
21 KiB
代码设计文档vO.o
一、项目概述
1.1 项目背景
LevelDB 是一个高性能的嵌入式键值存储引擎,广泛应用于需要快速读写访问的系统中。然而,LevelDB 的基本设计是面向简单的键值对存储,不支持复杂的字段查询、二级索引等高级功能。随着数据量的增长和查询需求的复杂化,直接基于 LevelDB 进行扩展和优化变得尤为重要。
1.2 项目目标
本项目旨在通过三个实验,对 LevelDB 进行功能扩展和性能优化,以满足更复杂的存储和查询需求。具体目标包括:
(1) 实验一:在 LevelDB 的 Value 中实现字段功能
- 扩展 LevelDB 的 value 结构,使其能够包含多个字段,支持类似数据库列查询的功能。
- 实现字段的存储、解析和基于字段值的查询功能。
(2) 实验二:实现 KV 分离
- KV 分离:将 LevelDB 的键和值存储在不同的存储区域,优化写性能和点查询性能。
- 二级索引:在指定字段上创建二级索引,提高字段查询的效率。
(3) 实验三:实现 Benchmark,测试并分析性能
- 设计并实现 Benchmark 程序,测试不同操作(读写、扫描、字段查询)的性能。
- 提供吞吐量、延迟和写放大等性能指标,分析优化在不同场景下的性能表现。
1.3 实现内容
(1) 实验一:在 LevelDB 的 Value 中实现字段功能
- 字段存储:将 LevelDB 的 value 组织成字段数组,每个数组元素对应一个字段(字段名:字段值),并序列化为字符串存储。
- 查询功能:实现通过字段值查询对应的 key 的功能,即 FindKeysByField 函数。
(2) 实验二:实现 KV 分离
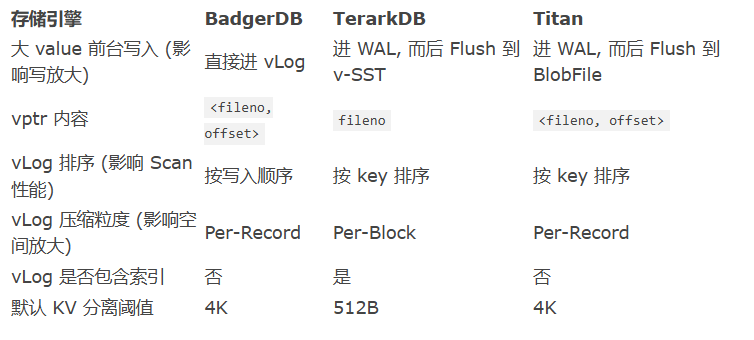
- 设计并实现将键和值存储在不同的存储区域,键存储在 LevelDB 实例中,值存储在一个 Value log 中。
- 实现读取操作,支持点查询和范围查询。
- 管理 Value log,包括后台 GC 操作释放无效数据、新旧 Value log 的管理等。
(3) 实验三:实现 Benchmark,测试并分析性能
- 设计并实现 Benchmark 程序,支持读写操作、扫描操作、字段查询等多种性能测试。
- 提供吞吐量、延迟和写放大等性能指标,通过修改参数实现不同测试场景下的性能测试。
- 分析并报告实现的优化在哪些场景下的性能表现较好,以及带来的代价。
1.4 应用场景或目的
- 实验一:适用于需要存储复杂数据结构并进行字段查询的系统,如日志系统、监控系统等。
- 实验二:
- KV 分离:适用于写操作频繁且对写性能要求较高的系统,如实时分析系统、大数据处理系统等。
- 二级索引:适用于需要高效字段查询的系统,如用户管理系统、数据分析系统等。
- 实验三:通过性能测试和分析,为系统优化提供数据支持,帮助开发者了解不同优化策略在不同场景下的效果,从而做出更合理的决策。
二、功能设计
2.1. 字段设计
设计目标:
- 提供一个key能对应多个字段作为value,且只用作为一个条目存储的功能
- 为了保证自由度,字段数目和字段名都可以由用户决定
- 增强数据库查询灵活性,可以通过value中的字段值来查询key
实现思路:
为了保证可变的字段数目和字段名,除了使用leveldb中提供的变长整数编码外,我们还提出了两种新的方法,但它们存在各自的局限性。
(1) 用特殊符号分隔开每个字段名和字段值

如将 fields{{"name", "Customer#000000001"},{"address", "IVhzIApeRb"}, {"phone", "25-989-741-2988"}} 转化为字符串 "nameCustomer#000000001addressIVhzIApeRbphone*25-989-741-2988"
局限性:如何选择特殊符号才能保证字段名和字段值中不包含特殊符号
(2) 用偏移量标识

如将 fields{{"name", "Customer#000000001"},{"address", "IVhzIApeRb"}, {"phone", "25-989-741-2988"}} 转化为字符串 "22name0address18phone28Customer#000000001IVhzIApeRb25-989-741-2988"
局限性:字段名如果包含数字可能会导致解析错误
(3) 记录字段个数、字段名和字段值的长度
这种方法依赖于特殊的编码方式Varint32/Varint64,在获得解码后的属性长度后可以直接获得属性值,节省空间且简洁高效,能够较好的进行数据压缩,但在大值处理上可能存在某些局限。具体结构见本文档3.1部分。
2.2. KV分离
设计目标:
- 优化LevelDB的写放大问题
- 提高数据库查询效率,通过键值对的方式快速定位所需数据。
- 优化数据存储结构,减少不必要的数据冗余和重复。
KV 分离的好处
- compact 不需要重写 value,大大减少了无效 IO。
- LSM-Tree 不存储 value,体积更小,一个 SST 文件能存更多的 key,有利于减少读 LSM-Tree 的 I/O。
- LSM-Tree 的体积小,操作系统的文件缓存效果会更好。LSM-Tree 基本都可以 cache 在内存中。
实现思路:
在 WiscKey (FAST ‘16) 中,作者提出了一种对 SSD 友好的基于 LSM 树的存储引擎设计。它通过 KV 分离降低了 LSM 树的写放大。 KV 分离就是将大 value 存放在其他地方,并在 LSM 树中存放一个 value pointer (vptr) 指向 value 所在的位置。在 WiscKey 中,这个存放 value 的地方被称为 Value Log (vLog)。由此,LSM 树 compaction 时就不需要重写 value,仅需重新组织 key 的索引。这样一来,就能大大减少写放大,减缓 SSD 的磨损。

KV 分离后存在的问题
- 当 value 较小时,重写 value 这部分的开销就比较小,KV 分离存储带来的好处就不足以抵消它带来开销。
- 如何对删除 value 中的垃圾数据
- 怎么分key和value?需要在“根据 key 迅速定位到 value 的位置”和“降低写放大性能”中trade-off。
- 新生成的valueLog要怎么进行合并?
方案设计

key 和 value 分离的时机是在内存数据 flush 到磁盘的时候。
- 当 value 小于分离阈值时,将 key 和 value 都存储在 SST 文件中;
- 当 value 大于分离阈值时,将 key 和 value 索引存储在 SST 文件中,value 存储在 blob 文件中。
BlobFile 中包含了按key顺序的有序存储的 KV 对,KV 对按单个记录压缩。因此,在 Flush 的过程中,大 value 在 LSM 树中的存储形式为 <key, <fileno, offset>>。
如何删除 blob 文件中的垃圾数据
我们知道 compaction 会删除 SST 文件中的垃圾数据,但并不会删除 blob 中真正的 value,那我们如何删除 blob 文件中的垃圾数据呢,这就要引入 blob 文件的 GC 机制。blob 文件的 GC 要解决两个问题:
- 何时进行 GC?
- 挑选哪些文件进行 GC?
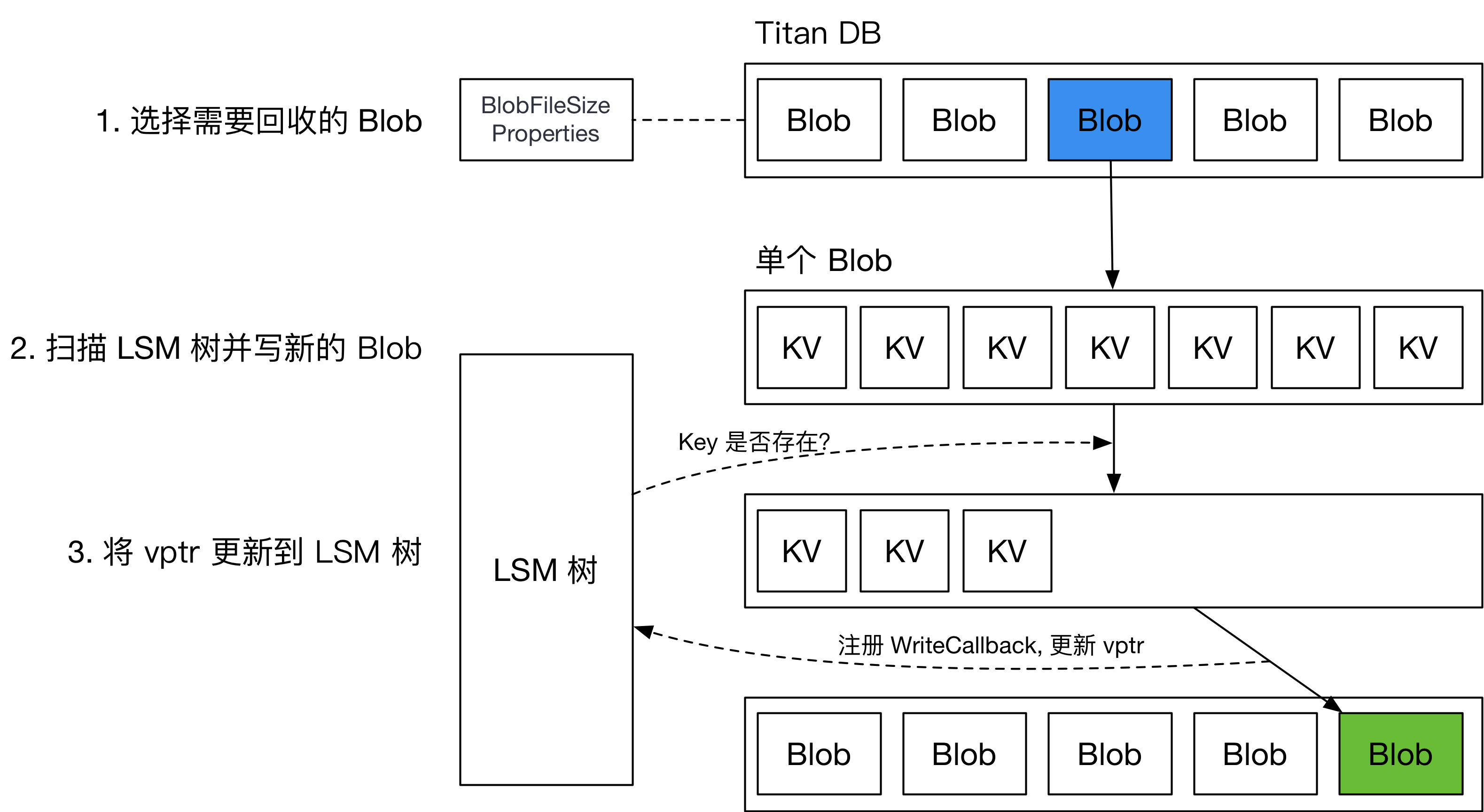
- 合并就能保证所有垃圾数据就被删除掉了吗? -- 首先看第一个问题,何时 GC ? LevelDB是通过Compact来丢弃旧版本数据以回收空间的,因此每次Compact完成后,某些Blob文件中便可能有部分或全部数据过期,因此可以在每次Compact结束后进行GC。 -- 挑选哪些文件进行GC? 垃圾数据最多的文件进行GC。
那么问题又来了,如何判断文件的垃圾数据大小?
RocksDB 允许用户使用自定义的TablePropertiesCollector(文件信息搜集器)来搜集 SST 文件上的用户所关心的数据。我们可以通过这个特性来搜集 SST 文件上的 Blob 文件信息。如下图:
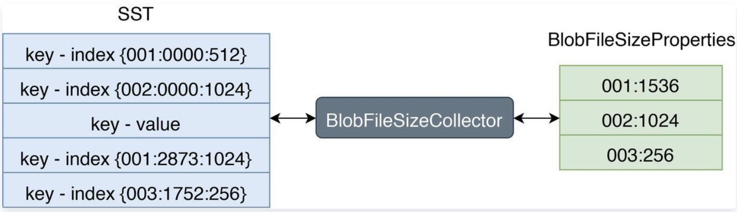
左边 SST 中 Index 的格式为: 第一列代表 BlobFile 的文件 ID,第二列代表 blob record 在 BlobFile 中的 offset,第三列代表 blob record 的 size。
右边 BlobFileSizeProperties 中的每一行代表一个 BlobFile 以及 SST 中有多少数据保存在这个 BlobFile 中,第一列代表 BlobFile 的文件 ID,第二列代表数据大小。
每次 compact 都会记录输入文件和输出文件

- inputs 代表参与 Compaction 的所有 SST 的 BlobFileSizeProperties,
- outputs 代表 Compaction 生成的所有 SST 的 BlobFileSizeProperties,
- discardable size 是通过计算 inputs 和 outputs 得出的每个 BlobFile 被丢弃的数据大小,第一列代表 BlobFile 的文件 ID,第二列代表被丢弃的数据大小。 LevelDB有没有类似的?--好像没有 这样,我们就可以计算出每个 blob 文件的垃圾数据大小,然后排序,优先 GC 垃圾数据最多的 blob 文件。
KV 分离存储除了 GC 的问题,还有很多问题需要解决,如 blob 文件的多版本并发访问、服务重启后如何重新计算 blob 文件的垃圾数据量等。
可能存在的问题
- GC 速度自动调节
- Blob 文件存储优化
- blob 文件的多版本并发访问
- 服务重启后如何重新计算 blob 文件的垃圾数据量
写流程对比:
读流程对比:

三、数据结构设计
3.1 字段数据结构
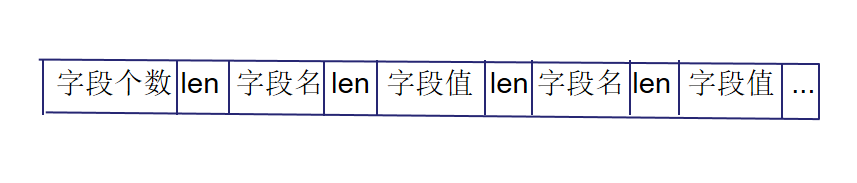
将字段个数、每个字段名与字段值的长度都作为无符号32位整数进行变长编码(Varint32),与字段名、字段值按顺序排列在一起作为value。
借助函数PutLengthPrefixedSlice(),该函数对参数字符串的长度进行编码,同时将编码后的长度和字符串追加到目标字符串中,从而形成value。

3.2 KV分离
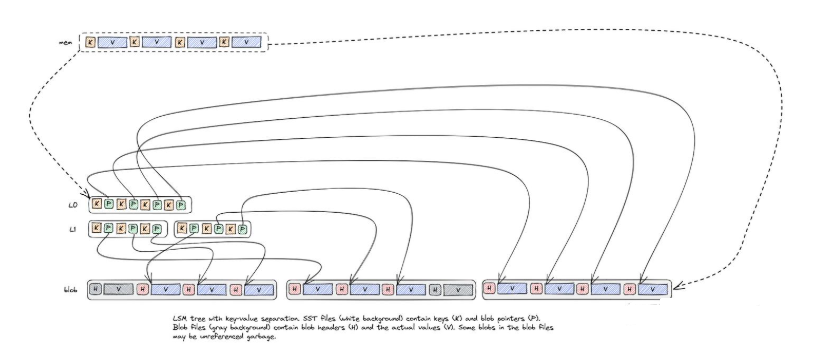

如上所述,结合示意图,我们可以看到blob file在一开始的时候(memtable flush成SST的时候)跟SST是一一映射的。在后续的SST compaction的时候,blob file有两种选择:
- 保持不变,这样SST compaction的时候value不需要重写,降低了写放大,但是会导致空间放大。
- 开启blob file的compaction,将compaction期间需要keep的key的value读取出来重新写入到一个新的Blob file中,同时compaction产生的SST会使用这个新的blob file中的value-index。这样old blob file就可以异步物理删除了(简化讨论,暂时先不讨论blob file被引用的情况)
3.3 GC的实现
在用户删除或更新 key 后,常见 LSM 引擎会在 compaction 过程中把旧的记录删除,如下图所示:如果在做 compaction 时,发现上下层有相同的 key,或者上层有 delete tombstone,引擎则会将下层的 key 删除,在新生成的 SST 中只保留一份 KV。

将大 value 分离出 LSM 树后,我们需要处理大 value 的垃圾回收,减少盘上存在的垃圾数据,减少 KV 分离导致的空间放大。
普通垃圾回收 (Regular GC) ,用统计信息确定要回收的 BlobFile,而后重写对应的 BlobFile,将新的 vptr 写回 LSM 树。整个流程如下图所示。
为了解决这一问题,引入了一种新的 GC 方案,名为“Level Merge”,如下图所示,在 LSM 树做 compaction 的过程中,将对应的 BlobFile 重写,并顺便更新 SST 中的 vptr。由此减少了对前台用户写入的影响。

Level Merge 仅在 LSM 树的最后两层启用。
具体的数据结构可能需要等BlobFile落实才能进一步设计。
BlobDB的GC具体设计:
- 在compaction过程中,迭代器 处理 类型 kTypeBlobIndex 的key时会进入到GarbageCollectBlobIfNeeded,因为分离存储的时候LSM-Tree中存放的value 是key-index,即这个value能够索引的到blob file的一个index。
- 确认当前blob能够参与GC 且 当前key需要被保留,则根据key-index 读取到blob_value 并直接写入到新的blob-file中。并且将新的blob-index 作为当前key的value,提取出来。
- key 和 新的key-index 继续参与compaction后续的落盘行为,形成新的SST。
重点是第二步,也就是想要GC的话会在compaction过程中直接将过期的blob-value直接回收,compaction完成之后 LSM-Tree的sst 以及 blob都会被更新到,只需要维护后续的旧的blob回收即可。
BlobDB通过参数blob_garbage_collection_age_cutoff来判定哪些old blob file需要被回收,例如,默认值 0.25 向 RocksDB 发出信号,表明 GC 应该重新定位最旧 25% 的 Blob 文件中的 Blob。可以调整该参数来调整写入放大和空间放大之间的权衡。
也就是说blob file的物理删除是异步进行,根据blob_garbage_collection_age_cutoff来决定哪些blob file足够老,可以被删除。
四、接口/函数设计
描述实现功能要新增的函数及其功能说明。例如Value log的GC,二级索引的建立、查询、删除等操作。
4.1 字段分离
(1) std::string SerializeValue(const FieldArray& fields)
用于将字段数组序列化为字符串。实现方法:
std::string SerializeValue(const FieldArray& fields)
{
定义空字符串dst;
获取字段数组的长度size;
将size编码为Varint32并加入dst;
遍历fields中的field_name, field_value
{
将field_name编码为Varint32并加入dst;
将field_value编码为Varint32并加入dst;
}
返回dst;
}
(2) FieldArray ParseValue(const std::string& value_str)
用于将字符串反序列化为字段数组,主要借助函数GetLengthPrefixedSlice解码字符串前缀的变长整数同时移除相应长度的字符串。实现方法:
FieldArray ParseValue(const std::string& value_str)
{
定义空的FieldArray fields;
解码得到字段数组的长度size;
循环size次
{
解码得到字段名;
解码得到字段值;
将字段名和字段值组成pair加入到fields中;
}
返回fields;
}
(3) std::vectorstd::string FindKeysByField(leveldb::DB* db, Field &field)
用于通过指定的字段名和字段值查找key。实现方法:
std::vector<std::string> FindKeysByField(leveldb::DB* db, Field &field)
{
新建一个std::vector<std::string> ret存储找到的key;
新建一个DBIter it;
it指向数据库中第一个key;
while it 有效
{
取出it对应的value;
对value进行解析,获得字段数组fields;
遍历fields
{
如果字段名等于field的字段名且字段值等于field的字段值
{
将it的key加入ret中;
}
}
}
返回ret;
}
4.2 ValueLog-BlobFile
kv分离相关配置参数,均支持动态调节。
enable_blob_files: 是否开启KV分离。
min_blob_size: KV分离阈值,大于等于该阈值的value在Flush/Compaction时写到Blob文件。
blob_file_size: Blob文件大小。
blob_compression_type: blob文件压缩算法,每个blobfile使用相同的压缩算法。
enable_blob_garbage_collection: 设置该值之后,引擎会在compaction时重写遇到的位于
最老的一批Blob文件中的value到新的Blob文件。
blob_garbage_collection_age_cutoff: 定义旧的Blob文件的阈值,默认为0.25,
表示所有Blob文件中最先生成的25% Blob文件即为旧的Blob文件。
blob_garbage_collection_force_threshold: 引擎主动GC的一个阈值。除了在compaction过程中
重写老的blob value以外,引擎还支持主动发起GC。当最旧的一批blob文件garbage所占比值>=该值,
会触发一次compaction清理blob文件。
blob_compaction_readahead_size: 从blob文件中预读数据大小。如果设置了该值,会在compaction
中预读blob文件,预读大小为blob_compaction_readahead_size。
4.3 写

4.4 读
仿照写过程,实际可能有别的问题。
五、功能测试
5.1 单元测试(测试用例):
字段插入:
插入含有字段的key value对,然后直接使用原本的Get函数获取该key对应的value,验证是否正确执行插入操作。
TEST(TestSchema, Insert) {
std::string key = "k_1";
FieldArray fields = {
{"name", "Customer#000000001"},
{"address", "IVhzIApeRb"},
{"phone", "25-989-741-2988"}
};
// 序列化并插入
std::string value = SerializeValue(fields);
db->Put(WriteOptions(), key, value);
// 读取并反序列化
std::string value_ret;
db->Get(ReadOptions(), key, &value_ret);
auto fields_ret = ParseValue(value_ret);
}
通过字段反向查询key:
插入多个含有字段的key value对,然后通过value中的某一字段查询匹配的key值,验证反向查询功能。
TEST(TestSchema, Find) {
std::vector<std::string> keys = {"s_1", "s_2", "s_3", "s_4"};
// 构造一组字段数组
std::vector<FieldArray> FieldArrays = {
{
{"name", "Sarah"},{"sex", "f"},{"age", "20"}
},
{
{"name", "Mike"},{"sex", "m"},{"age", "19"},{"hobby", "badminton"}
},
{
{ name", "Amy"},{"sex", "f"},{"age", "21"},{"talent", "sing"}
},
{
{ name", "John"}, {"sex", "m"},{"age", "20"}
}
};
// 序列化并插入
for (int i=0; i<FieldArrays.length(); i++)
{
key = keys[i];
fields = FieldArrays[i];
std::string value = SerializeValue(fields);
db->Put(WriteOptions(), key, value);
}
// 构建目标字段
Field field = {"sex", "f"};
std::vector<std::string> key_ret;
// 查询得到对应的key
key_ret = FindKeysByField(leveldb::DB* db, Field &field)
}
5.2 性能测试(Benchmark):
(1) 分别测试写操作、读操作、扫描操作和字段查询的吞吐、延迟、写放大指标。
(2) 测试KV分离对于性能的影响:
a. KV分离对读写性能的提升
b. KV分离对范围查询性能的影响
c. 后台GC的开销有多大,对性能的影响
i. GC的持续时间。
ii. GC过程中对读写性能的影响。
iii. GC在磁盘上产生的写放大开销。
六、可能遇到的挑战与解决方案
未来优化工作
• GC 速度自动调节 • Blob 文件存储优化 • blob 文件的多版本并发访问 • 服务重启后如何重新计算 blob 文件的垃圾数据量
七、分工和进度安排
| 功能 | 完成日期 | 分工 |
|---|---|---|
| 讨论并敲定KV分离的实现方式,产出初版设计文档 | 11.25 | 曹可心 & 朴祉燕 |
| 初步实现Value的字段功能 | 11.26 | 曹可心 |
| 对字段的正确性进行测试 | 11.28 | 朴祉燕 |
| 实现ValueLog的组织结构 | 11.28-11.31 | 朴祉燕 |
| 实现ValueLog的写功能 | 11.31-12.07 | 曹可心 |
| 实现垃圾回收的功能 | 11.31-12.07 | 朴祉燕 |
| 实现ValueLog的读功能 | 12.07-12.12 | 曹可心 |
| 实现ValueLog的删除功能 | 12.07-12.12 | 朴祉燕 |
| 对kv分离的性能进行测试 | 12.12-12.14 | 曹可心 |
| 对垃圾回收策略的性能进行测试 | 12.12-12.14 | 朴祉燕 |
| 根据性能测试结果进行优化 | 12.14- | 曹可心 & 朴祉燕 |