|
|
|
@ -38,11 +38,13 @@ Andy Pavlo在15445课程中说,完成一个项目,应先写出能够完成 |
|
|
|
|
|
|
|
函数 `Get_with_fields` 负责获得含字段的数据。使用 `Get` 从 leveldb 中获取 `key` 和序列化后的 `value`,调用 `ParseValue` 可以将字段反序列化。 |
|
|
|
|
|
|
|
函数 `Get_keys_by_field` 遍历数据库中的所有键值对,解析每个 `Value`,提取字段数组 `FieldArray`。检查字段数组中是否存在目标字段,如果匹配,则记录其对应的 `Key`。将所有匹配 `key` 汇总到 `keys` 中返回。 |
|
|
|
函数 `Get_keys_by_field` 使用iterator遍历数据库中的所有键值对,解析每个 `Value`,提取字段数组 `FieldArray`。检查字段数组中是否存在目标字段,如果匹配,则记录其对应的 `Key`。将所有匹配 `key` 汇总到 `keys` 中返回。 |
|
|
|
|
|
|
|
**初步实现**(第一周 已完成):在 leveldb 内部实现以上功能。内部实现会导致读取时无法区分多字段类型和原生 kv 对,扩展性不足。 |
|
|
|
|
|
|
|
**后续改进**(第二周):为了解决无法区分多字段类型和原生 kv 对的问题,将以上函数功能实现在用户层级,使 leveldb 内部对多字段类型无感知。 |
|
|
|
**后续改进_1**(第二周 已完成):为了解决无法区分多字段类型和原生 kv 对的问题,将以上函数功能实现在用户层级,使 leveldb 内部对多字段类型无感知。 |
|
|
|
|
|
|
|
**后续改进_2**(第三周 已完成):在完成其余功能过程中,发现leveldb在coding类中有一些编码实现,因此也做了将字段设计放入coding类实现的版本。 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
@ -52,29 +54,33 @@ Andy Pavlo在15445课程中说,完成一个项目,应先写出能够完成 |
|
|
|
|
|
|
|
- **KV 分离设计** |
|
|
|
|
|
|
|
a. 将LevelDB的key-value存储结构进行扩展,分离存储key和value |
|
|
|
a. 将LevelDB的key-value存储结构进行扩展,分离存储key和value。(当Value长度不大时不进行分离) |
|
|
|
|
|
|
|
b. 将Key和指向Value的元数据存储在LSM-tree中。 |
|
|
|
|
|
|
|
b. Key存储在一个LevelDB实例中,LSM-tree中的value为一个指向Value log文件和偏移地址的指针,用户Value存储在Value log中。 |
|
|
|
c.将Value和其余需要额外存储在ValueLog的元数据存储于ValueLog文件。通过LSM-tree中的元数据可查询到对应的Value所处的ValueLog。 |
|
|
|
|
|
|
|
- **读取操作。** |
|
|
|
|
|
|
|
KV分离后依然支持点查询与范围查询操作。 |
|
|
|
|
|
|
|
- **Value log的管理。** |
|
|
|
- **Value log的管理** |
|
|
|
|
|
|
|
a.当Value log超过一定大小后通过后台GC操作释放Value log中的无效数据。 |
|
|
|
a.通过GC操作释放Value log中的无效数据。(对于我们的不同实现版本,GC操作有所不同) |
|
|
|
|
|
|
|
b.GC能把旧Value log中没有失效的数据写入新的Value log,并更新LSM-tree里的键值对。 |
|
|
|
b.GC能把旧Value log中没有失效的数据写入新的Value log,并在有必要时更新LSM-tree。 |
|
|
|
|
|
|
|
c.新旧Value log的管理功能。 |
|
|
|
c.GC过程不能过度阻塞用户的Put和Get操作。(过度阻塞则和原本消耗大量资源的Compaction无区别,没有得到期望的性能提升) |
|
|
|
|
|
|
|
- **确保操作的原子性** |
|
|
|
|
|
|
|
a.Write时先写ValueLog再写WAL,从而保证操作的原子性。 |
|
|
|
|
|
|
|
b.对不同版本的GC实现,均需保证GC操作过程中发生dump后,恢复数据仍能保证正确性。 |
|
|
|
|
|
|
|
#### 实现思路 |
|
|
|
|
|
|
|
#### 初步实现(第一周 已完成) |
|
|
|
#### 初步实现:Single ValueLog(第一周 已完成) |
|
|
|
|
|
|
|
使用单一Value Log简单的实现KV分离,该实现较为简单,仅需在Put/Get函数内部进行简单修改,但在大数据量场景下性能极差。 |
|
|
|
|
|
|
|
@ -84,11 +90,11 @@ Andy Pavlo在15445课程中说,完成一个项目,应先写出能够完成 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
#### 第二种实现(第二周 已完成) |
|
|
|
#### 第二种实现:ValueLog per table(第二周 已完成) |
|
|
|
|
|
|
|
对每个SSTable和MemTable建立一个Value Log。该实现相比于初步实现更加复杂,需要在合并时查询所有相关Value Log,并建立新Value Log。此外还要考虑在合并结束后将废弃的Value Log异步删除。 |
|
|
|
|
|
|
|
**Trick 1.为什么要在Put到MemTable时就放入Value Log而非dump至SS Table时才放入Value Log?** |
|
|
|
**Trick.为什么要在Put到MemTable时就放入Value Log而非dump至SS Table时才放入Value Log?** |
|
|
|
|
|
|
|
原因:将写ValueLog推迟至SSTable并没有减少Put时写入磁盘的总数据量(写ValueLog:ValueLog中写Value,WAl中写Key和Value元数据;不写ValueLog:WAL中写Key和Value),优点是将两次无法并行的写文件操作变为一次写文件操作。但该方法有一个缺陷,即leveldb原生的管理数据的方式是MemTable和SSTable大小相等。而经过这样改变后,MemTable在dump成SSTable后其大小会突然减少(Value全部转移至ValueLog),导致一个SSTable中存储的数据量过少。而原本valuelog的优势(一个SSTable可以放更多键值对使得table cache命中率变高)也将不存在了。我们将两个做法都进行了实现,通过对比性能发现后者不如前者,因此选择保留前者设计。 |
|
|
|
|
|
|
|
@ -96,11 +102,15 @@ Andy Pavlo在15445课程中说,完成一个项目,应先写出能够完成 |
|
|
|
|
|
|
|
##### 缺点:合并时开销未能减小。 |
|
|
|
|
|
|
|
**第三种实现**(第三周):使用相对固定大小的Value Log,例如每个Value Log大小约为2KB。新添加的键值对依次将值计入最新Value Log,当Value Log大小满了之后就创建新Value Log。需要设计一种不改变SSTable内记录Value元数据的GC方法。 |
|
|
|
#### 第三种实现:Fixsize ValueLog(第三周 已完成) |
|
|
|
|
|
|
|
**该实现参考TiTanDB实现** |
|
|
|
|
|
|
|
使用相对固定大小的Value Log,例如每个Value Log大小约为16MB。新添加的键值对依次将值与其长度(其实还有键和键长度)存入最新Value Log,当Value Log大小满了之后就创建新Value Log。需要设计一种异步的GC方法,该方法不会对Compaction,Get或Put造成明显的延迟。 |
|
|
|
|
|
|
|
##### 优点:合并时开销小。 |
|
|
|
|
|
|
|
##### 缺点:需要设计一种GC方式,能够在异步GC的同时不改变SSTable。 |
|
|
|
##### 缺点:需要设计一种优秀的异步GC方式。 |
|
|
|
|
|
|
|
## 3. 数据结构设计 |
|
|
|
|
|
|
|
@ -112,7 +122,7 @@ Andy Pavlo在15445课程中说,完成一个项目,应先写出能够完成 |
|
|
|
|
|
|
|
### ValueLog结构设计 |
|
|
|
|
|
|
|
**第一版设计** |
|
|
|
#### Single ValueLog设计 |
|
|
|
|
|
|
|
使用一个Value Log文件的设计中,我们只需记录Value在Value Log中对应的偏移量和Value长度即可。 |
|
|
|
|
|
|
|
@ -120,7 +130,7 @@ Value Log中只记录Value值,无需记录元信息。 |
|
|
|
|
|
|
|
 |
|
|
|
|
|
|
|
**第二版设计** |
|
|
|
#### ValueLog per table设计 |
|
|
|
|
|
|
|
Value设计为:1字节标志位+Varint64文件ID+Varint64偏移量+Varint64长度。 |
|
|
|
|
|
|
|
@ -130,15 +140,15 @@ Value设计为:1字节标志位+Varint64文件ID+Varint64偏移量+Varint64长 |
|
|
|
|
|
|
|
 |
|
|
|
|
|
|
|
**第三版设计** |
|
|
|
#### Fixsize ValueLog设计(第一版,有漏洞) |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
 |
|
|
|
|
|
|
|
这一版设计有些复杂。 |
|
|
|
这一版设计有些复杂,但存在漏洞。我们的最终设计并非如此。 |
|
|
|
|
|
|
|
和第二版设计一样,在Value开头使用一字节标志位表示是否KV分离。 |
|
|
|
在Value开头使用一字节标志位表示是否KV分离。 |
|
|
|
|
|
|
|
如果KV分离,则接下来是Varint64的文件ID和Varint64的文件内offset。 |
|
|
|
|
|
|
|
@ -190,7 +200,7 @@ Value设计为:1字节标志位+Varint64文件ID+Varint64偏移量+Varint64长 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
### 3.1 fixsize_valuelog实际设计 |
|
|
|
#### fixsize_valuelog实际设计 |
|
|
|
|
|
|
|
 |
|
|
|
|
|
|
|
@ -205,35 +215,45 @@ Value设计为:1字节标志位+Varint64文件ID+Varint64偏移量+Varint64长 |
|
|
|
|
|
|
|
在sstable中key对应的value位置存储了对应valuelog文件的id和在文件中的offset。 |
|
|
|
|
|
|
|
**注1:在valueLog中重复存key会导致写方法,但是是有必要的,详见GC过程** |
|
|
|
|
|
|
|
**注2:将Key放在Value后是一个潜在的优化,可以加速Get** |
|
|
|
|
|
|
|
#### gc过程: |
|
|
|
|
|
|
|
垃圾回收的核心思想是扫描所有的 `valuelog` 文件,检查文件中的记录是否有效。如果记录的键已失效(比如键在 `sstable` 中不存在或元数据不匹配),则该记录会被忽略,最终删除整个无效的 `valuelog` 文件。 |
|
|
|
垃圾回收的核心思想是扫描所有非最新的 `valuelog` 文件(最新的ValueLog还会被插入新的数据,因此不对其进行垃圾回收),检查文件中的记录是否有效。如果记录的键值对已失效(比如键在 `sstable` 中不存在或元数据不匹配),则该记录会被忽略;如果记录的键值对是该键对应最新的键值对,则将该键值对重新Put进MemTable。在对整个旧的`ValueLog`做完上述操作后删除整个旧的的 `valuelog` 文件。 |
|
|
|
|
|
|
|
#### **详细过程:** |
|
|
|
#### 详细过程 |
|
|
|
|
|
|
|
1. **扫描数据库目录**: |
|
|
|
|
|
|
|
- 遍历 `valuelog` 文件。 |
|
|
|
|
|
|
|
- 遍历 `valuelog` 文件。 |
|
|
|
2. **处理每个 `valuelog` 文件**: |
|
|
|
|
|
|
|
- 打开文件,逐条读取记录。 |
|
|
|
|
|
|
|
3. **读取每条记录**: |
|
|
|
|
|
|
|
- 按文件结构读取 `key_len`、`key`、`value_len`、`value`。 |
|
|
|
- 检查 sstable是否包含该键: |
|
|
|
- 如果键不存在(或无效),忽略此条记录。 |
|
|
|
- 如果键存在,验证元数据(包括 `valuelog_id` 和 `offset`)。 |
|
|
|
- 有效的键值对会被重新 put 进入数据库,sstable中重复的key会在compaction过程中被回收。 |
|
|
|
|
|
|
|
- 如果键不存在,忽略此条记录。 |
|
|
|
- 如果键存在,验证元数据是否有效(包括 `valuelog_id` 和 `offset`)。 |
|
|
|
- 有效的键值对会被重新 put 进入数据库(在此操作中自然的被插入到最新的ValueLog中),SSTable中无效的键值对则会在compaction过程中被自然的回收。 |
|
|
|
4. **清理无效文件**: |
|
|
|
- 对ValueLog扫描完毕后,删除该ValueLog。 |
|
|
|
|
|
|
|
#### 验证元数据/重新Put的正确性保证 |
|
|
|
|
|
|
|
在发现当前键值对有效后会将该键值对重新调用Put插入数据库,然而在此过程中如果有用户新插入了对应的Key的键值对,则有概率覆盖用户插入的键值对,这是错误的。因此我们要保证在此过程中不会新插入新的该Key对应的键值对。 |
|
|
|
|
|
|
|
我们使用了三个新的操作来实现该操作: |
|
|
|
|
|
|
|
1.一个新的全局互斥锁GC_mutex |
|
|
|
|
|
|
|
- 如果整个 `valuelog` 文件的记录均无效或已被迁移,删除该文件。 |
|
|
|
2.一个新的全局变量inserting_key,使用GC_mutex管理的conditional variable进行访问保护 |
|
|
|
|
|
|
|
|
|
|
|
3.更改write逻辑,可以访问当前writer队列的末尾write请求,并在其做完时获得其对应的conditional variable的提醒 |
|
|
|
|
|
|
|
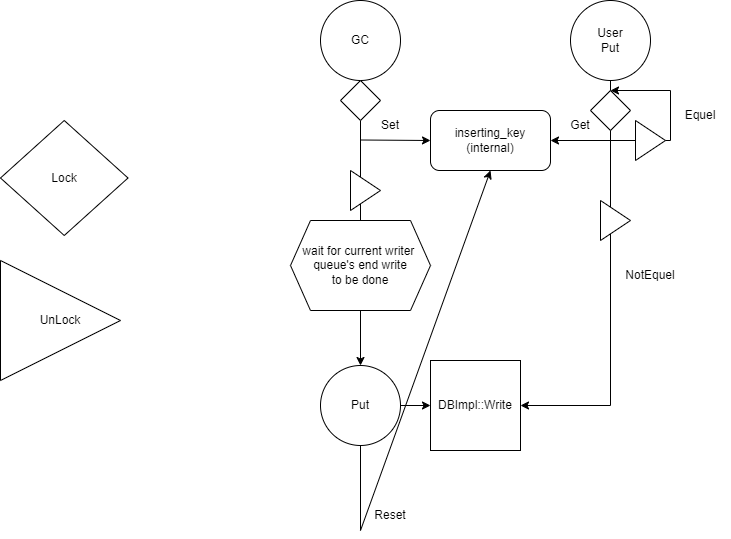
下图是实现整个操作的模拟,左侧是图标,Lock和UnLock都指对GC_mutex的操作 |
|
|
|
|
|
|
|
 |
|
|
|
|
|
|
|
## 4. 接口/函数设计 |
|
|
|
|
|
|
|
@ -286,7 +306,7 @@ Status DB::Get_keys_by_field(const ReadOptions& options, const Field field, std: |
|
|
|
**判断给定文件是否为 `.valuelog` 格式的文件。** |
|
|
|
|
|
|
|
```c++ |
|
|
|
bool IsValueLogFile(const std::string& filename) { |
|
|
|
bool IsValueLogFile(const std::string& filename) ; |
|
|
|
``` |
|
|
|
|
|
|
|
**输入**: |
|
|
|
@ -300,7 +320,7 @@ bool IsValueLogFile(const std::string& filename) { |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
##### **4.1.4 解析 `sstable` 中的元信息** |
|
|
|
##### **4.1.4 解析 `sstable` 中的Value元信息(用于Fixsize ValueLog)** |
|
|
|
|
|
|
|
**解析 `sstable` 中存储的值,提取 `valuelog_id` 和 `offset` 信息。** |
|
|
|
|
|
|
|
@ -335,9 +355,9 @@ uint64_t GetValueLogID(const std::string& valuelog_name); |
|
|
|
|
|
|
|
##### **4.2.1 WriteValueLog** |
|
|
|
|
|
|
|
将一堆键值对的值顺序写入Value Log,用于writebatch写入数据库,以及Value Log GC的时候。两者都会对多个键值对同时操作,因此设计为批处理。 |
|
|
|
将一堆键值对的值顺序写入Value Log,用于writebatch写入数据库,以及Value Log GC的时候(valuelog per table)。两者都会对多个键值对同时操作,因此设计为批处理。 |
|
|
|
|
|
|
|
函数内将使用写锁保证正确性。同一时间最多只有一个WriteValueLog可以进行。 |
|
|
|
该函数被mutex_保护,保证不会多线程调用。 |
|
|
|
|
|
|
|
```cpp |
|
|
|
std::vector<std::pair<uint64_t,uint64_t>> WriteValueLog(std::vector<const slice&> value); |
|
|
|
@ -349,7 +369,7 @@ std::vector> WriteValueLog(std::vector |
|
|
|
|
|
|
|
> [!NOTE] |
|
|
|
> |
|
|
|
> 在第三版设计中,valuelog中会存储key,所以有部分改动。 |
|
|
|
> 在第三版设计中,valuelog中会存储key,所以还需要传入key |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
@ -357,8 +377,6 @@ std::vector> WriteValueLog(std::vector |
|
|
|
|
|
|
|
通过Value Log读取目标键值对的值。 |
|
|
|
|
|
|
|
函数内将使用读锁保证正确性。在一个ValueLog正在被读取时,GC和WriteValueLog(?)无法对该ValueLog操作。 |
|
|
|
|
|
|
|
```cpp |
|
|
|
Status ReadValueLog(uint64_t file_id, uint64_t offset,Slice* value); |
|
|
|
``` |
|
|
|
@ -368,9 +386,7 @@ Status ReadValueLog(uint64_t file_id, uint64_t offset,Slice* value); |
|
|
|
|
|
|
|
> [!NOTE] |
|
|
|
> |
|
|
|
> 在第三版设计中,valuelog中会存储key,所以有部分改动。 |
|
|
|
|
|
|
|
|
|
|
|
> 在第三版设计中,valuelog中会存储key,所以还会多一个返回参数Key |
|
|
|
|
|
|
|
##### **4.2.3 测试GC** |
|
|
|
|
|
|
|
@ -384,7 +400,7 @@ void DBImpl::TEST_GarbageCollect() |
|
|
|
|
|
|
|
##### **4.2.4 调用线程进行GC** |
|
|
|
|
|
|
|
启动一个新的后台线程执行`BGWorkGC`方法。这里使用了`gc_mutex_.Lock()`来确保线程安全。 |
|
|
|
启动一个新的后台线程执行`BGWorkGC`方法。使用互斥锁gc_mutex_确保同时最多只有一个GC后台线程会进行。 |
|
|
|
|
|
|
|
```cpp |
|
|
|
void DBImpl::MaybeScheduleGarbageCollect() |
|
|
|
@ -404,7 +420,9 @@ void DBImpl::BGWorkGC(void* db) |
|
|
|
|
|
|
|
##### **4.2.6 后台GC函数** |
|
|
|
|
|
|
|
负责执行后台垃圾回收任务。它确保在进行垃圾回收时,只有一个线程能够访问共享资源,并且在完成任务后通知等待的线程。 |
|
|
|
负责执行后台垃圾回收任务(即调用GarbageCollect)。确保在完成任务后通知等待的线程。 |
|
|
|
|
|
|
|
(当前等待的函数仅两个:Test与DBImpl的析构函数) |
|
|
|
|
|
|
|
```cpp |
|
|
|
void DBImpl::BackgroundGarbageCollect() |
|
|
|
@ -422,6 +440,28 @@ void DBImpl::GarbageCollect() |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
##### 4.2.8 改动TableMeta(用于valuelog per table) |
|
|
|
|
|
|
|
对TableMeta新增一个uint64_t的属性valuelog_id,表示该SSTable所对应的valuelog id。如果该SSTable内所有Value长度均小于ValueLog要求长度,则该属性值为0。 |
|
|
|
|
|
|
|
这个设计对versionEdit以及compact的各个函数均有影响。 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
##### 4.2.9 class ValueLogInserter : public WriteBatch::Handler{} |
|
|
|
|
|
|
|
用于将一个WriteBatch里的所有键值对插入到ValueLog里,并生成将Value指向ValueLog的新WriteBatch。 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
##### 4.2.10 Status WriteBatchInternal::ConverToValueLog(WriteBatch* b,DB* db_) |
|
|
|
|
|
|
|
使用ValueLogInserter将b中的键值对更新至ValueLog,并将更新后的WriteBatch放回b。 |
|
|
|
|
|
|
|
该函数用于Write中的队首线程build batch后且写WAL日志/写Memtable前。 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
------ |
|
|
|
|
|
|
|
|
|
|
|
@ -432,7 +472,7 @@ void DBImpl::GarbageCollect() |
|
|
|
|
|
|
|
#### 依据我们的设计,每周的工作内容完成后,都将对当前完成的功能进行正确性检验。以下以第一周我们完成的功能为例: |
|
|
|
|
|
|
|
#### 第一周 |
|
|
|
#### 第一周(已完成) |
|
|
|
|
|
|
|
**字段数组的存储与读取:** |
|
|
|
|
|
|
|
@ -446,80 +486,95 @@ void DBImpl::GarbageCollect() |
|
|
|
|
|
|
|
并未额外设计,通过上两个功能的正确运行能够证明Key Value分离的初步实现大体是正确的。 |
|
|
|
|
|
|
|
```c++ |
|
|
|
#include "gtest/gtest.h" |
|
|
|
#include "leveldb/env.h" |
|
|
|
#include "leveldb/db.h" |
|
|
|
using namespace leveldb; |
|
|
|
|
|
|
|
constexpr int value_size = 2048; |
|
|
|
constexpr int data_size = 128 << 20; |
|
|
|
|
|
|
|
Status OpenDB(std::string dbName, DB **db) { |
|
|
|
Options options; |
|
|
|
options.create_if_missing = true; |
|
|
|
return DB::Open(options, dbName, db); |
|
|
|
} |
|
|
|
|
|
|
|
TEST(TestTTL, OurTTL) { |
|
|
|
DB *db; |
|
|
|
WriteOptions writeOptions; |
|
|
|
ReadOptions readOptions; |
|
|
|
if(OpenDB("testdb_for_XOY", &db).ok() == false) { |
|
|
|
std::cerr << "open db failed" << std::endl; |
|
|
|
abort(); |
|
|
|
} |
|
|
|
std::string key = "k_1"; |
|
|
|
|
|
|
|
std::string key1 = "k_2"; |
|
|
|
|
|
|
|
FieldArray fields = { |
|
|
|
{"name", "Customer#000000001"}, |
|
|
|
{"address", "IVhzIApeRb"}, |
|
|
|
{"phone", "25-989-741-2988"} |
|
|
|
}; |
|
|
|
|
|
|
|
FieldArray fields1 = { |
|
|
|
{"name", "Customer#000000001"}, |
|
|
|
{"address", "abc"}, |
|
|
|
{"phone", "def"} |
|
|
|
}; |
|
|
|
|
|
|
|
db->Put_with_fields(WriteOptions(), key, fields); |
|
|
|
|
|
|
|
db->Put_with_fields(WriteOptions(), key1, fields1); |
|
|
|
|
|
|
|
// 读取并反序列化 |
|
|
|
FieldArray value_ret; |
|
|
|
db->Get_with_fields(ReadOptions(), key, &value_ret);; |
|
|
|
for(auto pr:value_ret){ |
|
|
|
std::cout<<std::string(pr.first.data(),pr.first.size())<<" "<<std::string(pr.second.data(),pr.second.size())<<"\n"; |
|
|
|
} |
|
|
|
|
|
|
|
std::vector<std::string> v; |
|
|
|
db->Get_keys_by_field(ReadOptions(),fields[0],&v); |
|
|
|
for(auto s:v)std::cout<<s<<"\n"; |
|
|
|
delete db; |
|
|
|
} |
|
|
|
|
|
|
|
#### 第二、三周(已完成) |
|
|
|
|
|
|
|
**对多字段Value实现更严谨的测试** |
|
|
|
|
|
|
|
int main(int argc, char** argv) { |
|
|
|
// All tests currently run with the same read-only file limits. |
|
|
|
testing::InitGoogleTest(&argc, argv); |
|
|
|
return RUN_ALL_TESTS(); |
|
|
|
} |
|
|
|
``` |
|
|
|
针对范围查询进行更严格的测试(因为范围查询难于单点查询),进行了乱序插入后测试范围查询能否查询到分布在lsm-tree各处且key完全随机的目标value。 |
|
|
|
|
|
|
|
#### 进一步设计 |
|
|
|
``` |
|
|
|
std::vector<std::string> keys; |
|
|
|
std::vector<std::string> target_keys; |
|
|
|
for(int i=0;i<10000;i++){ |
|
|
|
std::string key=std::to_string(rand()%10000)+"_"+std::to_string(i);//random for generate nonincreasing keys |
|
|
|
FieldArray fields={ |
|
|
|
{"name", key}, |
|
|
|
{"address", std::to_string(rand()%7)}, |
|
|
|
{"phone", std::to_string(rand()%114514)} |
|
|
|
}; |
|
|
|
if(rand()%5==0){ |
|
|
|
fields[0].second="special_key"; |
|
|
|
target_keys.push_back(key); |
|
|
|
} |
|
|
|
keys.push_back(key); |
|
|
|
db->Put(WriteOptions(),key,SerializeValue(fields)); |
|
|
|
} |
|
|
|
std::sort(target_keys.begin(),target_keys.end()); |
|
|
|
std::vector<std::string> key_res; |
|
|
|
Get_keys_by_field(db,ReadOptions(),{"name", "special_key"},&key_res); |
|
|
|
ASSERT_TRUE(CompareKey(key_res, target_keys)); |
|
|
|
``` |
|
|
|
|
|
|
|
**对KV分离实现更细粒度的测试,以及对KV分离GC操作实现测试** |
|
|
|
2.向表内插入大量value较大的键值对后检验正确性(该测试被leveldb原benchmark完美取代。使用leveldb原benchmark获得了正确性保障) |
|
|
|
|
|
|
|
1.向表内插入一些value较小的键值对以及value较大的键值对,随后通过检查ValueLog内部数据(也可以是ValueLog文件长度)来判断是否对长短数据各自进行了处理。 |
|
|
|
对于for(int j=0;j<5000;j++)这一段,我们也尝试过将5000改成rand()%1000,同样通过了测试。 |
|
|
|
|
|
|
|
2.向表内插入大量value较大的键值对后,查询ValueLog文件总数,删除其中绝大多数键值对,然后再查一次ValueLog文件总数,期望文件总数变少。 |
|
|
|
``` |
|
|
|
std::vector<std::string> values; |
|
|
|
for(int i=0;i<500000;i++){ |
|
|
|
std::string key=std::to_string(i); |
|
|
|
std::string value; |
|
|
|
for(int j=0;j<5000;j++){ |
|
|
|
value+=std::to_string(i); |
|
|
|
} |
|
|
|
values.push_back(value); |
|
|
|
db->Put(writeOptions,key,value); |
|
|
|
} |
|
|
|
for(int i=0;i<500000;i++){ |
|
|
|
std::string key=std::to_string(i); |
|
|
|
std::string value; |
|
|
|
Status s=db->Get(readOptions,key,&value); |
|
|
|
assert(s.ok()); |
|
|
|
if(values[i]!=value){ |
|
|
|
std::cout<<value.size()<<std::endl; |
|
|
|
assert(0); |
|
|
|
} |
|
|
|
ASSERT_TRUE(values[i]==value); |
|
|
|
} |
|
|
|
``` |
|
|
|
|
|
|
|
3.对GC进行正确性检测:在关闭自动GC的情况下,进行一次手动GC,然后查询所有键值对,期望仍能够读到。 |
|
|
|
|
|
|
|
``` |
|
|
|
std::vector<std::string> values; |
|
|
|
for(int i=0;i<5000;i++){ |
|
|
|
std::string key=std::to_string(i); |
|
|
|
std::string value; |
|
|
|
for(int j=0;j<1000;j++){ |
|
|
|
value+=std::to_string(i); |
|
|
|
} |
|
|
|
values.push_back(value); |
|
|
|
db->Put(writeOptions,key,value); |
|
|
|
} |
|
|
|
std::cout<<"start gc"<<std::endl; |
|
|
|
db->TEST_GarbageCollect(); |
|
|
|
std::cout<<"finish gc"<<std::endl; |
|
|
|
|
|
|
|
for(int i=0;i<5000;i++){ |
|
|
|
// std::cout<<i<<std::endl; |
|
|
|
std::string key=std::to_string(i); |
|
|
|
std::string value; |
|
|
|
Status s=db->Get(readOptions,key,&value); |
|
|
|
assert(s.ok()); |
|
|
|
if(values[i]!=value){ |
|
|
|
std::cout<<value.size()<<std::endl; |
|
|
|
assert(0); |
|
|
|
} |
|
|
|
ASSERT_TRUE(values[i]==value); |
|
|
|
} |
|
|
|
``` |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
@ -527,15 +582,9 @@ int main(int argc, char** argv) { |
|
|
|
|
|
|
|
这一部分我们希望在完成大部分功能后再根据代码调整。 |
|
|
|
|
|
|
|
初步计划: |
|
|
|
|
|
|
|
1.测试大数据量下短键值对和长键值对分别的插入和查询效率,与原版LevelDB作对比。 |
|
|
|
|
|
|
|
2.测试大数据量下磁盘使用率,与原版LevelDB作对比。 |
|
|
|
在第三周我们在服务器上运行了leveldb原生代码、version_2以及version_3,得到以下结果。 |
|
|
|
|
|
|
|
3.测试大数据量下合并的速率,与原版LevelDB作对比。 |
|
|
|
|
|
|
|
4.完成了多种KV分离方案后,将不同方案在Benchmark下进行测试。 |
|
|
|
|
|
|
|
原leveldb: |
|
|
|
|
|
|
|
@ -567,24 +616,25 @@ version_3: |
|
|
|
|
|
|
|
**减少GC开销** |
|
|
|
|
|
|
|
有一种可能的优化是仅在数据写入SSTable之后才会使用Value Log。 |
|
|
|
实现了一些较细的优化点,例如:在GC时先不从valuelog读Value,而是先确认该键值对是否有效,如果无效则无需读出Value(Value较长,读取耗费时间与IO资源) |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
## 7. 分工和进度安排 |
|
|
|
|
|
|
|
| 功能 | 完成日期 | 分工 | |
|
|
|
| ------------------------------------------------- | -------- | ------------- | |
|
|
|
| 完成初步的多字段Value实现和KV分离实现 | 11月20日 | 谢瑞阳 | |
|
|
|
| 完成设计文档 | 11月27日 | 徐翔宇&谢瑞阳 | |
|
|
|
| 将多字段Value实现迁移至用户层级 | 11月27日 | 徐翔宇 | |
|
|
|
| 完成第二版ValueLog的设计 | 11月27日 | 谢瑞阳 | |
|
|
|
| 完成第二版ValueLog的测试 | 11月27日 | 徐翔宇 | |
|
|
|
| 完成第三版ValueLog的函数接口实现以及测试 | 12月1日 | 徐翔宇 | |
|
|
|
| 完成第三版ValueLog的函数实现 | 12月4日 | 谢瑞阳 | |
|
|
|
| 完成BenchMark设计 | 12月8日 | 徐翔宇&谢瑞阳 | |
|
|
|
| 完成BenchMark,对不同KV分离方案进行测试 | 12月11日 | 徐翔宇 | |
|
|
|
| 基于测试结果进行优化,完成第四版ValueLog的设计... | 12月??日 | 徐翔宇&谢瑞阳 | |
|
|
|
| 功能 | 完成日期 | 分工 | |
|
|
|
| ------------------------------------------ | -------- | ------------- | |
|
|
|
| 完成初步的多字段Value实现和KV分离实现 | 11月20日 | 谢瑞阳 | |
|
|
|
| 完成设计文档 | 11月27日 | 徐翔宇&谢瑞阳 | |
|
|
|
| 将多字段Value实现迁移至用户层级 | 11月27日 | 徐翔宇 | |
|
|
|
| 完成第二版ValueLog | 11月28日 | 徐翔宇&谢瑞阳 | |
|
|
|
| 完成第二版ValueLog的测试 | 11月28日 | 徐翔宇&谢瑞阳 | |
|
|
|
| 完成第三版ValueLog | 12月4日 | 徐翔宇&谢瑞阳 | |
|
|
|
| 完成第三版ValueLog的测试 | 12月4日 | 徐翔宇&谢瑞阳 | |
|
|
|
| 完成BenchMark,对不同KV分离方案进行测试 | 12月8日 | 徐翔宇&谢瑞阳 | |
|
|
|
| 学习TiTanDB的代码,学习优化方法 | 12月13日 | 徐翔宇&谢瑞阳 | |
|
|
|
| 明确接下来要做的优化点顺序,进行迭代与优化 | 12月22日 | 徐翔宇&谢瑞阳 | |
|
|
|
| 完成BenchMark设计 | 12月22日 | 徐翔宇&谢瑞阳 | |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
@ -596,4 +646,8 @@ version_3: |
|
|
|
|
|
|
|
- [ ] 在valuelog中调整value和key的顺序,kv_len的储存形式,get的时机应该在读取value之前 |
|
|
|
- [ ] 调整kv分离标志位的位置 |
|
|
|
- [ ] 实现valuelog的block_cache |
|
|
|
- [ ] 实现valuelog的block_cache |
|
|
|
- [ ] 对范围查询做ValueLog预取优化 |
|
|
|
- [ ] 对valueLog做压缩优化(?) |
|
|
|
- [ ] 实现key-only scan(便利用户,一些场景无需找value) |
|
|
|
- [ ] 实现YCSB benchmark测试 |

 小人鱼
9 months ago
小人鱼
9 months ago
{kind=link}