
std::map TableBuilder::CalculateBlobFileGarbageSizes() {
// 这里实现计算每个Blob文件垃圾数据大小的逻辑,类似之前提到的对比输入输出SST文件的Blob信息
std::map blobFileGarbageSizes;
return blobFileGarbageSizes;
}
BlobFile* TableBuilder::GetBlobFile(int bfid) {
// 根据bfid获取BlobFile对象
return nullptr;
}
```
## 四、功能设计v2.0
在实现第一版之后,我们发现有很多困难,这个策略虽然适合大规模分布式数据存储与计算,能支持高并发、分布式事务等,但存在复杂度高、小规模存储内存使用高及可定制性低、需精细参数配置与优化等问题。于是我们转变了策略,重新考虑WiscKey 这篇论文的思路和实现方式。
而 WiscKey 策略的提出,旨在优化 LSM - Tree 的写放大问题,这与我们的实验目标高度契合。相较于其他如 LSM - trie 和 PebblesDB 等优化方案,WiscKey 具有通用性强、效果显著且原理简单易懂的特点,有效解决了 LSM - Tree 因 compaction 时重写大量数据(key 和 value)导致的写放大问题,尤其在现实中常见的 ksize 远小于 vsize 场景下,优化效果更为突出。
此外,这种策略还有诸多好处。例如,LSM - Tree Compaction 无需重写 value,大幅减小写放大;LSM - Tree 不存储 value,体积变小,一个 block 能存储更多 key,有利于减少读 I/O;体积变小后,cache 效果更佳,LSM - Tree 上层基本可缓存于内存。
但是这种策略会造成一些其他影响,如 range query 转化为多次 vlog 随机读,需依赖后台线程预读缓存来优化性能,且不同场景下效果有差异;key 和 value 分开存储后的一致性保障,虽通过先写 vlog 再写 LSM - Tree 及刷盘策略解决,但存在两次刷盘开销(可通过 WAL 和 vlog 合并优化);vlog 的垃圾回收也需谨慎处理,无论是扫 LSM - Tree 还是扫 vlog 都各有优劣。然而,我们认为这些问题均可通过合理的设计与优化解决,且相较于其带来的显著优势,这些挑战是值得面对与克服的。
#### 功能设计示意图
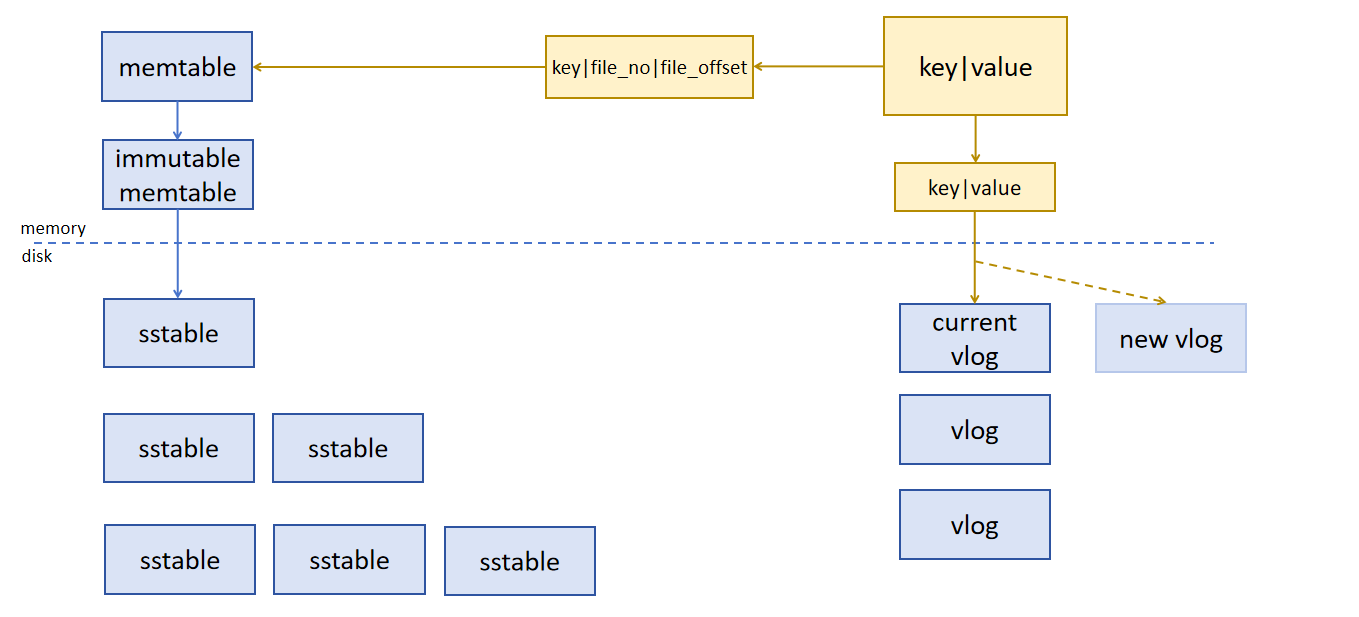
图12 插入键值对过程
向当前 vlog 的尾端插入 key 和 value ,将 vlog 的编号 (file_no) 和新条目在 vlog 中的偏移量 (file_offset) 整合成 vptr,向 memtable 中写入 key 和 vptr 。当 current vlog 的大小达到一定阈值且磁盘IO繁忙程度低于指定阈值时,创建新的 vlog 。
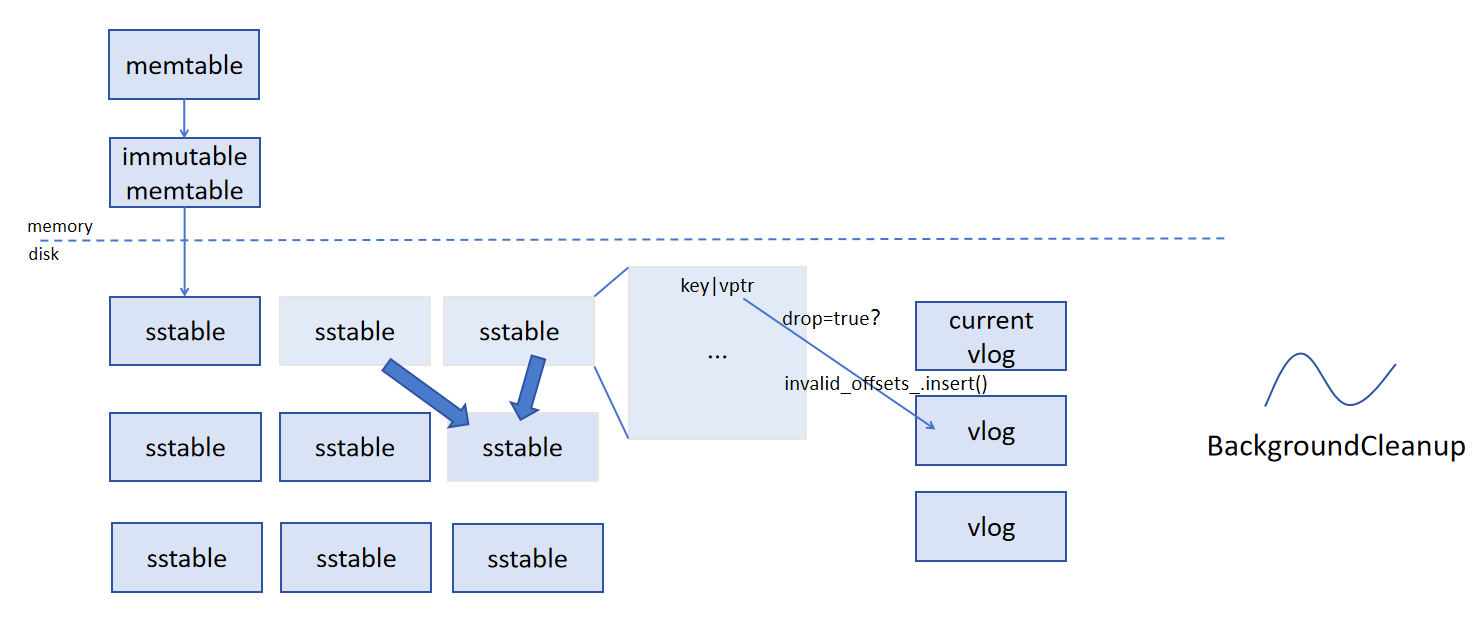
图13 垃圾回收 (GC) 过程
在进行 compaction 的时候会遍历 sstable 中的每一个键值对,当 drop 变量为 true 时表明该键值对已失效。根据 vptr 到 vlog_manager 中查询存放相应的 value 所在的 vlog 文件,修改其 invalid_offsets_ 集合。同时,在后台有一个线程 BackgroundCleanup 定时扫描所有 vlog ,当 vlog 中的所有条目都已失效时,会删除该 vlog 文件,从而实现垃圾回收。
### 五、接口设计 v2.0
#### 相关接口
#### 1. vlog_writer.h
```
VWriter::AddRecord:向Vlog写入一个Record
VWriter::Flush:实现WritableFile的刷盘
```
#### 2. vlog_reader.h
```
VReader::ReadRecord:从文件指定偏移位置读取条目
VReader::ReadKV:从文件指定位置读取value
```
#### 3. vlog_manager.h
管理vlog文件,维护存在的文件映射表
```
VlogManager::AddVlogFile:新建一个vlog文件
VlogManager::GetVlogFile:获得指定vlogfile_number的vlog文件
VlogManager::MarkVlogValueInvalid:标记指定vlog文件指定偏移量的value无效
VlogManager::GetSequentialFile:通过映射获得writablefile对应的sequentialfile
VlogManager::IncrementTotalValueCount:增加文件条目计数器
VlogManager::CleanupInvalidVlogFiles:检查所有的vlog文件是否需要被回收
VlogManager::RemoveVlogFile:删除无效的vlog文件
```
#### 4. vlog_converter.h
```
VlogConverter::GetVptr:根据file_no和file_offset实现vptr的包装
VlogConverter::DecodeVptr:实现vptr的解析
```
#### 5. db_impl.h:
增加若干辅助函数
```
DBImpl::StartBackgroundCleanupTask:后台一个自动GC的线程
DBImpl::GetKVSepType:获取KV分离的参数类型
DBImpl::WriteValueIntoVlog:写入Vlog
DBImpl::ReadValueFromVlog:从Vlog中读
DBImpl::IsDiskBusy:判断磁盘IO是否繁忙
```
#### 6. options_.h:
增加KV分离时机选项。
## 六、代码设计 v2.0
### 1. Vlog_Write
主要围绕根据不同的键值分离类型,灵活处理键值对的存储方式,以优化存储性能和资源利用。
#### 1.1 Put
首先,在 `Put` 方法中,添加根据 `options_.kvSepType` 来决定键值对存储逻辑的入口。
对于 `noKVSep` 和 `kVSepBeforeSSD` 这两种情况,意味着不需要在当前逻辑下进行特殊的键值分离操作,所以直接复用原有的 `DB::Put` 方法,将键值对以常规方式存入数据库。这样做既保证了代码的简洁性,又能在不需要键值分离时维持原有的存储性能和兼容性。
而当 `kvSepType` 为 `kVSepBeforeMem` 时,就需要执行键值分离逻辑。这是因为我们希望在数据进入内存之前,就将值分离存储到 VLog 中,以达到优化存储结构的目的。此时,先调用 `WriteValueIntoVlog` 方法,将键值对写入 VLog 并获取值在 VLog 中的指针 `vptr`。这个指针将替代原始值,用于后续在数据库中的存储。写入 VLog 后,立即调用 `vlog_->Flush()` 确保数据及时持久化,防止数据丢失。最后,再使用 `DB::Put` 方法将键和 `vptr` 插入数据库,完成整个存储过程。
```
Status DBImpl::Put(const WriteOptions& o, const Slice& key, const Slice& val) {
// Convert value to vptr if need.
if(this->options_.kvSepType == noKVSep || this->options_.kvSepType == kVSepBeforeSSD){
return DB::Put(o, key, val);
}
else if(this->options_.kvSepType == kVSepBeforeMem){
char buf[20];
Slice vptr;
Status s = WriteValueIntoVlog(key, val, buf, vptr); //朴,写
if(!s.ok()) return s;
s = vlog_-> Flush();
if(!s.ok()) return s;
return DB::Put(o, key, vptr);
}
return Status::Corruption("Invalid kvSepType.");
}
```
#### 1.2 WriteValueIntoVlog
在 `WriteValueIntoVlog` 方法中,首要任务是检查 VLog 文件的使用情况。通过 `vlogfile_offset_` 和 `options_.vlog_file_size` 的比较,判断当前 VLog 文件是否已满。如果已满,就需要创建新的 VLog 文件。这涉及到使用环境对象 `options_.env` 创建新的可写文件和顺序读文件,更新相关的文件管理模块,包括删除旧的写入器和文件对象,将新的读文件添加到文件管理器 `vmanager_` 中,重置写入器和文件偏移量等操作,确保 VLog 文件的连续性和可管理性。
接下来,为了将键值对写入 VLog,先通过 `PutLengthPrefixedSlice` 函数将键和值分别添加到临时字符串 `tmp_vrec` 中,并在前面加上它们的长度前缀。这样的编码方式有助于后续在读取时准确解析键值对。然后,调用 `vlog_->AddRecord` 方法将这个临时字符串作为一条记录写入 VLog,并获取写入的大小。
最后,利用 `vconverter_` 的 `GetVptr` 方法,根据当前的 VLog 文件编号、偏移量以及提供的缓冲区 `buf`,生成值在 VLog 中的指针 `vptr`。同时,更新 `vlogfile_offset_`,记录下本次写入导致的偏移量增加。
```
Status DBImpl::WriteValueIntoVlog(const Slice& key, const Slice& val, char* buf, Slice& vptr){ //朴,写
//写VLog
Status s;
if(vlogfile_offset_ >= options_.vlog_file_size){
WritableFile* newfile;
SequentialFile* readfile;
s = options_.env->NewWritableFile(VlogFileName(dbname_, vlogfile_number_ + 1), &newfile);
if(!s.ok()) return s;
s = options_.env->NewSequentialFile(VlogFileName(dbname_, vlogfile_number_ + 1), &readfile);
if(!s.ok()) return s;
//更新相应的模块
delete vlog_;
delete vlogfile_;
vmanager_->AddVlogFile(vlogfile_number_ + 1, readfile);
vlogfile_ = newfile;
vlog_ = new vlog::VWriter(vlogfile_);
++vlogfile_number_;
vlogfile_offset_ = 0;
}
int write_size = 0;
std::string tmp_vrec;
PutLengthPrefixedSlice(&tmp_vrec, key);
PutLengthPrefixedSlice(&tmp_vrec, val);
s = vlog_-> AddRecord(Slice(tmp_vrec), write_size);
if(!s.ok()) return s;
//将val替换为vptr.
vptr = vconverter_->GetVptr(vlogfile_number_, vlogfile_offset_, buf);
vlogfile_offset_ += write_size; //朴
return s;
}
```
### 2. Vlog_Read
#### 2.1 Get
在 `Get` 方法里处理 KV 分离相关逻辑时,核心目标是确保在不同的 KV 分离配置下,都能准确获取到完整的键值对数据。
在获取键值对之后,针对不同的 `options_.kvSepType` 进行特殊处理。
- **`kVSepBeforeSSD` 情况**:当 `options_.kvSepType` 为 `kVSepBeforeSSD` 时,意味着数据在落盘到 SSD 之前就进行了键值分离操作。在这种情况下,从常规存储结构中获取到的值实际上可能只是一个指向 VLog 中真实值的指针(vptr)。所以,需要调用 `ReadValueFromVlog` 方法,利用这个 `vptr` 从 VLog 中读取实际的键值对数据,从而更新 `value`,使其包含完整的用户所需值。这样做是因为在这种 KV 分离策略下,数据的存储结构发生了变化,必须通过额外的步骤从 VLog 中还原出完整数据。
- **`kVSepBeforeMem` 情况**:当 `options_.kvSepType` 为 `kVSepBeforeMem` 时,同样面临从 VLog 中获取真实值的需求。即使在前面的查找过程中已经从存储结构中获取到了一些数据,但由于这种 KV 分离策略在数据进入内存之前就将值分离到了 VLog 中,所以获取到的值依然可能只是 `vptr`。因此,再次调用 `ReadValueFromVlog` 方法,依据 `vptr` 从 VLog 中读取实际的键值对并更新 `value`。这一步骤保证了无论数据在哪个阶段进行了 KV 分离,都能正确获取到完整的键值对。
在整个过程中,对 `kvSepType` 的判断以及相应的从 VLog 读取数据的操作,都是紧密围绕 KV 分离的存储结构变化而设计的,旨在确保系统在不同的 KV 分离配置下,读取操作的准确性和一致性。
```
Status DBImpl::Get(const ReadOptions& options, const Slice& key,
std::string* value) {
Status s;
MutexLock l(&mutex_);
SequenceNumber snapshot;
if (options.snapshot != nullptr) {
snapshot =
static_cast(options.snapshot)->sequence_number();
} else {
snapshot = versions_->LastSequence();
}
MemTable* mem = mem_;
MemTable* imm = imm_;
Version* current = versions_->current();
mem->Ref();
if (imm != nullptr) imm->Ref();
current->Ref();
bool have_stat_update = false;
Version::GetStats stats;
// Unlock while reading from files and memtables
{
mutex_.Unlock();
// First look in the memtable, then in the immutable memtable (if any).
LookupKey lkey(key, snapshot);
if (mem->Get(lkey, value, &s)) {
// Done
} else if (imm != nullptr && imm->Get(lkey, value, &s)) {
// Done
} else {
s = current->Get(options, lkey, value, &stats);
have_stat_update = true;
//if KVSeq, Need Decode
if(options_.kvSepType == kVSepBeforeSSD){
std::string tmp_key;
Status s = ReadValueFromVlog(&tmp_key, value, value);
if(!s.ok()) return s;
}
}
mutex_.Lock();
}
if (have_stat_update && current->UpdateStats(stats)) {
MaybeScheduleCompaction();
}
mem->Unref();
if (imm != nullptr) imm->Unref();
current->Unref();
//Decode vptr if Need Kvsep
if(options_.kvSepType == kVSepBeforeMem){
std::string tmp_key;
Status s = ReadValueFromVlog(&tmp_key, value, value);
if(!s.ok()) return s;
}
return s;
}
```
#### 2.2 ReadValueFromVlog
对于 `ReadValueFromVlog` 方法,其设计是为了配合 KV 分离机制,准确地从 VLog 中读取被分离存储的值。
解析指针:
- **类型转换**:将传入的 `vptr` 转换为 `Slice` 类型 `Slice encoded_vptr = Slice(*vptr)`,这是为后续解析操作做准备。`Slice` 类型提供了方便的字节序列处理方式,使得我们能够更灵活地操作 `vptr` 所包含的信息,为解析出 VLog 文件编号和偏移量奠定基础。
- **解析关键信息**:调用 `vconverter_->DecodeVptr` 方法,从 `encoded_vptr` 中提取出 VLog 文件编号 `vlogfile_number` 和文件偏移量 `vlogfile_offset`。在 KV 分离的存储体系中,`vptr` 承载了定位 VLog 中实际值的关键信息,通过 `vconverter_` 模块的解码功能,我们能够获取到这些关键位置信息。若解析过程失败,说明 `vptr` 可能存在错误或损坏,此时直接返回错误状态,以避免后续基于错误信息的无效操作。
获取 VLog 文件并读取:
- **定位 VLog 文件**:使用 `vmanager_->GetVlogFile(vlogfile_number)` 获取对应的 VLog 文件 `SequentialFile* vlog_file`。在 KV 分离的架构下,`vmanager_` 负责管理所有的 VLog 文件,通过文件编号可以准确找到存储实际值的目标 VLog 文件。若获取文件失败,这很可能意味着 VLog 文件系统出现问题,比如文件丢失或损坏,此时返回数据损坏的错误状态,以提示系统可能存在严重的数据问题。
- **创建读取工具**:创建 `vlog::VReader` 对象 `vreader`,该对象专门用于从 VLog 文件中读取数据。它封装了针对 VLog 文件格式的读取逻辑,为从 VLog 中准确读取键值对提供了统一且便捷的接口,使得代码结构更加清晰,易于维护和扩展。
- **读取键值对**:调用 `vreader.ReadKV` 方法,依据之前解析得到的偏移量 `vlogfile_offset` 从 VLog 文件中读取键值对,并分别存储到 `key` 和 `val` 中。`ReadKV` 方法依据 VLog 文件特定的存储格式,从指定偏移位置准确读取数据,并将其解析为键值对形式,从而完成从 VLog 中获取被分离存储的值的关键步骤。
返回读取操作的状态 `s`,如果前面的所有操作都成功执行,状态为 `OK`,表示成功从 VLog 中读取到了所需的键值对数据。若在任何一个步骤中出现错误,如指针解析失败、VLog 文件获取失败等,状态将包含相应的错误信息。通过返回状态,上层调用函数(如 `Get` 方法)能够根据具体情况进行处理,比如向用户反馈错误、进行重试逻辑或者采取其他应对措施,确保整个系统在 KV 分离存储模式下的健壮性和稳定性。
```
Status DBImpl::ReadValueFromVlog(std::string* key, std::string* val, std::string* vptr){ //读,朴
Status s;
Slice encoded_vptr = Slice(*vptr);
uint64_t vlogfile_number;
uint64_t vlogfile_offset;
s = vconverter_->DecodeVptr(&vlogfile_number, &vlogfile_offset, &encoded_vptr);
if(!s.ok()) return s;
SequentialFile* vlog_file = vmanager_->GetVlogFile(vlogfile_number);
if(vlog_file == nullptr) return Status::Corruption("Failed to find vlog files.");
vlog::VReader vreader = vlog::VReader(vlog_file);
vreader.ReadKV(vlogfile_offset, key, val);
return s;
}
```
### 3. GC垃圾回收
在 `drop` 为 `true` 时标记 `vlog` 文件中对应的 `value` 为无效
合并过程中检测到 `drop == true` 时,检查 `options_.kvseptype` 是否启用 KV 分离,并根据 `ikey` 的 `vptr`(对应的 VLog 文件编号和偏移量)将其标记为无效。
修改 `DBImpl::DoCompactionWork` 中的相关代码:
```
if (drop) {
// 标记为无效的逻辑
if (options_.kvseptype) { // 如果启用了 KV 分离
Slice vptr = input->value(); // 获取指向 VLog 的 vptr
uint64_t vlogfile_number, vlogfile_offset;
Status s = vconverter_->DecodeVptr(&vlogfile_number, &vlogfile_offset, &vptr);
if (s.ok()) {
// 更新 vmanager_,标记该 offset 无效
vmanager_->MarkVlogValueInvalid(vlogfile_number, vlogfile_offset);
}
}
continue; // 跳过当前记录
}
```
在 `vmanager_` 中新增方法:
```
void MarkVlogValueInvalid(uint64_t vlogfile_number, uint64_t offset) {
auto vlog_file = GetVlogFile(vlogfile_number);
if (vlog_file) {
vlog_file->MarkValueInvalid(offset); // 调用具体文件的标记逻辑
}
}
```
设计一个后台任务周期性扫描所有 VLog 文件,检查是否所有 `value` 都已标记为无效。如果是,则删除对应的文件。
启动后台线程:
```
void DBImpl::StartBackgroundCleanupTask() {
std::thread([this]() {
while (!shutting_down_.load(std::memory_order_acquire)) {
vmanager_->CleanupInvalidVlogFiles();
std::this_thread::sleep_for(std::chrono::seconds(60)); // 每分钟检查一次
}
}).detach();
}
```
在 `vmanager_` 中新增清理逻辑:
```
void CleanupInvalidVlogFiles() {
for (const auto& vlog_pair : vlog_files_) {
uint64_t vlogfile_number = vlog_pair.first;
auto vlog_file = vlog_pair.second;
if (vlog_file->AllValuesInvalid()) { // 检查文件内所有值是否无效
RemoveVlogFile(vlogfile_number); // 删除 VLog 文件
}
}
}
```
在删除文件时,还需要在 `vmanager_` 中更新状态:
```
void RemoveVlogFile(uint64_t vlogfile_number) {
auto it = vlog_files_.find(vlogfile_number);
if (it != vlog_files_.end()) {
delete it->second; // 删除对应的 SequentialFile
vlog_files_.erase(it); // 从管理器中移除
options_.env->DeleteFile(VlogFileName(dbname_, vlogfile_number)); // 删除实际文件
}
}
```
## 七、创新点
#### 1. 在新建vlog时机上的优化:
考虑到每次对磁盘的读写操作都会受到操作系统的 I/O 调度策略影响,比如是否等待某个时间片(轮转到当前请求的 I/O 操作),合理选择新建文件的时机可能减少元数据操作对当前 I/O 的干扰,有如下优势:
**提高吞吐量**避免高 I/O 繁忙期进行文件切换,减少因调度冲突导致的性能抖动。
**优化资源使用**在磁盘空闲时执行高代价的文件切换,充分利用 I/O 带宽。
**降低延迟**避免不必要的磁盘等待时间,提升写入操作的实时性。
因此,我们期望实现当磁盘繁忙时,推迟创建新文件,优先将数据写入现有文件的逻辑。
```
bool IsDiskBusy(const std::string& device) { // 判断磁盘繁忙程度是否超过指定阈值
std::ifstream io_stat("/sys/block/" + device + "/stat");
if (!io_stat.is_open()) return false;
unsigned long read_requests, write_requests, io_in_progress;
io_stat >> read_requests >> write_requests >> io_in_progress;
io_stat.close();
// 如果当前正在处理的 I/O 请求数大于阈值,则认为磁盘繁忙
return io_in_progress > 2; // 设置一个合理的阈值
}
```
```
Status DBImpl::WriteValueIntoVlog(const Slice& key, const Slice& val, char* buf, Slice& vptr) {
Status s;
// 检查是否需要新建 VLog 文件
if (vlogfile_offset_ >= options_.vlog_file_size) {
// 判断当前 I/O 是否繁忙
if (IsDiskBusy("sda")) { // 替换 "sda" 为实际设备名
// 如果 I/O 繁忙,可以选择等待或继续写入当前文件
} else {
// 如果 I/O 空闲,立即创建新文件
// 更新相应模块
}
}
// 正常写入流程
...
}
```
#### 2. 拓展到垃圾回收时机上的优化:
在考虑垃圾回收的机制时,我们发现同样可以使用考虑磁盘IO繁忙程度的策略。在后台线程定期对vlog_manager中的vlog文件进行扫描检查的同时,为了避免在IO过度繁忙时进行垃圾回收影响前台写入和读取的速度,我们可以考虑只在磁盘较为空闲时进行垃圾回收。但由于垃圾回收频率会影响存储空间的利用率,如果推迟进行回收,就会导致无效的空间得不到利用,这实质上仍是一个时间和空间权衡的问题。
#### 原子性问题:
由于存在对vlog文件的创建、修改和删除,为了确保在并发环境下的线程安全,防止多个线程同时访问共享资源(例如 `vlogfile_`、`vlogfile_offset_` 等),从而引发数据竞争或不一致性问题,在部分操作中加入锁。
**文件切换的原子性**:
```
if (vlogfile_offset_ >= options_.vlog_file_size) {
std::unique_lock lock(vlog_mutex_);
WritableFile* newfile;
SequentialFile* readfile;
...
vlogfile_offset_ = 0;
}
```
如果没有加锁,多个线程可能同时检测到文件满的条件,导致:
- 重复创建多个新文件。
- 数据被写入不同的 `vlogfile_`,导致后续操作的混乱。
**写入操作的原子性**
```
{
std::unique_lock lock(vlog_mutex_);
Status s = vlog_->AddRecord(Slice(tmp_vrec), write_size);
if (!s.ok()) return s;
vlogfile_offset_ += write_size;
}
```
`vlog_->AddRecord` 是一个写入操作,需要对当前 `vlogfile_` 文件追加记录。如果多个线程同时调用 `AddRecord`,会导致写入的内容交叉,产生数据损坏或覆盖。
`vlogfile_offset_` 是一个共享变量,记录当前 VLog 文件的偏移。在没有加锁的情况下,多个线程可能同时更新 `vlogfile_offset_`,导致偏移值不正确,最终可能会:
- 覆盖已经写入的数据。
- 记录的偏移与实际文件内容不符,影响后续读取。
## 八、功能测试
### 1 单元测试(测试用例):
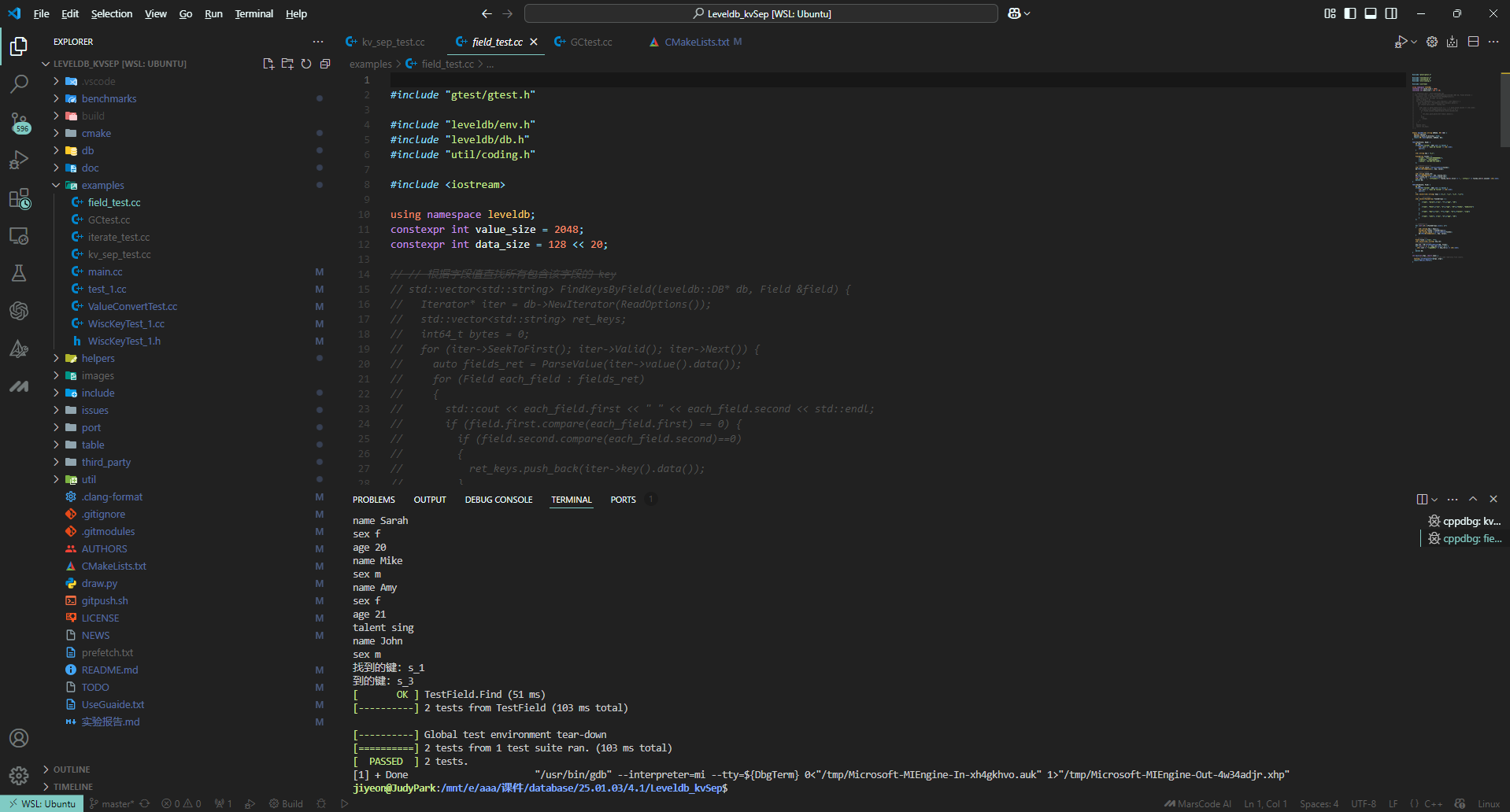
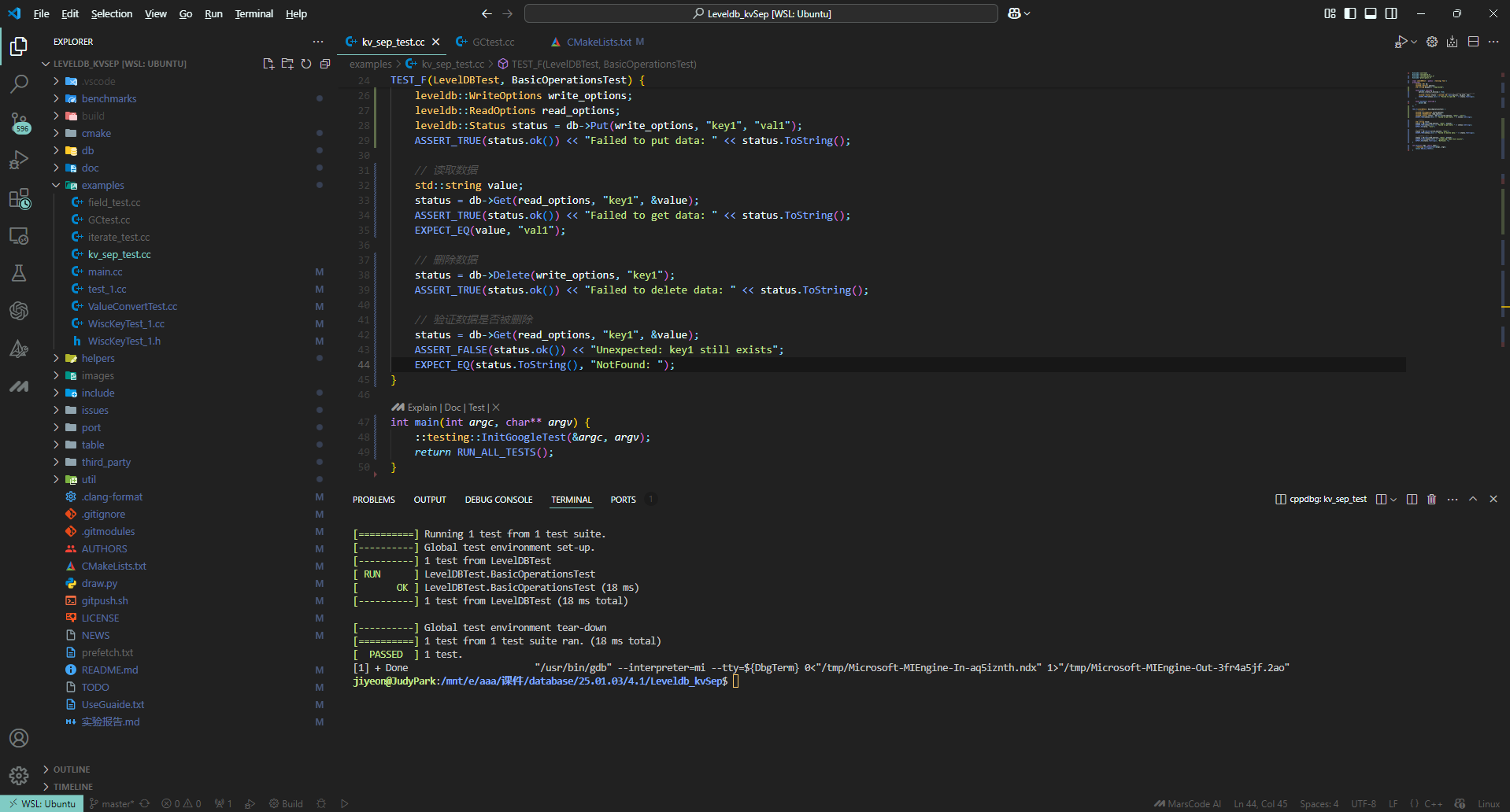
#### 1.1 字段分离-field_test.cc:
##### (1)字段插入:
插入含有字段的key value对,然后直接使用原本的Get函数获取该key对应的value,验证是否正确执行插入操作。
```
TEST(TestSchema, Insert) {
std::string key = "k_1";
FieldArray fields = {
{"name", "Customer#000000001"},
{"address", "IVhzIApeRb"},
{"phone", "25-989-741-2988"}
};
// 序列化并插入
std::string value = SerializeValue(fields);
db->Put(WriteOptions(), key, value);
// 读取并反序列化
std::string value_ret;
db->Get(ReadOptions(), key, &value_ret);
auto fields_ret = ParseValue(value_ret);
}
```
##### (2)通过字段反向查询key:
插入多个含有字段的key value对,然后通过value中的某一字段查询匹配的key值,验证反向查询功能。
```
TEST(TestSchema, Find) {
std::vector keys = {"s_1", "s_2", "s_3", "s_4"};
// 构造一组字段数组
std::vector FieldArrays = {
{
{"name", "Sarah"},{"sex", "f"},{"age", "20"}
},
{
{"name", "Mike"},{"sex", "m"},{"age", "19"},{"hobby", "badminton"}
},
{
{ name", "Amy"},{"sex", "f"},{"age", "21"},{"talent", "sing"}
},
{
{ name", "John"}, {"sex", "m"},{"age", "20"}
}
};
// 序列化并插入
for (int i=0; iPut(WriteOptions(), key, value);
}
// 构建目标字段
Field field = {"sex", "f"};
std::vector key_ret;
// 查询得到对应的key
key_ret = FindKeysByField(leveldb::DB* db, Field &field)
}
```
顺利通过测试,测试结果如下: