
Compare commits
merge into: building_data_management_systems.Xuanzhou.2024Fall.DaSE:master
building_data_management_systems.Xuanzhou.2024Fall.DaSE:ckx
building_data_management_systems.Xuanzhou.2024Fall.DaSE:main
building_data_management_systems.Xuanzhou.2024Fall.DaSE:master
building_data_management_systems.Xuanzhou.2024Fall.DaSE:pzy
pull from: building_data_management_systems.Xuanzhou.2024Fall.DaSE:ckx
building_data_management_systems.Xuanzhou.2024Fall.DaSE:ckx
building_data_management_systems.Xuanzhou.2024Fall.DaSE:main
building_data_management_systems.Xuanzhou.2024Fall.DaSE:master
building_data_management_systems.Xuanzhou.2024Fall.DaSE:pzy
525 changed files with 619 additions and 141038 deletions
Split View
Diff Options
-
+102 -0.github/workflows/build.yml
-
+2 -0.gitignore
-
+1 -1.gitmodules
-
+14 -21CMakeLists.txt
-
+31 -0CONTRIBUTING.md
-
+3 -246README.md
-
+0 -16TODO
-
+0 -5UseGuaide.txt
-
+8 -6benchmarks/db_bench.cc
-
+4 -0benchmarks/db_bench_log.cc
-
+4 -0benchmarks/db_bench_sqlite3.cc
-
+4 -0benchmarks/db_bench_tree_db.cc
-
+4 -0db/autocompact_test.cc
-
+6 -15db/builder.cc
-
+5 -2db/builder.h
-
+5 -2db/c.cc
-
+4 -0db/c_test.c
-
+1 -2db/corruption_test.cc
-
+27 -192db/db_impl.cc
-
+6 -37db/db_impl.h
-
+4 -24db/db_test.cc
-
+2 -11db/filename.cc
-
+1 -7db/filename.h
-
+0 -4db/log_test.cc
-
+4 -6db/repair.cc
-
+0 -20db/vlog_converter.cc
-
+0 -19db/vlog_converter.h
-
+0 -33db/vlog_manager.cc
-
+0 -61db/vlog_manager.h
-
+0 -58db/vlog_reader.cc
-
+0 -25db/vlog_reader.h
-
+0 -26db/vlog_writer.cc
-
+0 -26db/vlog_writer.h
-
+31 -18db/write_batch.cc
-
+1 -1db/write_batch_internal.h
-
+0 -45draw.py
-
+0 -50examples/GCtest.cc
-
+0 -28examples/ValueConvertTest.cc
-
+0 -173examples/WiscKeyTest_1.cc
-
+0 -81examples/WiscKeyTest_1.h
-
+0 -76examples/iterator_test.cc
-
+0 -43examples/kv_sep_test.cc
-
+0 -23examples/main.cc
-
+0 -25examples/test_1.cc
-
+0 -3gitpush.sh
-
+0 -8helpers/memenv/memenv.cc
-
BINimages/1.png
-
BINimages/10.png
-
BINimages/11.png
-
BINimages/12.webp
-
BINimages/13.png
-
BINimages/14.png
-
BINimages/15.png
-
BINimages/16.png
-
BINimages/2.png
-
BINimages/3.png
-
BINimages/4.png
-
BINimages/5.png
-
BINimages/6.png
-
BINimages/7.png
-
BINimages/8.png
-
BINimages/9.png
-
BINimages/GC_test.png
-
BINimages/c1.1.png
-
BINimages/c1.2.png
-
BINimages/c1.png
-
BINimages/c10.png
-
BINimages/c2.png
-
BINimages/c3.png
-
BINimages/c4.png
-
BINimages/c5.png
-
BINimages/c6.png
-
BINimages/c7.png
-
BINimages/c8.png
-
BINimages/c9.png
-
BINimages/field_test.png
-
BINimages/iterate_test.png
-
BINimages/kv_sep_test.png
-
+14 -3include/leveldb/db.h
-
+0 -22include/leveldb/env.h
-
+0 -21include/leveldb/options.h
-
+3 -0include/leveldb/slice.h
-
+3 -0include/leveldb/write_batch.h
-
+0 -0prefetch.txt
-
+74 -0test/db_test2.cc
-
+26 -25test/field_test.cc
-
+114 -0test/ttl_test.cc
-
+1 -0third_party/benchmark
-
+0 -5third_party/benchmark/.clang-format
-
+0 -7third_party/benchmark/.clang-tidy
-
+0 -32third_party/benchmark/.github/ISSUE_TEMPLATE/bug_report.md
-
+0 -20third_party/benchmark/.github/ISSUE_TEMPLATE/feature_request.md
-
+0 -13third_party/benchmark/.github/install_bazel.sh
-
+0 -27third_party/benchmark/.github/libcxx-setup.sh
-
+0 -35third_party/benchmark/.github/workflows/bazel.yml
-
+0 -46third_party/benchmark/.github/workflows/build-and-test-min-cmake.yml
-
+0 -51third_party/benchmark/.github/workflows/build-and-test-perfcounters.yml
-
+0 -114third_party/benchmark/.github/workflows/build-and-test.yml
-
+0 -17third_party/benchmark/.github/workflows/clang-format-lint.yml
-
+0 -38third_party/benchmark/.github/workflows/clang-tidy.yml
+ 102
- 0
.github/workflows/build.yml
View File
| @ -0,0 +1,102 @@ | |||
| # Copyright 2021 The LevelDB Authors. All rights reserved. | |||
| # Use of this source code is governed by a BSD-style license that can be | |||
| # found in the LICENSE file. See the AUTHORS file for names of contributors. | |||
| name: ci | |||
| on: [push, pull_request] | |||
| permissions: | |||
| contents: read | |||
| jobs: | |||
| build-and-test: | |||
| name: >- | |||
| CI | |||
| ${{ matrix.os }} | |||
| ${{ matrix.compiler }} | |||
| ${{ matrix.optimized && 'release' || 'debug' }} | |||
| runs-on: ${{ matrix.os }} | |||
| strategy: | |||
| fail-fast: false | |||
| matrix: | |||
| compiler: [clang, gcc, msvc] | |||
| os: [ubuntu-latest, macos-latest, windows-latest] | |||
| optimized: [true, false] | |||
| exclude: | |||
| # MSVC only works on Windows. | |||
| - os: ubuntu-latest | |||
| compiler: msvc | |||
| - os: macos-latest | |||
| compiler: msvc | |||
| # Not testing with GCC on macOS. | |||
| - os: macos-latest | |||
| compiler: gcc | |||
| # Only testing with MSVC on Windows. | |||
| - os: windows-latest | |||
| compiler: clang | |||
| - os: windows-latest | |||
| compiler: gcc | |||
| include: | |||
| - compiler: clang | |||
| CC: clang | |||
| CXX: clang++ | |||
| - compiler: gcc | |||
| CC: gcc | |||
| CXX: g++ | |||
| - compiler: msvc | |||
| CC: | |||
| CXX: | |||
| env: | |||
| CMAKE_BUILD_DIR: ${{ github.workspace }}/build | |||
| CMAKE_BUILD_TYPE: ${{ matrix.optimized && 'RelWithDebInfo' || 'Debug' }} | |||
| CC: ${{ matrix.CC }} | |||
| CXX: ${{ matrix.CXX }} | |||
| BINARY_SUFFIX: ${{ startsWith(matrix.os, 'windows') && '.exe' || '' }} | |||
| BINARY_PATH: >- | |||
| ${{ format( | |||
| startsWith(matrix.os, 'windows') && '{0}\build\{1}\' || '{0}/build/', | |||
| github.workspace, | |||
| matrix.optimized && 'RelWithDebInfo' || 'Debug') }} | |||
| steps: | |||
| - uses: actions/checkout@v2 | |||
| with: | |||
| submodules: true | |||
| - name: Install dependencies on Linux | |||
| if: ${{ runner.os == 'Linux' }} | |||
| # libgoogle-perftools-dev is temporarily removed from the package list | |||
| # because it is currently broken on GitHub's Ubuntu 22.04. | |||
| run: | | |||
| sudo apt-get update | |||
| sudo apt-get install libkyotocabinet-dev libsnappy-dev libsqlite3-dev | |||
| - name: Generate build config | |||
| run: >- | |||
| cmake -S "${{ github.workspace }}" -B "${{ env.CMAKE_BUILD_DIR }}" | |||
| -DCMAKE_BUILD_TYPE=${{ env.CMAKE_BUILD_TYPE }} | |||
| -DCMAKE_INSTALL_PREFIX=${{ runner.temp }}/install_test/ | |||
| - name: Build | |||
| run: >- | |||
| cmake --build "${{ env.CMAKE_BUILD_DIR }}" | |||
| --config "${{ env.CMAKE_BUILD_TYPE }}" | |||
| - name: Run Tests | |||
| working-directory: ${{ github.workspace }}/build | |||
| run: ctest -C "${{ env.CMAKE_BUILD_TYPE }}" --verbose | |||
| - name: Run LevelDB Benchmarks | |||
| run: ${{ env.BINARY_PATH }}db_bench${{ env.BINARY_SUFFIX }} | |||
| - name: Run SQLite Benchmarks | |||
| if: ${{ runner.os != 'Windows' }} | |||
| run: ${{ env.BINARY_PATH }}db_bench_sqlite3${{ env.BINARY_SUFFIX }} | |||
| - name: Run Kyoto Cabinet Benchmarks | |||
| if: ${{ runner.os == 'Linux' && matrix.compiler == 'clang' }} | |||
| run: ${{ env.BINARY_PATH }}db_bench_tree_db${{ env.BINARY_SUFFIX }} | |||
| - name: Test CMake installation | |||
| run: cmake --build "${{ env.CMAKE_BUILD_DIR }}" --target install | |||
+ 2
- 0
.gitignore
View File
+ 1
- 1
.gitmodules
View File
+ 14
- 21
CMakeLists.txt
View File
+ 31
- 0
CONTRIBUTING.md
View File
| @ -0,0 +1,31 @@ | |||
| # How to Contribute | |||
| We'd love to accept your patches and contributions to this project. There are | |||
| just a few small guidelines you need to follow. | |||
| ## Contributor License Agreement | |||
| Contributions to this project must be accompanied by a Contributor License | |||
| Agreement. You (or your employer) retain the copyright to your contribution; | |||
| this simply gives us permission to use and redistribute your contributions as | |||
| part of the project. Head over to <https://cla.developers.google.com/> to see | |||
| your current agreements on file or to sign a new one. | |||
| You generally only need to submit a CLA once, so if you've already submitted one | |||
| (even if it was for a different project), you probably don't need to do it | |||
| again. | |||
| ## Code Reviews | |||
| All submissions, including submissions by project members, require review. We | |||
| use GitHub pull requests for this purpose. Consult | |||
| [GitHub Help](https://help.github.com/articles/about-pull-requests/) for more | |||
| information on using pull requests. | |||
| See [the README](README.md#contributing-to-the-leveldb-project) for areas | |||
| where we are likely to accept external contributions. | |||
| ## Community Guidelines | |||
| This project follows [Google's Open Source Community | |||
| Guidelines](https://opensource.google/conduct/). | |||
+ 3
- 246
README.md
View File
| @ -1,252 +1,9 @@ | |||
| LevelDB is a fast key-value storage library written at Google that provides an ordered mapping from string keys to string values. | |||
| 实验报告请查看以下文档: | |||
| **本仓库提供TTL基本的测试用例** | |||
| 我们的分工已在代码中以注释的形式体现,如:ckx、pzy。 | |||
| - [实验报告](实验报告.md) | |||
| > **This repository is receiving very limited maintenance. We will only review the following types of changes.** | |||
| > | |||
| > * Fixes for critical bugs, such as data loss or memory corruption | |||
| > * Changes absolutely needed by internally supported leveldb clients. These typically fix breakage introduced by a language/standard library/OS update | |||
| [](https://github.com/google/leveldb/actions/workflows/build.yml) | |||
| Authors: Sanjay Ghemawat (sanjay@google.com) and Jeff Dean (jeff@google.com) | |||
| # Features | |||
| * Keys and values are arbitrary byte arrays. | |||
| * Data is stored sorted by key. | |||
| * Callers can provide a custom comparison function to override the sort order. | |||
| * The basic operations are `Put(key,value)`, `Get(key)`, `Delete(key)`. | |||
| * Multiple changes can be made in one atomic batch. | |||
| * Users can create a transient snapshot to get a consistent view of data. | |||
| * Forward and backward iteration is supported over the data. | |||
| * Data is automatically compressed using the [Snappy compression library](https://google.github.io/snappy/), but [Zstd compression](https://facebook.github.io/zstd/) is also supported. | |||
| * External activity (file system operations etc.) is relayed through a virtual interface so users can customize the operating system interactions. | |||
| # Documentation | |||
| [LevelDB library documentation](https://github.com/google/leveldb/blob/main/doc/index.md) is online and bundled with the source code. | |||
| # Limitations | |||
| * This is not a SQL database. It does not have a relational data model, it does not support SQL queries, and it has no support for indexes. | |||
| * Only a single process (possibly multi-threaded) can access a particular database at a time. | |||
| * There is no client-server support builtin to the library. An application that needs such support will have to wrap their own server around the library. | |||
| # Getting the Source | |||
| ```bash | |||
| git clone --recurse-submodules https://github.com/google/leveldb.git | |||
| ``` | |||
| # Building | |||
| This project supports [CMake](https://cmake.org/) out of the box. | |||
| ### Build for POSIX | |||
| Quick start: | |||
| 克隆代码: | |||
| ```bash | |||
| mkdir -p build && cd build | |||
| cmake -DCMAKE_BUILD_TYPE=Release .. && cmake --build . | |||
| git clone --recurse-submodules https://gitea.shuishan.net.cn/building_data_management_systems.Xuanzhou.2024Fall.DaSE/leveldb_base.git | |||
| ``` | |||
| ### Building for Windows | |||
| First generate the Visual Studio 2017 project/solution files: | |||
| ```cmd | |||
| mkdir build | |||
| cd build | |||
| cmake -G "Visual Studio 15" .. | |||
| ``` | |||
| The default default will build for x86. For 64-bit run: | |||
| ```cmd | |||
| cmake -G "Visual Studio 15 Win64" .. | |||
| ``` | |||
| To compile the Windows solution from the command-line: | |||
| ```cmd | |||
| devenv /build Debug leveldb.sln | |||
| ``` | |||
| or open leveldb.sln in Visual Studio and build from within. | |||
| Please see the CMake documentation and `CMakeLists.txt` for more advanced usage. | |||
| # Contributing to the leveldb Project | |||
| > **This repository is receiving very limited maintenance. We will only review the following types of changes.** | |||
| > | |||
| > * Bug fixes | |||
| > * Changes absolutely needed by internally supported leveldb clients. These typically fix breakage introduced by a language/standard library/OS update | |||
| The leveldb project welcomes contributions. leveldb's primary goal is to be | |||
| a reliable and fast key/value store. Changes that are in line with the | |||
| features/limitations outlined above, and meet the requirements below, | |||
| will be considered. | |||
| Contribution requirements: | |||
| 1. **Tested platforms only**. We _generally_ will only accept changes for | |||
| platforms that are compiled and tested. This means POSIX (for Linux and | |||
| macOS) or Windows. Very small changes will sometimes be accepted, but | |||
| consider that more of an exception than the rule. | |||
| 2. **Stable API**. We strive very hard to maintain a stable API. Changes that | |||
| require changes for projects using leveldb _might_ be rejected without | |||
| sufficient benefit to the project. | |||
| 3. **Tests**: All changes must be accompanied by a new (or changed) test, or | |||
| a sufficient explanation as to why a new (or changed) test is not required. | |||
| 4. **Consistent Style**: This project conforms to the | |||
| [Google C++ Style Guide](https://google.github.io/styleguide/cppguide.html). | |||
| To ensure your changes are properly formatted please run: | |||
| ``` | |||
| clang-format -i --style=file <file> | |||
| ``` | |||
| We are unlikely to accept contributions to the build configuration files, such | |||
| as `CMakeLists.txt`. We are focused on maintaining a build configuration that | |||
| allows us to test that the project works in a few supported configurations | |||
| inside Google. We are not currently interested in supporting other requirements, | |||
| such as different operating systems, compilers, or build systems. | |||
| ## Submitting a Pull Request | |||
| Before any pull request will be accepted the author must first sign a | |||
| Contributor License Agreement (CLA) at https://cla.developers.google.com/. | |||
| In order to keep the commit timeline linear | |||
| [squash](https://git-scm.com/book/en/v2/Git-Tools-Rewriting-History#Squashing-Commits) | |||
| your changes down to a single commit and [rebase](https://git-scm.com/docs/git-rebase) | |||
| on google/leveldb/main. This keeps the commit timeline linear and more easily sync'ed | |||
| with the internal repository at Google. More information at GitHub's | |||
| [About Git rebase](https://help.github.com/articles/about-git-rebase/) page. | |||
| # Performance | |||
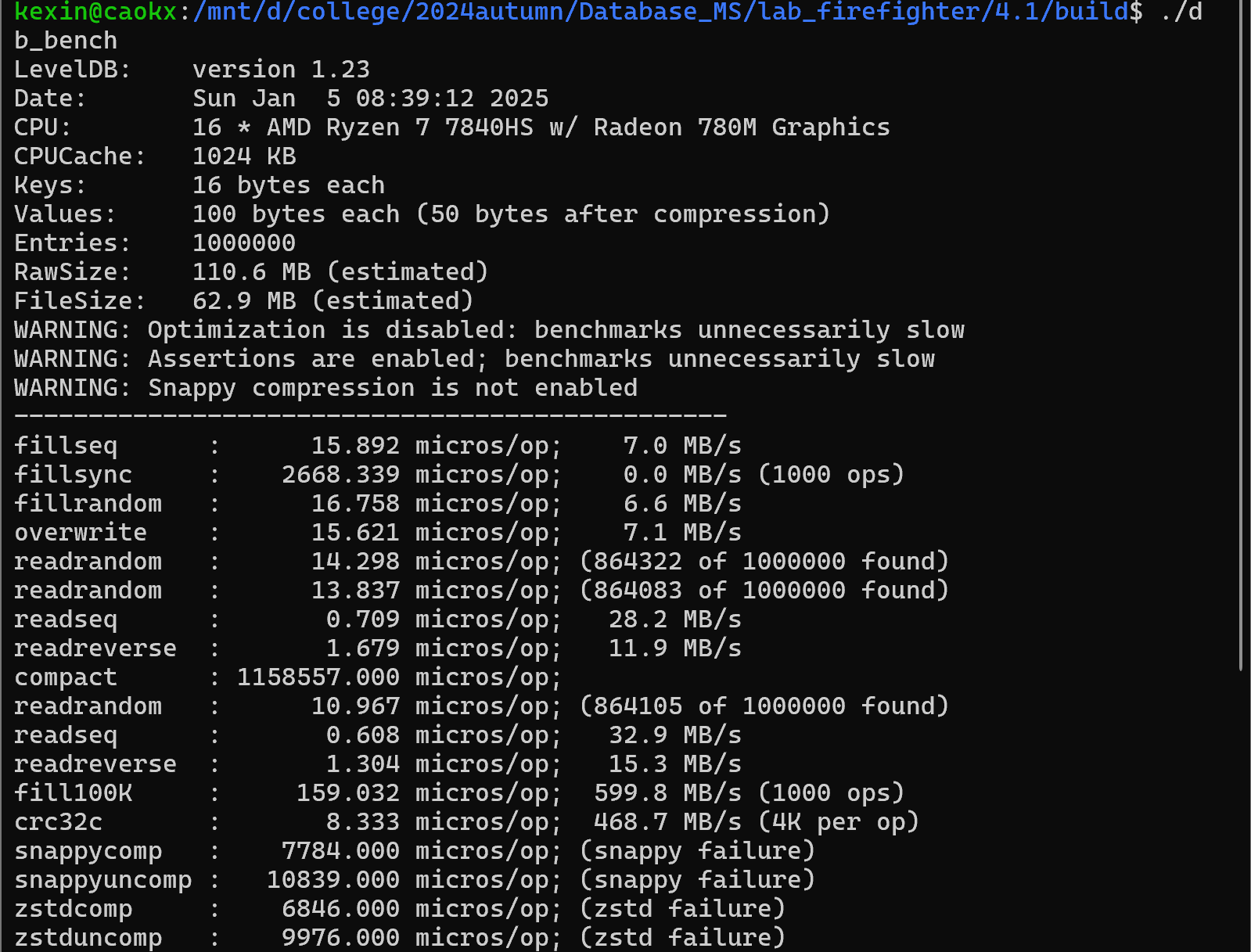
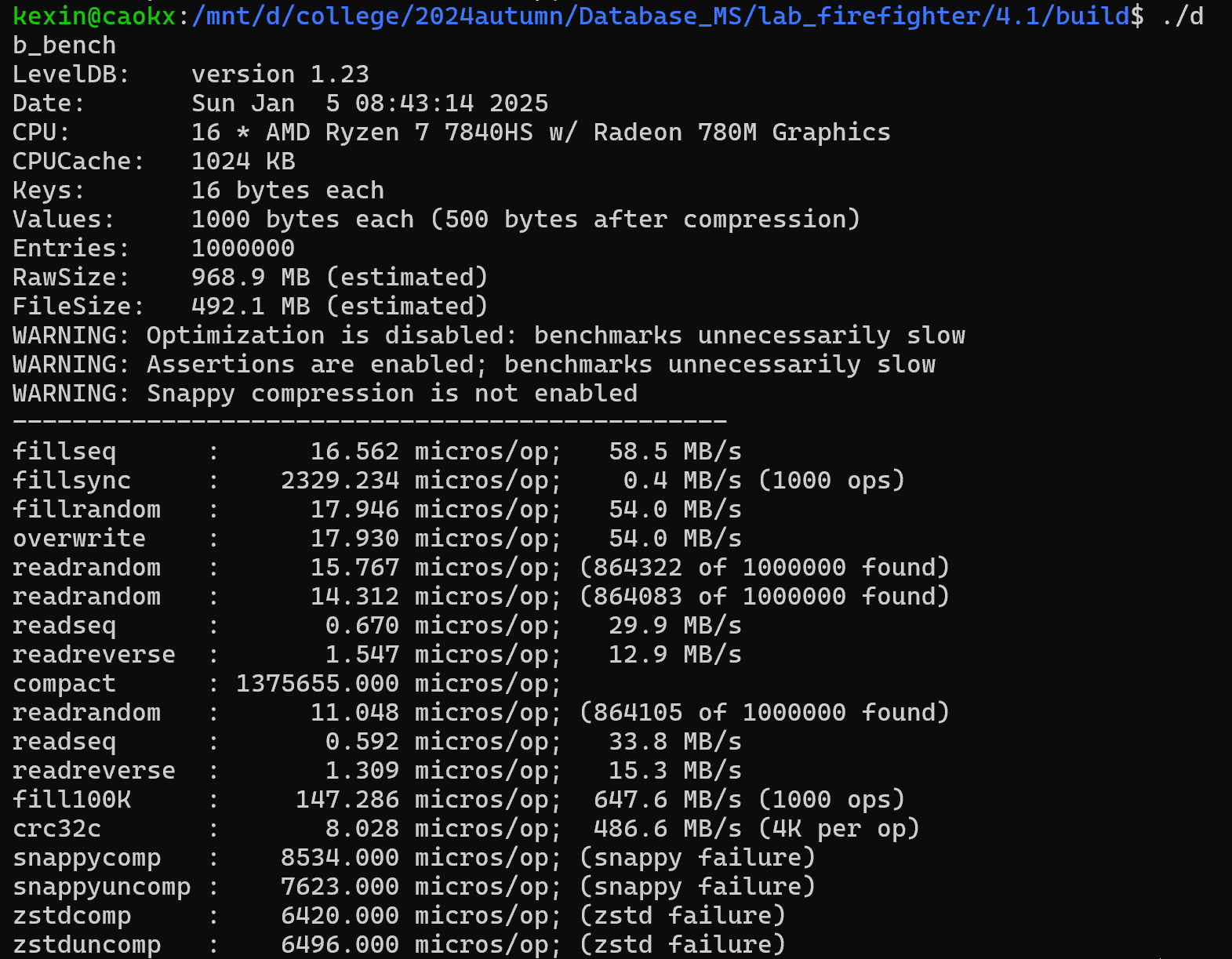
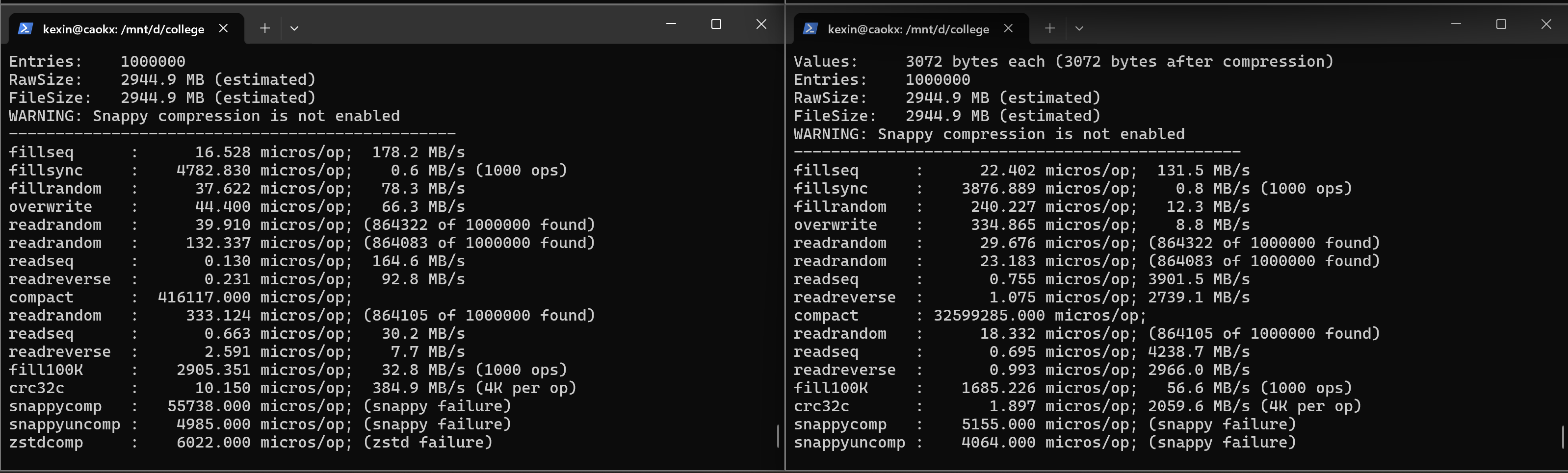
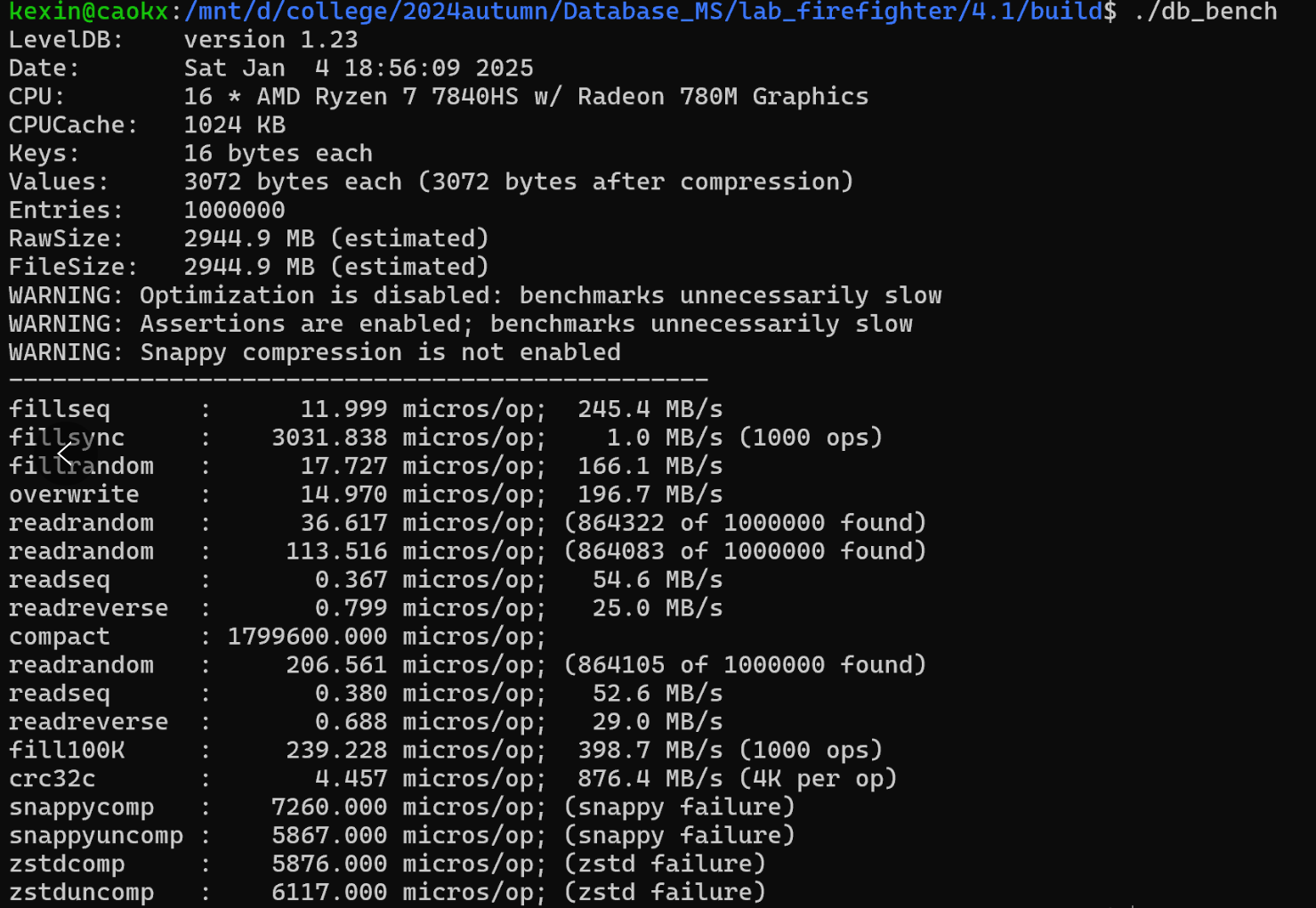
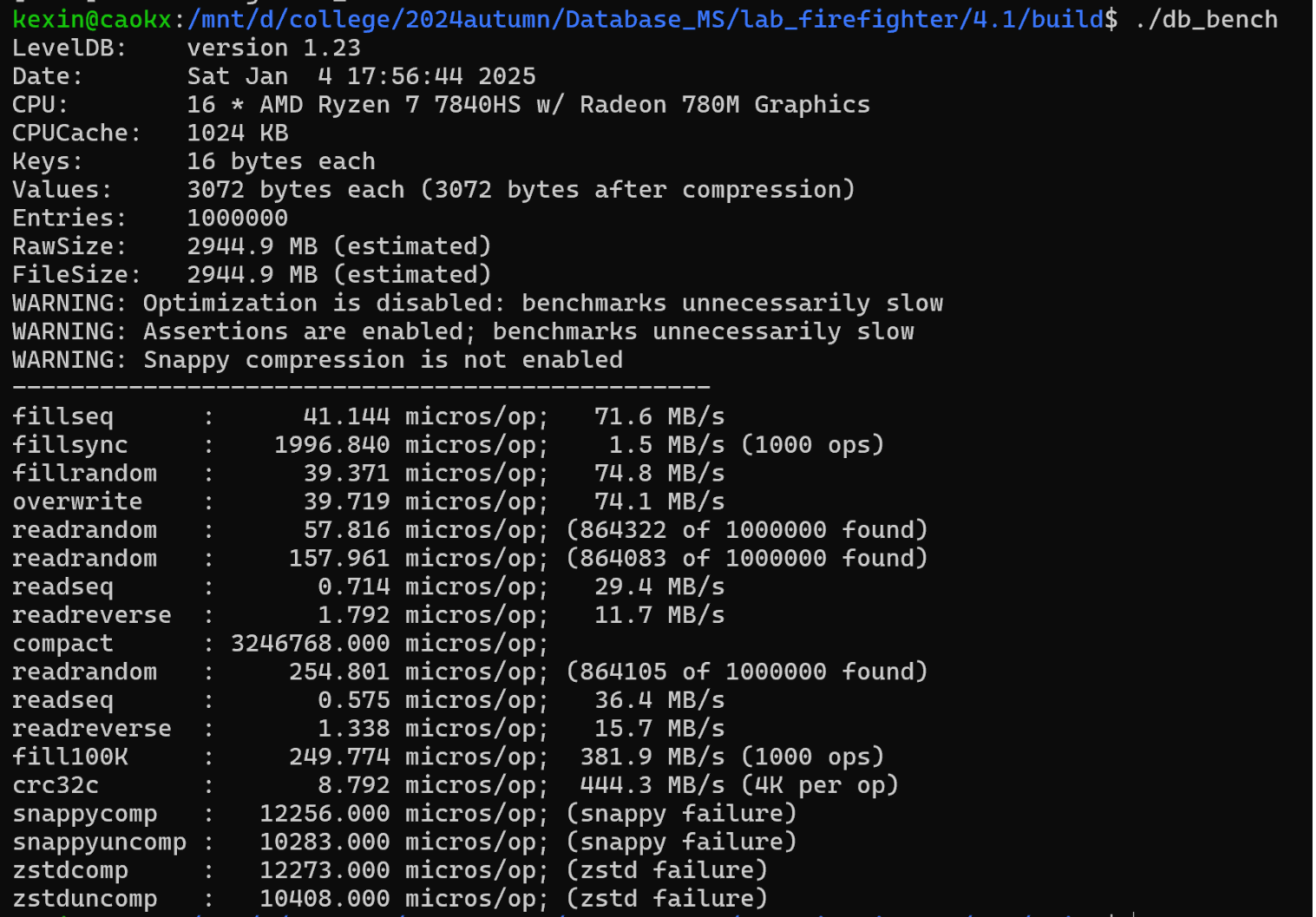
| Here is a performance report (with explanations) from the run of the | |||
| included db_bench program. The results are somewhat noisy, but should | |||
| be enough to get a ballpark performance estimate. | |||
| ## Setup | |||
| We use a database with a million entries. Each entry has a 16 byte | |||
| key, and a 100 byte value. Values used by the benchmark compress to | |||
| about half their original size. | |||
| LevelDB: version 1.1 | |||
| Date: Sun May 1 12:11:26 2011 | |||
| CPU: 4 x Intel(R) Core(TM)2 Quad CPU Q6600 @ 2.40GHz | |||
| CPUCache: 4096 KB | |||
| Keys: 16 bytes each | |||
| Values: 100 bytes each (50 bytes after compression) | |||
| Entries: 1000000 | |||
| Raw Size: 110.6 MB (estimated) | |||
| File Size: 62.9 MB (estimated) | |||
| ## Write performance | |||
| The "fill" benchmarks create a brand new database, in either | |||
| sequential, or random order. The "fillsync" benchmark flushes data | |||
| from the operating system to the disk after every operation; the other | |||
| write operations leave the data sitting in the operating system buffer | |||
| cache for a while. The "overwrite" benchmark does random writes that | |||
| update existing keys in the database. | |||
| fillseq : 1.765 micros/op; 62.7 MB/s | |||
| fillsync : 268.409 micros/op; 0.4 MB/s (10000 ops) | |||
| fillrandom : 2.460 micros/op; 45.0 MB/s | |||
| overwrite : 2.380 micros/op; 46.5 MB/s | |||
| Each "op" above corresponds to a write of a single key/value pair. | |||
| I.e., a random write benchmark goes at approximately 400,000 writes per second. | |||
| Each "fillsync" operation costs much less (0.3 millisecond) | |||
| than a disk seek (typically 10 milliseconds). We suspect that this is | |||
| because the hard disk itself is buffering the update in its memory and | |||
| responding before the data has been written to the platter. This may | |||
| or may not be safe based on whether or not the hard disk has enough | |||
| power to save its memory in the event of a power failure. | |||
| ## Read performance | |||
| We list the performance of reading sequentially in both the forward | |||
| and reverse direction, and also the performance of a random lookup. | |||
| Note that the database created by the benchmark is quite small. | |||
| Therefore the report characterizes the performance of leveldb when the | |||
| working set fits in memory. The cost of reading a piece of data that | |||
| is not present in the operating system buffer cache will be dominated | |||
| by the one or two disk seeks needed to fetch the data from disk. | |||
| Write performance will be mostly unaffected by whether or not the | |||
| working set fits in memory. | |||
| readrandom : 16.677 micros/op; (approximately 60,000 reads per second) | |||
| readseq : 0.476 micros/op; 232.3 MB/s | |||
| readreverse : 0.724 micros/op; 152.9 MB/s | |||
| LevelDB compacts its underlying storage data in the background to | |||
| improve read performance. The results listed above were done | |||
| immediately after a lot of random writes. The results after | |||
| compactions (which are usually triggered automatically) are better. | |||
| readrandom : 11.602 micros/op; (approximately 85,000 reads per second) | |||
| readseq : 0.423 micros/op; 261.8 MB/s | |||
| readreverse : 0.663 micros/op; 166.9 MB/s | |||
| Some of the high cost of reads comes from repeated decompression of blocks | |||
| read from disk. If we supply enough cache to the leveldb so it can hold the | |||
| uncompressed blocks in memory, the read performance improves again: | |||
| readrandom : 9.775 micros/op; (approximately 100,000 reads per second before compaction) | |||
| readrandom : 5.215 micros/op; (approximately 190,000 reads per second after compaction) | |||
| ## Repository contents | |||
| See [doc/index.md](doc/index.md) for more explanation. See | |||
| [doc/impl.md](doc/impl.md) for a brief overview of the implementation. | |||
| The public interface is in include/leveldb/*.h. Callers should not include or | |||
| rely on the details of any other header files in this package. Those | |||
| internal APIs may be changed without warning. | |||
| Guide to header files: | |||
| * **include/leveldb/db.h**: Main interface to the DB: Start here. | |||
| * **include/leveldb/options.h**: Control over the behavior of an entire database, | |||
| and also control over the behavior of individual reads and writes. | |||
| * **include/leveldb/comparator.h**: Abstraction for user-specified comparison function. | |||
| If you want just bytewise comparison of keys, you can use the default | |||
| comparator, but clients can write their own comparator implementations if they | |||
| want custom ordering (e.g. to handle different character encodings, etc.). | |||
| * **include/leveldb/iterator.h**: Interface for iterating over data. You can get | |||
| an iterator from a DB object. | |||
| * **include/leveldb/write_batch.h**: Interface for atomically applying multiple | |||
| updates to a database. | |||
| * **include/leveldb/slice.h**: A simple module for maintaining a pointer and a | |||
| length into some other byte array. | |||
| * **include/leveldb/status.h**: Status is returned from many of the public interfaces | |||
| and is used to report success and various kinds of errors. | |||
| * **include/leveldb/env.h**: | |||
| Abstraction of the OS environment. A posix implementation of this interface is | |||
| in util/env_posix.cc. | |||
| * **include/leveldb/table.h, include/leveldb/table_builder.h**: Lower-level modules that most | |||
| clients probably won't use directly. | |||
+ 0
- 16
TODO
View File
+ 0
- 5
UseGuaide.txt
View File
| @ -1,5 +0,0 @@ | |||
| 运行新代码: | |||
| 1. 在examples/ 添加对应的测试文件 | |||
| 2. 在最外层CMakeLists加入新的测试文件的编译指令,代码参考: + leveldb_test("examples/main.cc") | |||
| 3. 进入build文件,重新编译,指令:"cmake -DCMAKE_BUILD_TYPE=Release .. && cmake --build ."。 | |||
| "cmake -DCMAKE_BUILD_TYPE=Debug .. && cmake --build ." | |||
+ 8
- 6
benchmarks/db_bench.cc
View File
+ 4
- 0
benchmarks/db_bench_log.cc
View File
+ 4
- 0
benchmarks/db_bench_sqlite3.cc
View File
+ 4
- 0
benchmarks/db_bench_tree_db.cc
View File
+ 4
- 0
db/autocompact_test.cc
View File
+ 6
- 15
db/builder.cc
View File
+ 5
- 2
db/builder.h
View File
+ 5
- 2
db/c.cc
View File
+ 4
- 0
db/c_test.c
View File
+ 1
- 2
db/corruption_test.cc
View File
+ 27
- 192
db/db_impl.cc
View File
+ 6
- 37
db/db_impl.h
View File
+ 4
- 24
db/db_test.cc
View File
+ 2
- 11
db/filename.cc
View File
+ 1
- 7
db/filename.h
View File
+ 0
- 4
db/log_test.cc
View File
+ 4
- 6
db/repair.cc
View File
+ 0
- 20
db/vlog_converter.cc
View File
| @ -1,20 +0,0 @@ | |||
| #include "util/coding.h" | |||
| #include "db/vlog_converter.h" | |||
| namespace leveldb{ | |||
| namespace vlog{ | |||
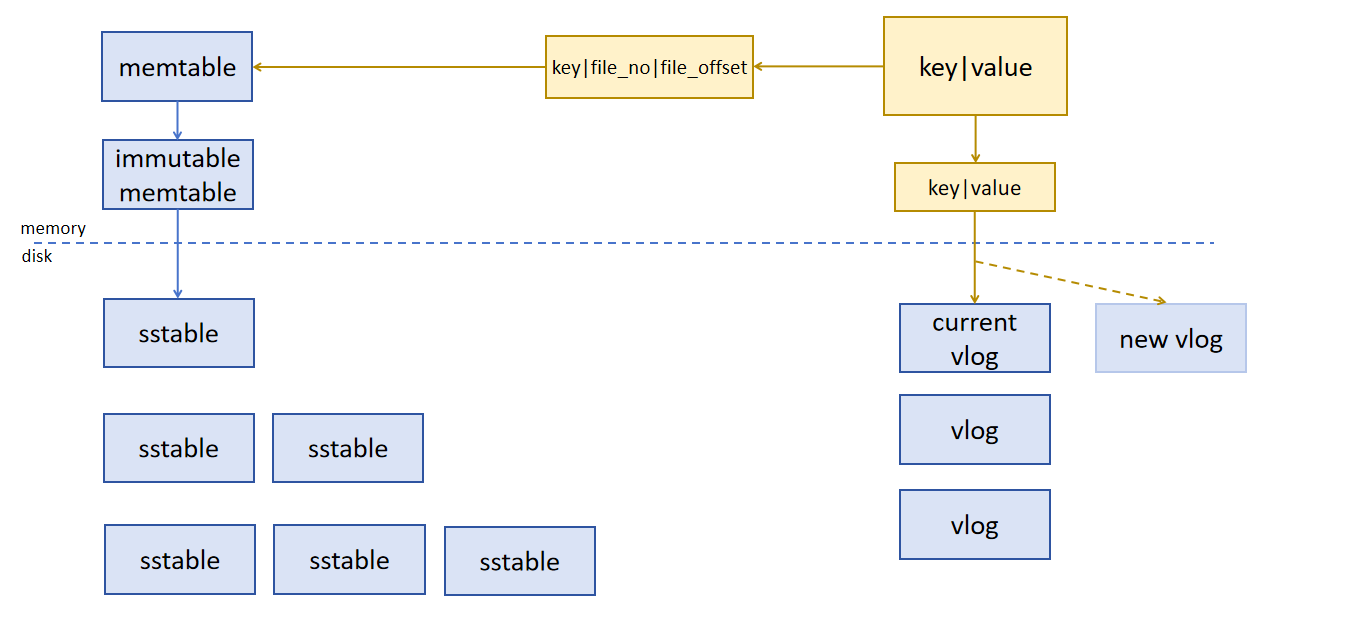
| // 当需要将键值对插入数据库时,将值的存储位置 (file_no 和 file_offset) 编码为 Vlog Pointer,并与键关联存储。 | |||
| // 紧凑的编码格式便于减少存储开销。 | |||
| Slice VlogConverter::GetVptr(uint64_t file_no, uint64_t file_offset, char* buf){ | |||
| char* vfileno_end = EncodeVarint64(buf, file_no); | |||
| char* vfileoff_end = EncodeVarint64(vfileno_end, file_offset); | |||
| return Slice(buf, vfileoff_end - buf); | |||
| } | |||
| Status VlogConverter::DecodeVptr(uint64_t* file_no, uint64_t* file_offset, Slice* vptr){ | |||
| bool decoded_status = true; | |||
| decoded_status &= GetVarint64(vptr, file_no); | |||
| decoded_status &= GetVarint64(vptr, file_offset); | |||
| if(!decoded_status) return Status::Corruption("Can not Decode vptr from Read Bytes."); | |||
| else return Status::OK(); | |||
| } | |||
| }// namespace vlog | |||
| } | |||
+ 0
- 19
db/vlog_converter.h
View File
| @ -1,19 +0,0 @@ | |||
| #ifndef STORAGE_LEVELDB_DB_VLOG_CONVERTER_H_ | |||
| #define STORAGE_LEVELDB_DB_VLOG_CONVERTER_H_ | |||
| #include <cstdint> | |||
| #include "leveldb/slice.h" | |||
| #include "leveldb/status.h" | |||
| namespace leveldb{ | |||
| namespace vlog{ | |||
| class VlogConverter{ | |||
| public: | |||
| VlogConverter() = default; | |||
| ~VlogConverter() = default; | |||
| Slice GetVptr(uint64_t file_no, uint64_t file_offset, char* buf); | |||
| Status DecodeVptr(uint64_t* file_no, uint64_t* file_offset, Slice* vptr); | |||
| }; | |||
| }// namespace vlog | |||
| } | |||
| #endif | |||
+ 0
- 33
db/vlog_manager.cc
View File
| @ -1,33 +0,0 @@ | |||
| #include "db/vlog_manager.h" | |||
| namespace leveldb{ | |||
| namespace vlog{ | |||
| void VlogManager::AddVlogFile(uint64_t vlogfile_number, SequentialFile* seq_file, WritableFile* write_file){ | |||
| if(vlog_table_.find(vlogfile_number) == vlog_table_.end()){ | |||
| vlog_table_[vlogfile_number] = seq_file; | |||
| writable_to_sequential_[write_file] = seq_file; | |||
| } | |||
| else{ | |||
| //Do Nothing | |||
| } | |||
| } | |||
| SequentialFile* VlogManager::GetVlogFile(uint64_t vlogfile_number){ | |||
| auto it = vlog_table_.find(vlogfile_number); | |||
| if(it != vlog_table_.end()){ | |||
| return it->second; | |||
| } | |||
| else return nullptr; | |||
| } | |||
| bool VlogManager::IsEmpty(){ | |||
| return vlog_table_.size() == 0; | |||
| } | |||
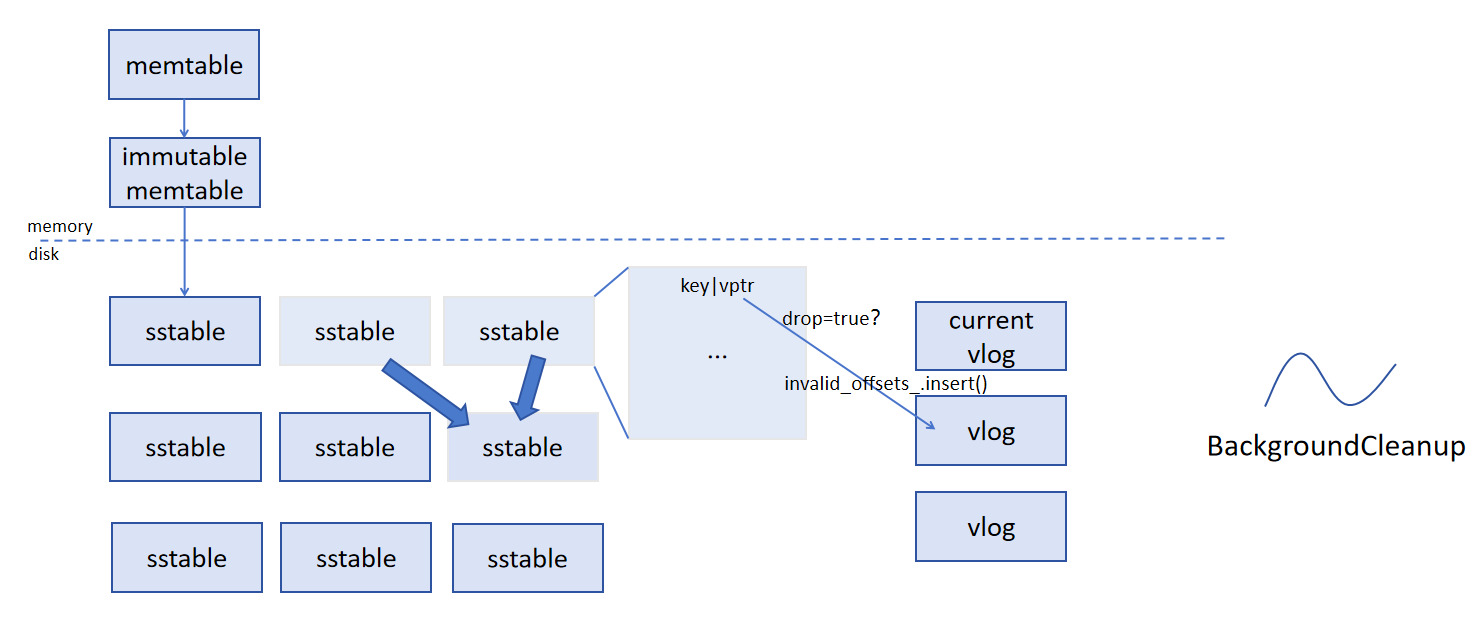
| // 标记一个vlog文件有一个新的无效的value,pzy | |||
| void VlogManager::MarkVlogValueInvalid(uint64_t vlogfile_number, uint64_t offset) { | |||
| auto vlog_file = GetVlogFile(vlogfile_number); | |||
| if (vlog_file) { | |||
| vlog_file->MarkValueInvalid(offset); // 调用具体文件的标记逻辑 | |||
| } | |||
| } | |||
| }// namespace vlog | |||
| } | |||
+ 0
- 61
db/vlog_manager.h
View File
| @ -1,61 +0,0 @@ | |||
| #ifndef STORAGE_LEVELDB_DB_VLOG_MANAGER_H_ | |||
| #define STORAGE_LEVELDB_DB_VLOG_MANAGER_H_ | |||
| #include <unordered_map> | |||
| #include <cstdint> | |||
| #include "leveldb/env.h" | |||
| #include "db/filename.h" | |||
| #include "leveldb/options.h" | |||
| namespace leveldb{ | |||
| class SequentialFile; | |||
| namespace vlog{ | |||
| class VlogManager{ | |||
| public: | |||
| VlogManager() = default; | |||
| ~VlogManager() = default; | |||
| //Add a vlog file, vlog file is already exist. | |||
| void AddVlogFile(uint64_t vlogfile_number, SequentialFile* seq_file, WritableFile* write_file); | |||
| SequentialFile* GetVlogFile(uint64_t vlogfile_number); | |||
| bool IsEmpty(); | |||
| void MarkVlogValueInvalid(uint64_t vlogfile_number, uint64_t offset); | |||
| SequentialFile* GetSequentialFile(WritableFile* write_file) { | |||
| auto it = writable_to_sequential_.find(write_file); | |||
| return it != writable_to_sequential_.end() ? it->second : nullptr; | |||
| } | |||
| void IncrementTotalValueCount(WritableFile* write_file) { | |||
| auto seq_file = GetSequentialFile(write_file); | |||
| if (seq_file) { | |||
| seq_file->IncrementTotalValueCount(); // 假设 SequentialFile 提供该方法 | |||
| } | |||
| } | |||
| void CleanupInvalidVlogFiles(const Options& options, const std::string& dbname) { | |||
| for (const auto& vlog_pair : vlog_table_) { | |||
| uint64_t vlogfile_number = vlog_pair.first; | |||
| auto vlog_file = vlog_pair.second; | |||
| if (vlog_file->AllValuesInvalid()) { // 检查文件内所有值是否无效 | |||
| RemoveVlogFile(vlogfile_number, options, dbname); // 删除 VLog 文件 | |||
| } | |||
| } | |||
| } | |||
| void RemoveVlogFile(uint64_t vlogfile_number, const Options& options, const std::string& dbname) { // 移除无效的vlogfile文件 | |||
| auto it = vlog_table_.find(vlogfile_number); | |||
| if (it != vlog_table_.end()) { | |||
| delete it->second; // 删除对应的 SequentialFile | |||
| vlog_table_.erase(it); // 从管理器中移除 | |||
| options.env->DeleteFile(VlogFileName(dbname, vlogfile_number)); // 删除实际文件 | |||
| } | |||
| } | |||
| private: | |||
| std::unordered_map<uint64_t, SequentialFile*> vlog_table_; // 用映射组织vlog文件号和文件的关系 | |||
| std::unordered_map<WritableFile*, SequentialFile*> writable_to_sequential_; | |||
| }; | |||
| }// namespace vlog | |||
| } | |||
| #endif | |||
+ 0
- 58
db/vlog_reader.cc
View File
| @ -1,58 +0,0 @@ | |||
| #include <cstdint> | |||
| #include "db/vlog_reader.h" | |||
| #include "leveldb/slice.h" | |||
| #include "leveldb/env.h" | |||
| #include "util/coding.h" | |||
| namespace leveldb{ | |||
| namespace vlog{ | |||
| VReader::VReader(SequentialFile* file) // A file abstraction for reading sequentially through a file | |||
| :file_(file){} | |||
| Status VReader::ReadRecord(uint64_t vfile_offset, std::string* record){ | |||
| Status s; | |||
| Slice size_slice; | |||
| char size_buf[11]; | |||
| uint64_t rec_size = 0; | |||
| s = file_->SkipFromHead(vfile_offset); // 将文件的读取位置移动到 vfile_offset | |||
| if(s.ok()) s = file_ -> Read(10, &size_slice, size_buf); // 先把Record 长度读出来, 最长10字节. | |||
| if(s.ok()){ | |||
| if(GetVarint64(&size_slice, &rec_size) == false){ // 解析变长整数,得到记录的长度 rec_size | |||
| return Status::Corruption("Failed to decode vlog record size."); | |||
| } | |||
| std::string rec; | |||
| char* c_rec = new char[rec_size]; // 为记录分配一个临时缓冲区 | |||
| //TODO: Should delete c_rec? | |||
| rec.resize(rec_size); | |||
| Slice rec_slice; | |||
| s = file_->SkipFromHead(vfile_offset + (size_slice.data() - size_buf)); // 将文件的读取位置移动 | |||
| if(!s.ok()) return s; | |||
| s = file_-> Read(rec_size, &rec_slice, c_rec); // 从文件中读取 rec_size 字节的数据到 c_rec 中,并用 rec_slice 包装这些数据 | |||
| if(!s.ok()) return s; | |||
| rec = std::string(c_rec, rec_size); | |||
| *record = std::move(std::string(rec)); | |||
| } | |||
| return s; | |||
| } | |||
| Status VReader::ReadKV(uint64_t vfile_offset, std::string* key, std::string* val){ | |||
| std::string record_str; | |||
| Status s = ReadRecord(vfile_offset, &record_str); | |||
| if(s.ok()){ | |||
| Slice record = Slice(record_str); | |||
| //File the val | |||
| uint64_t key_size; | |||
| bool decode_flag = true; | |||
| decode_flag &= GetVarint64(&record, &key_size); // 获取键的长度 | |||
| if(decode_flag){ | |||
| *key = Slice(record.data(), key_size).ToString(); // 从record中截取键值 | |||
| record = Slice(record.data() + key_size, record.size() - key_size); // 截取剩余的record | |||
| } | |||
| uint64_t val_size; | |||
| decode_flag &= GetVarint64(&record, &val_size); // 获取value的长度 | |||
| if(decode_flag) *val = Slice(record.data(), val_size).ToString(); // 截取value的值 | |||
| if(!decode_flag || val->size() != record.size()){ | |||
| s = Status::Corruption("Failed to decode Record Read From vlog."); | |||
| } | |||
| } | |||
| return s; | |||
| } | |||
| }// namespace vlog. | |||
| } | |||
+ 0
- 25
db/vlog_reader.h
View File
| @ -1,25 +0,0 @@ | |||
| #ifndef STORAGE_LEVELDB_DB_VLOG_READER_H_ | |||
| #define STORAGE_LEVELDB_DB_VLOG_READER_H_ | |||
| #include <cstdint> | |||
| #include "leveldb/slice.h" | |||
| #include "leveldb/status.h" | |||
| #include "port/port.h" | |||
| namespace leveldb { | |||
| class SequentialFile; | |||
| namespace vlog { | |||
| class VReader { | |||
| public: | |||
| explicit VReader(SequentialFile* file); | |||
| ~VReader() = default; | |||
| Status ReadRecord(uint64_t vfile_offset, std::string* record); | |||
| Status ReadKV(uint64_t vfile_offset, std::string* key ,std::string* val); | |||
| private: | |||
| SequentialFile* file_; | |||
| }; | |||
| } // namespace vlog | |||
| } | |||
| #endif | |||
+ 0
- 26
db/vlog_writer.cc
View File
| @ -1,26 +0,0 @@ | |||
| #include <cstdint> | |||
| #include "db/vlog_writer.h" | |||
| #include "leveldb/slice.h" | |||
| #include "leveldb/env.h" | |||
| #include "util/coding.h" | |||
| namespace leveldb{ | |||
| namespace vlog{ | |||
| VWriter::VWriter(WritableFile* vlogfile) | |||
| :vlogfile_(vlogfile){} | |||
| VWriter::~VWriter() = default; | |||
| Status VWriter::AddRecord(const Slice& slice, int& write_size){ | |||
| //append slice length. | |||
| write_size = slice.size(); | |||
| char buf[10]; // Used for Convert int64 to char. | |||
| char* end_byte = EncodeVarint64(buf, slice.size()); | |||
| write_size += end_byte - buf; | |||
| Status s = vlogfile_->Append(Slice(buf, end_byte - buf)); | |||
| //append slice | |||
| if(s.ok()) s = vlogfile_->Append(slice); | |||
| return s; | |||
| } | |||
| Status VWriter::Flush(){ | |||
| return vlogfile_->Flush(); | |||
| } | |||
| }// namespace vlog | |||
| } | |||
+ 0
- 26
db/vlog_writer.h
View File
| @ -1,26 +0,0 @@ | |||
| #ifndef STORAGE_LEVELDB_DB_VLOG_WRITER_H_ | |||
| #define STORAGE_LEVELDB_DB_VLOG_WRITER_H_ | |||
| #include <cstdint> | |||
| #include "leveldb/slice.h" | |||
| #include "leveldb/status.h" | |||
| // format: [size, key, vptr, value]. | |||
| namespace leveldb{ | |||
| class WritableFile; | |||
| namespace vlog{ | |||
| class VWriter{ | |||
| public: | |||
| explicit VWriter(WritableFile* vlogfile); | |||
| ~VWriter(); | |||
| Status AddRecord(const Slice& slice, int& write_size); | |||
| VWriter(const VWriter&) = delete; | |||
| VWriter& operator=(const VWriter&) = delete; | |||
| Status Flush(); | |||
| private: | |||
| WritableFile* vlogfile_; | |||
| }; | |||
| }// namespace vlog | |||
| } | |||
| #endif | |||
+ 31
- 18
db/write_batch.cc
View File
+ 1
- 1
db/write_batch_internal.h
View File
+ 0
- 45
draw.py
View File
| @ -1,45 +0,0 @@ | |||
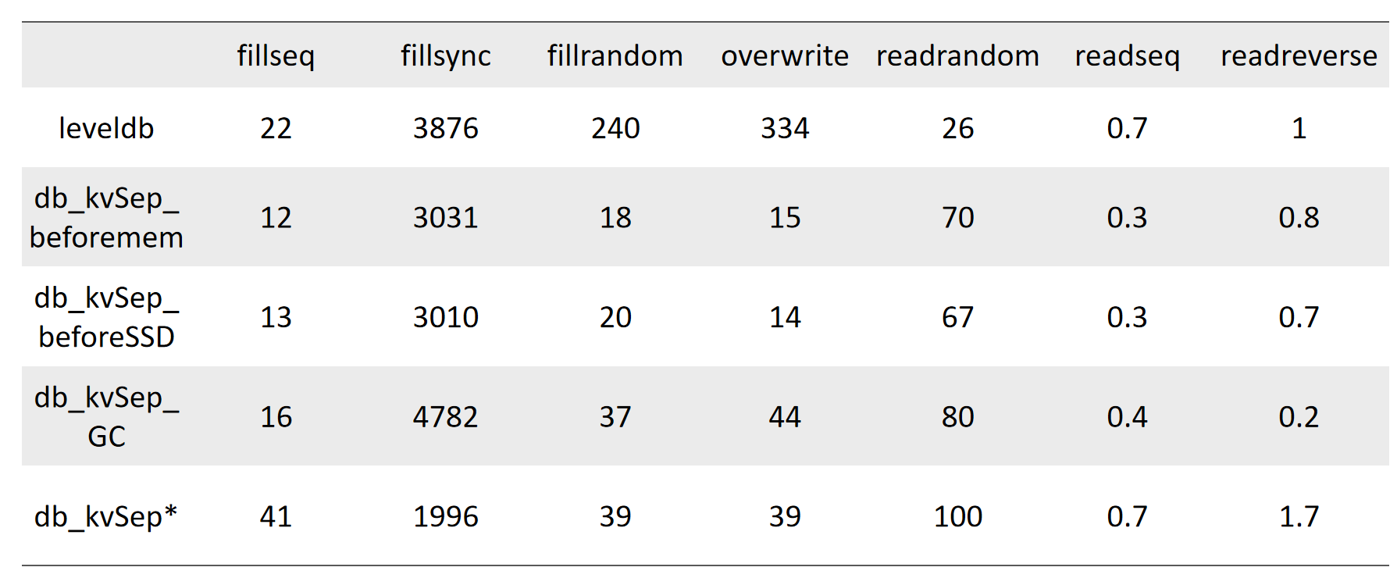
| import matplotlib.pyplot as plt | |||
| x = [128, 256, 512, 1024, 2048, 3072, 4096] | |||
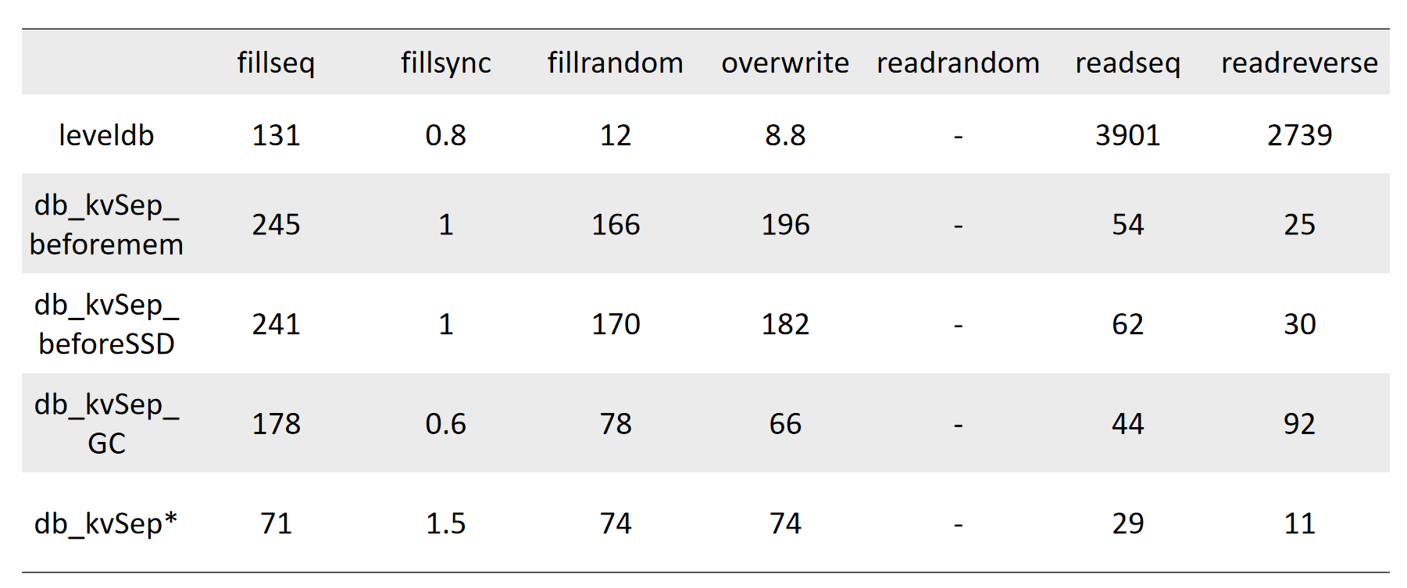
| y_w = [ | |||
| [52.8, 67.0, 60.8, 52.3, 42.2, 34.2, 30.2],# noKVSep | |||
| [44.2, 87.5, 139.5, 274.2 ,426.3, 576.2, 770.4], # kvSepBeforeMem | |||
| [59.9, 102.4 ,147.9 ,173.5, 184.2, 199.2, 206.8] #kvSepBeforeSSD | |||
| ] | |||
| y_r = [ | |||
| [731.9, 1127.4, 1515.2, 3274.7, 4261.9, 4886.3, 4529.8],# noKVSep | |||
| [158.9, 154.9, 145.0, 160.9 , 147.3, 144.0, 127.4], # kvSepBeforeMem | |||
| [171.1, 136.0 ,179.8 ,169.8, 159.9, 161.5, 168.6] #kvSepBeforeSSD | |||
| ] | |||
| y_random = [ | |||
| [2.363, 2.698, 3.972, 3.735, 7.428, 12.137, 17.753],# noKVSep | |||
| [2.957, 2.953, 3.417, 3.363 ,3.954, 17.516, 79.023], # kvSepBeforeMem | |||
| [2.927, 2.739 ,2.947, 3.604, 3.530, 19.189, 80.608] #kvSepBeforeSSD | |||
| ] | |||
| plt.figure(num = 1) | |||
| plt.title("Write Performance(fillrandom)") | |||
| plt.xlabel("Value size(B)") | |||
| plt.ylabel("Throughout(MiB/s)") | |||
| l1 = plt.plot(x, y_w[0], "bo", linestyle = "dashed") | |||
| l1 = plt.plot(x, y_w[1], "g^", linestyle = "dashed") | |||
| l1 = plt.plot(x, y_w[2], "y+", linestyle = "dashed") | |||
| plt.legend(["noKVSep", "kvSepBeforeMem", "kvSepBeforeSSD"]) | |||
| plt.show() | |||
| plt.figure(num = 1) | |||
| plt.title("Read Performance(readreverse)") | |||
| plt.xlabel("Value size(B)") | |||
| plt.ylabel("Throughout(MiB/s)") | |||
| l1 = plt.plot(x, y_r[0], "bo", linestyle = "dashed") | |||
| l1 = plt.plot(x, y_r[1], "g^", linestyle = "dashed") | |||
| l1 = plt.plot(x, y_r[2], "y+", linestyle = "dashed") | |||
| plt.legend(["noKVSep", "kvSepBeforeMem", "kvSepBeforeSSD"]) | |||
| plt.show() | |||
| plt.title("Read Performance(readrandom)") | |||
| plt.xlabel("Value size(B)") | |||
| plt.ylabel("Micros/op") | |||
| l1 = plt.plot(x, y_random[0], "bo", linestyle = "dashed") | |||
| l1 = plt.plot(x, y_random[1], "g^", linestyle = "dashed") | |||
| l1 = plt.plot(x, y_random[2], "y+", linestyle = "dashed") | |||
| plt.legend(["noKVSep", "kvSepBeforeMem", "kvSepBeforeSSD"]) | |||
| plt.show() | |||
+ 0
- 50
examples/GCtest.cc
View File
| @ -1,50 +0,0 @@ | |||
| #include <iostream> | |||
| #include "leveldb/db.h" | |||
| #include "leveldb/options.h" | |||
| #include "gtest/gtest.h" | |||
| class LevelDBTest : public ::testing::Test { | |||
| protected: | |||
| leveldb::DB* db; | |||
| leveldb::Options options; | |||
| std::string db_path = "/tmp/testdb"; | |||
| void SetUp() override { | |||
| options.create_if_missing = true; | |||
| leveldb::Status status = leveldb::DB::Open(options, db_path, &db); | |||
| ASSERT_TRUE(status.ok()) << "Failed to open DB: " << status.ToString(); | |||
| } | |||
| void TearDown() override { | |||
| delete db; | |||
| } | |||
| }; | |||
| TEST_F(LevelDBTest, CompactionTest) { | |||
| // 插入数据 | |||
| db->Put(leveldb::WriteOptions(), "start", "value1"); | |||
| db->Put(leveldb::WriteOptions(), "end", "value2"); | |||
| db->Put(leveldb::WriteOptions(), "key_to_delete", "value3"); | |||
| // 删除一个键,模拟删除标记 | |||
| db->Delete(leveldb::WriteOptions(), "key_to_delete"); | |||
| // 触发压缩 | |||
| leveldb::Slice begin_key("start"); | |||
| leveldb::Slice end_key("end"); | |||
| db->CompactRange(&begin_key, &end_key); | |||
| // 验证压缩后的数据 | |||
| std::string value; | |||
| leveldb::Status status = db->Get(leveldb::ReadOptions(), "key_to_delete", &value); | |||
| if (!status.ok()) { | |||
| std::cout << "'key_to_delete' was successfully removed during compaction." << std::endl; | |||
| } else { | |||
| FAIL() << "Unexpected: 'key_to_delete' still exists: " << value; | |||
| } | |||
| } | |||
| int main(int argc, char** argv) { | |||
| ::testing::InitGoogleTest(&argc, argv); | |||
| return RUN_ALL_TESTS(); | |||
| } | |||
+ 0
- 28
examples/ValueConvertTest.cc
View File
| @ -1,28 +0,0 @@ | |||
| #include <cassert> | |||
| #include <iostream> | |||
| #include "leveldb/db.h" | |||
| int main(){ | |||
| leveldb::DB* db; | |||
| leveldb::Options options; | |||
| options.create_if_missing = true; | |||
| options.kvSepType = leveldb::kVSepBeforeSSD; | |||
| leveldb::Status status = leveldb::DB::Open(options, "/tmp/testdb", &db); | |||
| std::cout<< status.ToString() << '\n'; | |||
| std::string fill_str = ""; | |||
| // fill_str 4KB | |||
| for(int i = 1; i<= 4096; i++){ | |||
| fill_str.push_back('%'); | |||
| } | |||
| for(int i = 1E5; i>= 1; i--){ | |||
| status = db -> Put(leveldb::WriteOptions(), "key" + std::to_string(i), "val" + std::to_string(i) + fill_str); | |||
| } | |||
| if(status.ok()) { | |||
| std::string val; | |||
| for(int i = 0; i< 1E5; i++){ | |||
| status = db -> Get(leveldb::ReadOptions(), "key" + std::to_string(i), &val); | |||
| if(status.ok()) std::cout<< "Find value of \'key"<<i<<"\' From db:" << val << "\n"; | |||
| } | |||
| } | |||
| delete db; | |||
| } | |||
+ 0
- 173
examples/WiscKeyTest_1.cc
View File
| @ -1,173 +0,0 @@ | |||
| #include "WiscKeyTest_1.h" | |||
| #include <fstream> | |||
| #include <algorithm> | |||
| #include <vector> | |||
| #include <ctime> | |||
| #include <cstdlib> | |||
| typedef struct WiscKey { // 集成了leveldb数据库和一个logfile链表 | |||
| string dir; | |||
| DB * leveldb; | |||
| FILE * logfile; | |||
| } WK; | |||
| static bool wisckey_get(WK * wk, string &key, string &value) | |||
| { | |||
| cout << "\n\t\tGet Function\n\n"; | |||
| cout << "Key Received: " << key << endl; | |||
| cout << "Value Received: " << value << endl; | |||
| string offsetinfo; | |||
| const bool found = leveldb_get(wk->leveldb, key, offsetinfo); | |||
| if (found) { | |||
| cout << "Offset and Length: " << offsetinfo << endl; | |||
| } | |||
| else { | |||
| cout << "Record:Not Found" << endl; | |||
| return false; | |||
| } | |||
| std::string value_offset; | |||
| std::string value_length; | |||
| std::string s = offsetinfo; | |||
| std::string delimiter = "&&"; | |||
| size_t pos = 0; | |||
| std::string token; | |||
| while ((pos = s.find(delimiter)) != std::string::npos) { | |||
| token = s.substr(0, pos); | |||
| value_offset = token; | |||
| s.erase(0, pos + delimiter.length()); | |||
| } | |||
| value_length = s; | |||
| cout << "Value Offset: " << value_offset << endl; | |||
| cout << "Value Length: " << value_length << endl; | |||
| std::string::size_type sz; | |||
| long offset = std::stol (value_offset,&sz); | |||
| long length = std::stol (value_length,&sz); | |||
| //cout << offset << length << endl; | |||
| std::string value_record; | |||
| //cout << ftell(wk->logread) << endl; | |||
| fseek(wk->logfile,offset,SEEK_SET); | |||
| //cout << ftell(wk->logfile) << endl; | |||
| //rewind(wk->logfile); | |||
| //cout << ftell(wk->logfile) << endl; | |||
| fread(&value_record,length,1,wk->logfile); | |||
| //rewind(wk->logfile); | |||
| cout << "LogFile Value: " << value_record << endl; | |||
| return true; | |||
| } | |||
| static void wisckey_set(WK * wk, string &key, string &value) | |||
| { | |||
| long offset = ftell (wk->logfile); | |||
| long size = sizeof(value); | |||
| std::string vlog_offset = std::to_string(offset); | |||
| std::string vlog_size = std::to_string(size); | |||
| std::stringstream vlog_value; | |||
| vlog_value << vlog_offset << "&&" << vlog_size; | |||
| std::string s = vlog_value.str(); | |||
| fwrite (&value, sizeof(value),1,wk->logfile); | |||
| leveldb_set(wk->leveldb,key,s); | |||
| } | |||
| static void wisckey_del(WK * wk, string &key) | |||
| { | |||
| cout << "Key: " << key << endl; | |||
| leveldb_del(wk->leveldb,key); | |||
| } | |||
| static WK * open_wisckey(const string& dirname) | |||
| { | |||
| WK * wk = new WK; | |||
| wk->leveldb = open_leveldb(dirname); | |||
| wk->dir = dirname; | |||
| wk->logfile = fopen("logfile","wb+"); | |||
| return wk; | |||
| } | |||
| static void close_wisckey(WK * wk) | |||
| { | |||
| fclose(wk->logfile); | |||
| delete wk->leveldb; | |||
| delete wk; | |||
| } | |||
| // For testing wisckey functionality | |||
| static void testing_function(WK * wk, string &key, string &value) | |||
| { | |||
| /* Setting Value and Testing it */ | |||
| cout << "\n\n\t\tInput Received\n" << endl; | |||
| cout << "Key: " << key << endl; | |||
| cout << "Value: " << value << endl; | |||
| wisckey_set(wk,key,value); | |||
| const bool found = wisckey_get(wk,key,value); | |||
| if (found) { | |||
| cout << "Record Matched" << endl; | |||
| } | |||
| /* Deleting Value */ | |||
| cout << "\n\n\t\tDelete Operation\n" << endl; | |||
| wisckey_del(wk,key); | |||
| cout << "Delete Successful" << endl; | |||
| /* Read after Delete */ | |||
| cout << "\n\n\t\tInput Received\n" << endl; | |||
| string testkey= "1001224314"; | |||
| string testvalue = "Abhishek Sharma"; | |||
| cout << "Key: " << testkey << endl; | |||
| cout << "Value: " << testvalue << endl; | |||
| const bool testfound = wisckey_get(wk,testkey,testvalue); | |||
| if (testfound) { | |||
| cout << "Record Matched" << endl; | |||
| } | |||
| } | |||
| int main(int argc, char ** argv) | |||
| { | |||
| if (argc < 2) { | |||
| cout << "Usage: " << argv[0] << " <value-size>" << endl; | |||
| exit(0); | |||
| } | |||
| const size_t value_size = std::stoull(argv[1], NULL, 10); | |||
| if (value_size < 1 || value_size > 100000) { | |||
| cout << " <value-size> must be positive and less then 100000" << endl; | |||
| exit(0); | |||
| } | |||
| WK * wk = open_wisckey("wisckey_test_dir"); // 打开数据库 | |||
| if (wk == NULL) { | |||
| cerr << "Open WiscKey failed!" << endl; | |||
| exit(1); | |||
| } | |||
| char * vbuf = new char[value_size]; | |||
| for (size_t i = 0; i < value_size; i++) { | |||
| vbuf[i] = rand(); | |||
| } | |||
| string value = string(vbuf, value_size); | |||
| size_t nfill = 1000000000 / (value_size + 8); // 生成 nfill = 1,000,000,000 / (value_size + 8) 条随机键值对 | |||
| clock_t t0 = clock(); | |||
| size_t p1 = nfill / 40; // 将插入任务分成四十份 | |||
| for (size_t j = 0; j < nfill; j++) { | |||
| string key = std::to_string(((size_t)rand())*((size_t)rand())); | |||
| wisckey_set(wk, key, value); | |||
| if (j >= p1) { | |||
| clock_t dt = clock() - t0; | |||
| cout << "progress: " << j+1 << "/" << nfill << " time elapsed: " << dt * 1.0e-6 << endl << std::flush; // 打印进度和已经消耗的时间 | |||
| p1 += (nfill / 40); | |||
| } | |||
| } | |||
| clock_t dt = clock() - t0; | |||
| cout << "time elapsed: " << dt * 1.0e-6 << " seconds" << endl; | |||
| close_wisckey(wk); | |||
| destroy_leveldb("wisckey_test_dir"); | |||
| remove("logfile"); | |||
| exit(0); | |||
| } | |||
+ 0
- 81
examples/WiscKeyTest_1.h
View File
| @ -1,81 +0,0 @@ | |||
| #pragma once | |||
| #include <assert.h> | |||
| #include <vector> | |||
| #include <iostream> | |||
| #include <sstream> | |||
| #include <string> | |||
| #include <ctime> | |||
| #include <algorithm> | |||
| #include <cstdlib> | |||
| // #include <boost/algorithm/string.hpp> | |||
| #include "leveldb/db.h" | |||
| #include "leveldb/filter_policy.h" | |||
| #include "leveldb/write_batch.h" | |||
| using std::string; | |||
| using std::vector; | |||
| using std::cin; | |||
| using std::cout; | |||
| using std::cerr; | |||
| using std::endl; | |||
| using std::stringstream; | |||
| using leveldb::ReadOptions; | |||
| using leveldb::Options; | |||
| using leveldb::Status; | |||
| using leveldb::WriteBatch; | |||
| using leveldb::WriteOptions; | |||
| using leveldb::DB; | |||
| static bool | |||
| leveldb_get(DB * db, string &key, string &value) | |||
| { | |||
| // assert(lldb); | |||
| ReadOptions ropt; | |||
| Status s = db->Get(ropt, key, &value); | |||
| assert(s.ok()); | |||
| if (s.IsNotFound()) { | |||
| return false; | |||
| } else { | |||
| return true; | |||
| } | |||
| } | |||
| static void | |||
| leveldb_set(DB * db, string &key, string &value) | |||
| { | |||
| WriteBatch wb; | |||
| Status s; | |||
| WriteOptions wopt; | |||
| wb.Put(key, value); | |||
| s = db->Write(wopt, &wb); | |||
| assert(s.ok()); | |||
| } | |||
| static void | |||
| leveldb_del(DB * db, string &key) | |||
| { | |||
| WriteOptions wopt; | |||
| Status s; | |||
| s = db->Delete(wopt, key); | |||
| assert(s.ok()); | |||
| } | |||
| static void | |||
| destroy_leveldb(const string &dirname) | |||
| { | |||
| Options options; | |||
| leveldb::DestroyDB(dirname, options); | |||
| } | |||
| static DB * | |||
| open_leveldb(const string &dirname) | |||
| { | |||
| Options options; | |||
| options.create_if_missing = true; | |||
| options.filter_policy = leveldb::NewBloomFilterPolicy(10); | |||
| options.write_buffer_size = 1u << 21; | |||
| destroy_leveldb(dirname); | |||
| DB * db = NULL; | |||
| Status s = DB::Open(options, dirname, &db); | |||
| return db; | |||
| } | |||
+ 0
- 76
examples/iterator_test.cc
View File
| @ -1,76 +0,0 @@ | |||
| #include <iostream> | |||
| #include "leveldb/db.h" | |||
| #include "leveldb/options.h" | |||
| #include "gtest/gtest.h" | |||
| class RangeQueryTest : public ::testing::Test { | |||
| protected: | |||
| leveldb::DB* db; | |||
| leveldb::Options options; | |||
| std::string db_path = "/tmp/range_testdb"; | |||
| void SetUp() override { | |||
| options.create_if_missing = true; | |||
| leveldb::Status status = leveldb::DB::Open(options, db_path, &db); | |||
| ASSERT_TRUE(status.ok()) << "Failed to open DB: " << status.ToString(); | |||
| } | |||
| void TearDown() override { | |||
| delete db; | |||
| } | |||
| }; | |||
| TEST_F(RangeQueryTest, TestRangeQuery) { | |||
| // 插入一组键值对 | |||
| std::vector<std::pair<std::string, std::string>> data = { | |||
| {"a_key1", "value1"}, | |||
| {"a_key2", "value2"}, | |||
| {"b_key3", "value3"}, | |||
| {"b_key4", "value4"}, | |||
| {"c_key5", "value5"} | |||
| }; | |||
| for (const auto& pair : data) { | |||
| const std::string& key = pair.first; | |||
| const std::string& value = pair.second; | |||
| leveldb::Status status = db->Put(leveldb::WriteOptions(), key, value); | |||
| ASSERT_TRUE(status.ok()) << "Failed to put data: " << status.ToString(); | |||
| } | |||
| // 查询范围内的键值对 | |||
| std::string range_start = "a_key1"; | |||
| std::string range_end = "b_key4"; | |||
| std::vector<std::pair<std::string, std::string>> expected_data = { | |||
| {"a_key1", "value1"}, | |||
| {"a_key2", "value2"}, | |||
| {"b_key3", "value3"}, | |||
| {"b_key4", "value4"} | |||
| }; | |||
| leveldb::Iterator* it = db->NewIterator(leveldb::ReadOptions()); | |||
| it->Seek(range_start); // 从范围起始位置开始 | |||
| std::vector<std::pair<std::string, std::string>> actual_data; | |||
| while (it->Valid() && it->key().ToString() <= range_end) { | |||
| actual_data.emplace_back(it->key().ToString(), it->value().ToString()); | |||
| it->Next(); | |||
| } | |||
| delete it; | |||
| // 验证范围查询结果是否符合预期 | |||
| ASSERT_EQ(actual_data.size(), expected_data.size()) << "Range query results size mismatch."; | |||
| for (size_t i = 0; i < actual_data.size(); ++i) { | |||
| EXPECT_EQ(actual_data[i].first, expected_data[i].first) << "Key mismatch at index " << i; | |||
| EXPECT_EQ(actual_data[i].second, expected_data[i].second) << "Value mismatch at index " << i; | |||
| } | |||
| // 输出范围查询结果 | |||
| for (const auto& pair : actual_data) { | |||
| const std::string& key = pair.first; | |||
| const std::string& value = pair.second; | |||
| std::cout << "Key: " << key << ", Value: " << value << std::endl; | |||
| } | |||
| } | |||
| int main(int argc, char** argv) { | |||
| ::testing::InitGoogleTest(&argc, argv); | |||
| return RUN_ALL_TESTS(); | |||
| } | |||
+ 0
- 43
examples/kv_sep_test.cc
View File
| @ -1,43 +0,0 @@ | |||
| #include <cassert> | |||
| #include <iostream> | |||
| #include "leveldb/db.h" | |||
| #include "db/db_impl.h" | |||
| int main() { | |||
| leveldb::DB* db; | |||
| leveldb::Options options; | |||
| options.create_if_missing = true; | |||
| options.kvSepType = leveldb::kVSepBeforeMem; | |||
| leveldb::Status status = leveldb::DB::Open(options, "/tmp/testdb", &db); | |||
| if (!status.ok()) { | |||
| std::cerr << "Failed to open DB: " << status.ToString() << '\n'; | |||
| return 1; | |||
| } | |||
| // 使用 dynamic_cast 将基类指针转换为 DBImpl | |||
| auto* dbimpl = static_cast<leveldb::DBImpl*>(db); | |||
| if (dbimpl == nullptr) { | |||
| std::cerr << "Failed to cast to DBImpl\n"; | |||
| delete db; | |||
| return 1; | |||
| } | |||
| status = dbimpl->Put(leveldb::WriteOptions(), "key1", "val1"); | |||
| if (status.ok()) { | |||
| std::string val; | |||
| status = dbimpl->Get(leveldb::ReadOptions(), "key1", &val); | |||
| std::cout << "Find value of 'key1' From db: " << val << "\n"; | |||
| } | |||
| if (status.ok()) { | |||
| std::string val; | |||
| dbimpl->Delete(leveldb::WriteOptions(), "key1"); | |||
| status = dbimpl->Get(leveldb::ReadOptions(), "key1", &val); | |||
| // Not found. | |||
| std::cout << status.ToString() << '\n'; | |||
| } | |||
| delete db; | |||
| return 0; | |||
| } | |||
+ 0
- 23
examples/main.cc
View File
| @ -1,23 +0,0 @@ | |||
| #include <cassert> | |||
| #include <iostream> | |||
| #include "leveldb/db.h" | |||
| #include "gtest/gtest.h" | |||
| TEST(Usage, InitDb) { | |||
| leveldb::DB* db; | |||
| leveldb::Options options; | |||
| options.create_if_missing = true; | |||
| leveldb::Status status = leveldb::DB::Open(options, "/tmp/test_db", &db); | |||
| std::cout << "db started, status: " << status.ToString() << std::endl; | |||
| assert(status.ok()); | |||
| delete db; | |||
| } | |||
| int main(int argc, char** argv) { | |||
| printf("Running main() from %s\n", __FILE__); | |||
| ::testing::InitGoogleTest(&argc, argv); | |||
| return RUN_ALL_TESTS(); | |||
| } | |||
+ 0
- 25
examples/test_1.cc
View File
| @ -1,25 +0,0 @@ | |||
| #include <cassert> | |||
| #include <iostream> | |||
| #include "leveldb/db.h" | |||
| int main(){ | |||
| leveldb::DB* db; | |||
| leveldb::Options options; | |||
| options.create_if_missing = true; | |||
| leveldb::Status status = leveldb::DB::Open(options, "/tmp/testdb", &db); | |||
| std::cout<< status.ToString() << '\n'; | |||
| status = db -> Put(leveldb::WriteOptions(), "key1", "val1"); | |||
| if(status.ok()) { | |||
| std::string val; | |||
| status = db -> Get(leveldb::ReadOptions(), "key1", &val); | |||
| std::cout<< "Find value of \'key1\' From db:" << val << "\n"; | |||
| } | |||
| if(status.ok()){ | |||
| std::string val; | |||
| db -> Delete(leveldb::WriteOptions(), "key1"); | |||
| status = db -> Get(leveldb::ReadOptions(), "key1", &val); | |||
| //Not find. | |||
| std::cout<< status.ToString() <<'\n'; | |||
| } | |||
| delete db; | |||
| } | |||
+ 0
- 3
gitpush.sh
View File
| @ -1,3 +0,0 @@ | |||
| git add . | |||
| git commit -m "$1" | |||
| git push origin main | |||
+ 0
- 8
helpers/memenv/memenv.cc
View File
BIN
images/1.png
View File
{kind=link}
| Before | After |
|---|---|

|
|
| Width: 807 | Height: 151 | Size: 9.1 KiB |
BIN
images/10.png
View File
{kind=link}
| Before | After |
|---|---|

|
|
| Width: 1167 | Height: 183 | Size: 28 KiB |
BIN
images/11.png
View File
{kind=link}
| Before | After |
|---|---|
|
|
| Width: 828 | Height: 361 | Size: 129 KiB |
BIN
images/12.webp
View File
{kind=link}
| Before | After |
|---|---|

|
BIN
images/13.png
View File
{kind=link}
| Before | After |
|---|---|
|
|
| Width: 3791 | Height: 1024 | Size: 106 KiB |
BIN
images/14.png
View File
{kind=link}
| Before | After |
|---|---|
|
|
| Width: 3158 | Height: 1729 | Size: 223 KiB |
BIN
images/15.png
View File
{kind=link}
| Before | After |
|---|---|
|
|
| Width: 2879 | Height: 2220 | Size: 276 KiB |
BIN
images/16.png
View File
{kind=link}
| Before | After |
|---|---|

|
|
| Width: 870 | Height: 849 | Size: 96 KiB |
BIN
images/2.png
View File
{kind=link}
| Before | After |
|---|---|

|
|
| Width: 1017 | Height: 171 | Size: 13 KiB |
BIN
images/3.png
View File
{kind=link}
| Before | After |
|---|---|
|
|
| Width: 557 | Height: 342 | Size: 76 KiB |
BIN
images/4.png
View File
{kind=link}
| Before | After |
|---|---|
|
|
| Width: 793 | Height: 510 | Size: 81 KiB |
BIN
images/5.png
View File
{kind=link}
| Before | After |
|---|---|
|
|
| Width: 737 | Height: 212 | Size: 96 KiB |
BIN
images/6.png
View File
{kind=link}
| Before | After |
|---|---|
|
|
| Width: 738 | Height: 386 | Size: 75 KiB |
BIN
images/7.png
View File
{kind=link}
| Before | After |
|---|---|
|
|
| Width: 754 | Height: 340 | Size: 40 KiB |
BIN
images/8.png
View File
{kind=link}
| Before | After |
|---|---|

|
|
| Width: 703 | Height: 174 | Size: 24 KiB |
BIN
images/9.png
View File
{kind=link}
| Before | After |
|---|---|
|
|
| Width: 857 | Height: 183 | Size: 13 KiB |
BIN
images/GC_test.png
View File
{kind=link}
| Before | After |
|---|---|

|
|
| Width: 1918 | Height: 1032 | Size: 128 KiB |
BIN
images/c1.1.png
View File
{kind=link}
| Before | After |
|---|---|
|
|
| Width: 1495 | Height: 719 | Size: 51 KiB |
BIN
images/c1.2.png
View File
{kind=link}
| Before | After |
|---|---|
|
|
| Width: 1511 | Height: 723 | Size: 56 KiB |
BIN
images/c1.png
View File
{kind=link}
| Before | After |
|---|---|
|
|
| Width: 1359 | Height: 617 | Size: 42 KiB |
BIN
images/c10.png
View File
{kind=link}
| Before | After |
|---|---|
|
|
| Width: 1407 | Height: 588 | Size: 127 KiB |
BIN
images/c2.png
View File
{kind=link}
| Before | After |
|---|---|
|
|
| Width: 1483 | Height: 617 | Size: 55 KiB |
BIN
images/c3.png
View File
{kind=link}
| Before | After |
|---|---|
|
|
| Width: 1373 | Height: 521 | Size: 47 KiB |
BIN
images/c4.png
View File
{kind=link}
| Before | After |
|---|---|
|
|
| Width: 1599 | Height: 1217 | Size: 144 KiB |
BIN
images/c5.png
View File
{kind=link}
| Before | After |
|---|---|
|
|
| Width: 1571 | Height: 1223 | Size: 144 KiB |
BIN
images/c6.png
View File
{kind=link}
| Before | After |
|---|---|
|
|
| Width: 3196 | Height: 965 | Size: 234 KiB |
BIN
images/c7.png
View File
{kind=link}
| Before | After |
|---|---|
|
|
| Width: 1479 | Height: 1021 | Size: 285 KiB |
BIN
images/c8.png
View File
{kind=link}
| Before | After |
|---|---|
|
|
| Width: 1517 | Height: 1057 | Size: 453 KiB |
BIN
images/c9.png
View File
{kind=link}
| Before | After |
|---|---|
|
|
| Width: 1397 | Height: 585 | Size: 136 KiB |
BIN
images/field_test.png
View File
{kind=link}
| Before | After |
|---|---|

|
|
| Width: 1918 | Height: 1032 | Size: 132 KiB |
BIN
images/iterate_test.png
View File
{kind=link}
| Before | After |
|---|---|

|
|
| Width: 1918 | Height: 1032 | Size: 147 KiB |
BIN
images/kv_sep_test.png
View File
{kind=link}
| Before | After |
|---|---|
|
|
| Width: 1918 | Height: 1032 | Size: 135 KiB |
+ 14
- 3
include/leveldb/db.h
View File
+ 0
- 22
include/leveldb/env.h
View File
+ 0
- 21
include/leveldb/options.h
View File
+ 3
- 0
include/leveldb/slice.h
View File
+ 3
- 0
include/leveldb/write_batch.h
View File
+ 0
- 0
prefetch.txt
View File
+ 74
- 0
test/db_test2.cc
View File
| @ -0,0 +1,74 @@ | |||
| #include "leveldb/db.h" | |||
| #include "leveldb/filter_policy.h" | |||
| #include <iostream> | |||
| #include <cstdlib> | |||
| #include <ctime> | |||
| using namespace leveldb; | |||
| constexpr int value_size = 2048; | |||
| constexpr int data_size = 256 << 20; | |||
| // 3. 数据管理(Manifest/创建/恢复数据库) | |||
| Status OpenDB(std::string dbName, DB **db) { | |||
| Options options; | |||
| options.create_if_missing = true; | |||
| options.filter_policy = NewBloomFilterPolicy(10); | |||
| return DB::Open(options, dbName, db); | |||
| } | |||
| // 1. 存储(数据结构与写入) | |||
| // 4. 数据合并(Compaction) | |||
| void InsertData(DB *db) { | |||
| WriteOptions writeOptions; | |||
| int key_num = data_size / value_size; | |||
| srand(static_cast<unsigned int>(time(0))); | |||
| for (int i = 0; i < key_num; i++) { | |||
| int key_ = rand() % key_num+1; | |||
| std::string key = std::to_string(key_); | |||
| std::string value(value_size, 'a'); | |||
| db->Put(writeOptions, key, value); | |||
| } | |||
| } | |||
| // 2. 数据访问(如何读数据) | |||
| void GetData(DB *db, int size = (1 << 30)) { | |||
| ReadOptions readOptions; | |||
| int key_num = data_size / value_size; | |||
| // 点查 | |||
| srand(static_cast<unsigned int>(time(0))); | |||
| for (int i = 0; i < 100; i++) { | |||
| int key_ = rand() % key_num+1; | |||
| std::string key = std::to_string(key_); | |||
| std::string value; | |||
| db->Get(readOptions, key, &value); | |||
| } | |||
| // 范围查询 | |||
| Iterator *iter = db->NewIterator(readOptions); | |||
| iter->SeekToFirst(); | |||
| while (iter->Valid()) { | |||
| iter->Next(); | |||
| } | |||
| delete iter; | |||
| } | |||
| int main() { | |||
| DB *db; | |||
| if(OpenDB("testdb", &db).ok()) { | |||
| InsertData(db); | |||
| delete db; | |||
| } | |||
| if(OpenDB("testdb", &db).ok()) { | |||
| GetData(db); | |||
| delete db; | |||
| } | |||
| return 0; | |||
| } | |||
examples/field_test.cc → test/field_test.cc
View File
+ 114
- 0
test/ttl_test.cc
View File
| @ -0,0 +1,114 @@ | |||
| #include "gtest/gtest.h" | |||
| #include "leveldb/env.h" | |||
| #include "leveldb/db.h" | |||
| using namespace leveldb; | |||
| constexpr int value_size = 2048; | |||
| constexpr int data_size = 128 << 20; | |||
| Status OpenDB(std::string dbName, DB **db) { | |||
| Options options; | |||
| options.create_if_missing = true; | |||
| return DB::Open(options, dbName, db); | |||
| } | |||
| void InsertData(DB *db, uint64_t ttl/* second */) { | |||
| WriteOptions writeOptions; | |||
| int key_num = data_size / value_size; | |||
| srand(static_cast<unsigned int>(time(0))); | |||
| for (int i = 0; i < key_num; i++) { | |||
| int key_ = rand() % key_num+1; | |||
| std::string key = std::to_string(key_); | |||
| std::string value(value_size, 'a'); | |||
| db->Put(writeOptions, key, value, ttl); | |||
| } | |||
| } | |||
| void GetData(DB *db, int size = (1 << 30)) { | |||
| ReadOptions readOptions; | |||
| int key_num = data_size / value_size; | |||
| // 点查 | |||
| srand(static_cast<unsigned int>(time(0))); | |||
| for (int i = 0; i < 100; i++) { | |||
| int key_ = rand() % key_num+1; | |||
| std::string key = std::to_string(key_); | |||
| std::string value; | |||
| db->Get(readOptions, key, &value); | |||
| } | |||
| } | |||
| TEST(TestTTL, ReadTTL) { | |||
| DB *db; | |||
| if(OpenDB("testdb", &db).ok() == false) { | |||
| std::cerr << "open db failed" << std::endl; | |||
| abort(); | |||
| } | |||
| uint64_t ttl = 20; | |||
| InsertData(db, ttl); | |||
| ReadOptions readOptions; | |||
| Status status; | |||
| int key_num = data_size / value_size; | |||
| srand(static_cast<unsigned int>(time(0))); | |||
| for (int i = 0; i < 100; i++) { | |||
| int key_ = rand() % key_num+1; | |||
| std::string key = std::to_string(key_); | |||
| std::string value; | |||
| status = db->Get(readOptions, key, &value); | |||
| ASSERT_TRUE(status.ok()); | |||
| } | |||
| Env::Default()->SleepForMicroseconds(ttl * 1000000); | |||
| for (int i = 0; i < 100; i++) { | |||
| int key_ = rand() % key_num+1; | |||
| std::string key = std::to_string(key_); | |||
| std::string value; | |||
| status = db->Get(readOptions, key, &value); | |||
| ASSERT_FALSE(status.ok()); // 经过超长时间之后所有的键值对应该都过期了,心 | |||
| } | |||
| } | |||
| TEST(TestTTL, CompactionTTL) { | |||
| DB *db; | |||
| if(OpenDB("testdb", &db).ok() == false) { | |||
| std::cerr << "open db failed" << std::endl; | |||
| abort(); | |||
| } | |||
| uint64_t ttl = 20; | |||
| InsertData(db, ttl); | |||
| leveldb::Range ranges[1]; | |||
| ranges[0] = leveldb::Range("-", "A"); | |||
| uint64_t sizes[1]; | |||
| db->GetApproximateSizes(ranges, 1, sizes); | |||
| ASSERT_GT(sizes[0], 0); | |||
| Env::Default()->SleepForMicroseconds(ttl * 1000000); | |||
| db->CompactRange(nullptr, nullptr); | |||
| // leveldb::Range ranges[1]; // 这里为什么要重复定义?心 | |||
| ranges[0] = leveldb::Range("-", "A"); | |||
| // uint64_t sizes[1]; // 心 | |||
| db->GetApproximateSizes(ranges, 1, sizes); | |||
| ASSERT_EQ(sizes[0], 0); | |||
| } | |||
| int main(int argc, char** argv) { | |||
| // All tests currently run with the same read-only file limits. | |||
| testing::InitGoogleTest(&argc, argv); | |||
| return RUN_ALL_TESTS(); | |||
| } | |||
+ 1
- 0
third_party/benchmark
| @ -0,0 +1 @@ | |||
| Subproject commit f7547e29ccaed7b64ef4f7495ecfff1c9f6f3d03 | |||
+ 0
- 5
third_party/benchmark/.clang-format
View File
| @ -1,5 +0,0 @@ | |||
| --- | |||
| Language: Cpp | |||
| BasedOnStyle: Google | |||
| PointerAlignment: Left | |||
| ... | |||
+ 0
- 7
third_party/benchmark/.clang-tidy
View File
| @ -1,7 +0,0 @@ | |||
| --- | |||
| Checks: 'clang-analyzer-*,readability-redundant-*,performance-*' | |||
| WarningsAsErrors: 'clang-analyzer-*,readability-redundant-*,performance-*' | |||
| HeaderFilterRegex: '.*' | |||
| AnalyzeTemporaryDtors: false | |||
| FormatStyle: none | |||
| User: user | |||
+ 0
- 32
third_party/benchmark/.github/ISSUE_TEMPLATE/bug_report.md
View File
| @ -1,32 +0,0 @@ | |||
| --- | |||
| name: Bug report | |||
| about: Create a report to help us improve | |||
| title: "[BUG]" | |||
| labels: '' | |||
| assignees: '' | |||
| --- | |||
| **Describe the bug** | |||
| A clear and concise description of what the bug is. | |||
| **System** | |||
| Which OS, compiler, and compiler version are you using: | |||
| - OS: | |||
| - Compiler and version: | |||
| **To reproduce** | |||
| Steps to reproduce the behavior: | |||
| 1. sync to commit ... | |||
| 2. cmake/bazel... | |||
| 3. make ... | |||
| 4. See error | |||
| **Expected behavior** | |||
| A clear and concise description of what you expected to happen. | |||
| **Screenshots** | |||
| If applicable, add screenshots to help explain your problem. | |||
| **Additional context** | |||
| Add any other context about the problem here. | |||
+ 0
- 20
third_party/benchmark/.github/ISSUE_TEMPLATE/feature_request.md
View File
| @ -1,20 +0,0 @@ | |||
| --- | |||
| name: Feature request | |||
| about: Suggest an idea for this project | |||
| title: "[FR]" | |||
| labels: '' | |||
| assignees: '' | |||
| --- | |||
| **Is your feature request related to a problem? Please describe.** | |||
| A clear and concise description of what the problem is. Ex. I'm always frustrated when [...] | |||
| **Describe the solution you'd like** | |||
| A clear and concise description of what you want to happen. | |||
| **Describe alternatives you've considered** | |||
| A clear and concise description of any alternative solutions or features you've considered. | |||
| **Additional context** | |||
| Add any other context or screenshots about the feature request here. | |||
+ 0
- 13
third_party/benchmark/.github/install_bazel.sh
View File
| @ -1,13 +0,0 @@ | |||
| if ! bazel version; then | |||
| arch=$(uname -m) | |||
| if [ "$arch" == "aarch64" ]; then | |||
| arch="arm64" | |||
| fi | |||
| echo "Installing wget and downloading $arch Bazel binary from GitHub releases." | |||
| yum install -y wget | |||
| wget "https://github.com/bazelbuild/bazel/releases/download/6.0.0/bazel-6.0.0-linux-$arch" -O /usr/local/bin/bazel | |||
| chmod +x /usr/local/bin/bazel | |||
| else | |||
| # bazel is installed for the correct architecture | |||
| exit 0 | |||
| fi | |||
+ 0
- 27
third_party/benchmark/.github/libcxx-setup.sh
View File
| @ -1,27 +0,0 @@ | |||
| #!/usr/bin/env bash | |||
| # Checkout LLVM sources | |||
| #git clone --depth=1 https://github.com/llvm/llvm-project.git llvm-project | |||
| # | |||
| ## Setup libc++ options | |||
| #if [ -z "$BUILD_32_BITS" ]; then | |||
| # export BUILD_32_BITS=OFF && echo disabling 32 bit build | |||
| #fi | |||
| # | |||
| ## Build and install libc++ (Use unstable ABI for better sanitizer coverage) | |||
| #cd ./llvm-project | |||
| #cmake -DCMAKE_C_COMPILER=${CC} \ | |||
| # -DCMAKE_CXX_COMPILER=${CXX} \ | |||
| # -DCMAKE_BUILD_TYPE=RelWithDebInfo \ | |||
| # -DCMAKE_INSTALL_PREFIX=/usr \ | |||
| # -DLIBCXX_ABI_UNSTABLE=OFF \ | |||
| # -DLLVM_USE_SANITIZER=${LIBCXX_SANITIZER} \ | |||
| # -DLLVM_BUILD_32_BITS=${BUILD_32_BITS} \ | |||
| # -DLLVM_ENABLE_RUNTIMES='libcxx;libcxxabi' \ | |||
| # -S llvm -B llvm-build -G "Unix Makefiles" | |||
| #make -C llvm-build -j3 cxx cxxabi | |||
| #sudo make -C llvm-build install-cxx install-cxxabi | |||
| #cd .. | |||
| sudo apt update | |||
| sudo apt -y install libc++-dev libc++abi-dev | |||
+ 0
- 35
third_party/benchmark/.github/workflows/bazel.yml
View File
| @ -1,35 +0,0 @@ | |||
| name: bazel | |||
| on: | |||
| push: {} | |||
| pull_request: {} | |||
| jobs: | |||
| job: | |||
| name: bazel.${{ matrix.os }} | |||
| runs-on: ${{ matrix.os }} | |||
| strategy: | |||
| fail-fast: false | |||
| matrix: | |||
| os: [ubuntu-latest, macos-latest, windows-2022] | |||
| steps: | |||
| - uses: actions/checkout@v3 | |||
| - name: mount bazel cache | |||
| uses: actions/cache@v3 | |||
| env: | |||
| cache-name: bazel-cache | |||
| with: | |||
| path: "~/.cache/bazel" | |||
| key: ${{ env.cache-name }}-${{ matrix.os }}-${{ github.ref }} | |||
| restore-keys: | | |||
| ${{ env.cache-name }}-${{ matrix.os }}-main | |||
| - name: build | |||
| run: | | |||
| bazel build //:benchmark //:benchmark_main //test/... | |||
| - name: test | |||
| run: | | |||
| bazel test --test_output=all //test/... | |||
+ 0
- 46
third_party/benchmark/.github/workflows/build-and-test-min-cmake.yml
View File
| @ -1,46 +0,0 @@ | |||
| name: build-and-test-min-cmake | |||
| on: | |||
| push: | |||
| branches: [ main ] | |||
| pull_request: | |||
| branches: [ main ] | |||
| jobs: | |||
| job: | |||
| name: ${{ matrix.os }}.min-cmake | |||
| runs-on: ${{ matrix.os }} | |||
| strategy: | |||
| fail-fast: false | |||
| matrix: | |||
| os: [ubuntu-latest, macos-latest] | |||
| steps: | |||
| - uses: actions/checkout@v3 | |||
| - uses: lukka/get-cmake@latest | |||
| with: | |||
| cmakeVersion: 3.10.0 | |||
| - name: create build environment | |||
| run: cmake -E make_directory ${{ runner.workspace }}/_build | |||
| - name: setup cmake initial cache | |||
| run: touch compiler-cache.cmake | |||
| - name: configure cmake | |||
| env: | |||
| CXX: ${{ matrix.compiler }} | |||
| shell: bash | |||
| working-directory: ${{ runner.workspace }}/_build | |||
| run: > | |||
| cmake -C ${{ github.workspace }}/compiler-cache.cmake | |||
| $GITHUB_WORKSPACE | |||
| -DBENCHMARK_DOWNLOAD_DEPENDENCIES=ON | |||
| -DCMAKE_CXX_VISIBILITY_PRESET=hidden | |||
| -DCMAKE_VISIBILITY_INLINES_HIDDEN=ON | |||
| - name: build | |||
| shell: bash | |||
| working-directory: ${{ runner.workspace }}/_build | |||
| run: cmake --build . | |||
+ 0
- 51
third_party/benchmark/.github/workflows/build-and-test-perfcounters.yml
View File
| @ -1,51 +0,0 @@ | |||
| name: build-and-test-perfcounters | |||
| on: | |||
| push: | |||
| branches: [ main ] | |||
| pull_request: | |||
| branches: [ main ] | |||
| jobs: | |||
| job: | |||
| # TODO(dominic): Extend this to include compiler and set through env: CC/CXX. | |||
| name: ${{ matrix.os }}.${{ matrix.build_type }} | |||
| runs-on: ${{ matrix.os }} | |||
| strategy: | |||
| fail-fast: false | |||
| matrix: | |||
| os: [ubuntu-22.04, ubuntu-20.04] | |||
| build_type: ['Release', 'Debug'] | |||
| steps: | |||
| - uses: actions/checkout@v3 | |||
| - name: install libpfm | |||
| run: | | |||
| sudo apt update | |||
| sudo apt -y install libpfm4-dev | |||
| - name: create build environment | |||
| run: cmake -E make_directory ${{ runner.workspace }}/_build | |||
| - name: configure cmake | |||
| shell: bash | |||
| working-directory: ${{ runner.workspace }}/_build | |||
| run: > | |||
| cmake $GITHUB_WORKSPACE | |||
| -DBENCHMARK_ENABLE_LIBPFM=1 | |||
| -DBENCHMARK_DOWNLOAD_DEPENDENCIES=ON | |||
| -DCMAKE_BUILD_TYPE=${{ matrix.build_type }} | |||
| - name: build | |||
| shell: bash | |||
| working-directory: ${{ runner.workspace }}/_build | |||
| run: cmake --build . --config ${{ matrix.build_type }} | |||
| # Skip testing, for now. It seems perf_event_open does not succeed on the | |||
| # hosting machine, very likely a permissions issue. | |||
| # TODO(mtrofin): Enable test. | |||
| # - name: test | |||
| # shell: bash | |||
| # working-directory: ${{ runner.workspace }}/_build | |||
| # run: ctest -C ${{ matrix.build_type }} --rerun-failed --output-on-failure | |||
+ 0
- 114
third_party/benchmark/.github/workflows/build-and-test.yml
View File
| @ -1,114 +0,0 @@ | |||
| name: build-and-test | |||
| on: | |||
| push: | |||
| branches: [ main ] | |||
| pull_request: | |||
| branches: [ main ] | |||
| jobs: | |||
| # TODO: add 32-bit builds (g++ and clang++) for ubuntu | |||
| # (requires g++-multilib and libc6:i386) | |||
| # TODO: add coverage build (requires lcov) | |||
| # TODO: add clang + libc++ builds for ubuntu | |||
| job: | |||
| name: ${{ matrix.os }}.${{ matrix.build_type }}.${{ matrix.lib }}.${{ matrix.compiler }} | |||
| runs-on: ${{ matrix.os }} | |||
| strategy: | |||
| fail-fast: false | |||
| matrix: | |||
| os: [ubuntu-22.04, ubuntu-20.04, macos-latest] | |||
| build_type: ['Release', 'Debug'] | |||
| compiler: ['g++', 'clang++'] | |||
| lib: ['shared', 'static'] | |||
| steps: | |||
| - uses: actions/checkout@v3 | |||
| - uses: lukka/get-cmake@latest | |||
| - name: create build environment | |||
| run: cmake -E make_directory ${{ runner.workspace }}/_build | |||
| - name: setup cmake initial cache | |||
| run: touch compiler-cache.cmake | |||
| - name: configure cmake | |||
| env: | |||
| CXX: ${{ matrix.compiler }} | |||
| shell: bash | |||
| working-directory: ${{ runner.workspace }}/_build | |||
| run: > | |||
| cmake -C ${{ github.workspace }}/compiler-cache.cmake | |||
| $GITHUB_WORKSPACE | |||
| -DBENCHMARK_DOWNLOAD_DEPENDENCIES=ON | |||
| -DBUILD_SHARED_LIBS=${{ matrix.lib == 'shared' }} | |||
| -DCMAKE_BUILD_TYPE=${{ matrix.build_type }} | |||
| -DCMAKE_CXX_COMPILER=${{ env.CXX }} | |||
| -DCMAKE_CXX_VISIBILITY_PRESET=hidden | |||
| -DCMAKE_VISIBILITY_INLINES_HIDDEN=ON | |||
| - name: build | |||
| shell: bash | |||
| working-directory: ${{ runner.workspace }}/_build | |||
| run: cmake --build . --config ${{ matrix.build_type }} | |||
| - name: test | |||
| shell: bash | |||
| working-directory: ${{ runner.workspace }}/_build | |||
| run: ctest -C ${{ matrix.build_type }} -VV | |||
| msvc: | |||
| name: ${{ matrix.os }}.${{ matrix.build_type }}.${{ matrix.lib }}.${{ matrix.msvc }} | |||
| runs-on: ${{ matrix.os }} | |||
| defaults: | |||
| run: | |||
| shell: powershell | |||
| strategy: | |||
| fail-fast: false | |||
| matrix: | |||
| msvc: | |||
| - VS-16-2019 | |||
| - VS-17-2022 | |||
| arch: | |||
| - x64 | |||
| build_type: | |||
| - Debug | |||
| - Release | |||
| lib: | |||
| - shared | |||
| - static | |||
| include: | |||
| - msvc: VS-16-2019 | |||
| os: windows-2019 | |||
| generator: 'Visual Studio 16 2019' | |||
| - msvc: VS-17-2022 | |||
| os: windows-2022 | |||
| generator: 'Visual Studio 17 2022' | |||
| steps: | |||
| - uses: actions/checkout@v2 | |||
| - uses: lukka/get-cmake@latest | |||
| - name: configure cmake | |||
| run: > | |||
| cmake -S . -B _build/ | |||
| -A ${{ matrix.arch }} | |||
| -G "${{ matrix.generator }}" | |||
| -DBENCHMARK_DOWNLOAD_DEPENDENCIES=ON | |||
| -DBUILD_SHARED_LIBS=${{ matrix.lib == 'shared' }} | |||
| - name: build | |||
| run: cmake --build _build/ --config ${{ matrix.build_type }} | |||
| - name: setup test environment | |||
| # Make sure gmock and benchmark DLLs can be found | |||
| run: > | |||
| echo "$((Get-Item .).FullName)/_build/bin/${{ matrix.build_type }}" | Out-File -FilePath $env:GITHUB_PATH -Encoding utf8 -Append; | |||
| echo "$((Get-Item .).FullName)/_build/src/${{ matrix.build_type }}" | Out-File -FilePath $env:GITHUB_PATH -Encoding utf8 -Append; | |||
| - name: test | |||
| run: ctest --test-dir _build/ -C ${{ matrix.build_type }} -VV | |||
+ 0
- 17
third_party/benchmark/.github/workflows/clang-format-lint.yml
View File
| @ -1,17 +0,0 @@ | |||
| name: clang-format-lint | |||
| on: | |||
| push: {} | |||
| pull_request: {} | |||
| jobs: | |||
| build: | |||
| runs-on: ubuntu-latest | |||
| steps: | |||
| - uses: actions/checkout@v3 | |||
| - uses: DoozyX/clang-format-lint-action@v0.13 | |||
| with: | |||
| source: './include/benchmark ./src ./test' | |||
| extensions: 'h,cc' | |||
| clangFormatVersion: 12 | |||
| style: Google | |||
+ 0
- 38
third_party/benchmark/.github/workflows/clang-tidy.yml
View File
| @ -1,38 +0,0 @@ | |||
| name: clang-tidy | |||
| on: | |||
| push: {} | |||
| pull_request: {} | |||
| jobs: | |||
| job: | |||
| name: run-clang-tidy | |||
| runs-on: ubuntu-latest | |||
| strategy: | |||
| fail-fast: false | |||
| steps: | |||
| - uses: actions/checkout@v3 | |||
| - name: install clang-tidy | |||
| run: sudo apt update && sudo apt -y install clang-tidy | |||
| - name: create build environment | |||
| run: cmake -E make_directory ${{ runner.workspace }}/_build | |||
| - name: configure cmake | |||
| shell: bash | |||
| working-directory: ${{ runner.workspace }}/_build | |||
| run: > | |||
| cmake $GITHUB_WORKSPACE | |||
| -DBENCHMARK_ENABLE_ASSEMBLY_TESTS=OFF | |||
| -DBENCHMARK_ENABLE_LIBPFM=OFF | |||
| -DBENCHMARK_DOWNLOAD_DEPENDENCIES=ON | |||
| -DCMAKE_C_COMPILER=clang | |||
| -DCMAKE_CXX_COMPILER=clang++ | |||
| -DCMAKE_EXPORT_COMPILE_COMMANDS=ON | |||
| -DGTEST_COMPILE_COMMANDS=OFF | |||
| - name: run | |||
| shell: bash | |||
| working-directory: ${{ runner.workspace }}/_build | |||
| run: run-clang-tidy | |||