
 李畅
e5aaef2f4c
李畅
e5aaef2f4c
|
há 10 meses | ||
|---|---|---|---|
| .github/workflows | 删除 | há 2 anos | |
| Report | 删除 | há 10 meses | |
| benchmarks | 删除 | há 2 anos | |
| cmake | 删除 | há 5 anos | |
| db | 删除 | há 10 meses | |
| doc | 删除 | há 3 anos | |
| helpers/memenv | 删除 | há 3 anos | |
| img | 删除 | há 10 meses | |
| include/leveldb | 删除 | há 10 meses | |
| issues | 删除 | há 3 anos | |
| port | 删除 | há 2 anos | |
| table | 删除 | há 2 anos | |
| test | 删除 | há 10 meses | |
| third_party | 删除 | há 2 anos | |
| util | 删除 | há 10 meses | |
| .clang-format | há 6 anos | ||
| .gitignore | há 10 meses | ||
| .gitmodules | há 4 anos | ||
| AUTHORS | há 12 anos | ||
| CMakeLists.txt | há 10 meses | ||
| CONTRIBUTING.md | há 3 anos | ||
| LICENSE | há 14 anos | ||
| NEWS | há 14 anos | ||
| README.md | há 10 meses | ||
| TODO | há 13 anos | ||
README.md
实验要求
-
在LevelDB中实现键值对的
TTL(Time-To-Live)功能,使得过期的数据在读取时自动失效,并在适当的时候被合并清理。 -
修改LevelDB的源码,实现对
TTL的支持,包括数据的写入、读取和过期数据的清理。 -
编写测试用例,验证
TTL功能的正确性和稳定性。(Optional)
1. 设计思路和实现过程
1.1 设计思路
Phase 0
在LevelDB中实现TTL功能主要涉及数据的读、写、合并。
在写入数据时,TTL功能是个可选项。从代码层面来说,LevelDB数据的写入调用了Put函数接口:
// 假设增加一个新的Put接口,包含TTL参数, 单位(秒)
Status DB::Put(const WriteOptions& opt, const Slice& key,
const Slice& value, uint64_t ttl);
// 如果调用的是原本的Put接口,那么就不会失效
Status DB::Put(const WriteOptions& opt, const Slice& key,
const Slice& value);
这段代码中,如果存入TTL参数,则调用本实验中新实现的Put函数接口;否则直接调用原有的Put接口。
Phase 1
本小组的思路很简明:
- 直接将
TTL信息在写入阶段添加到原有的数据结构中 - 在读取和合并时从得到的数据中 解读 出其存储的
TTL信息,判断是否过期
因此,接下来需要思考的是如何将TTL信息巧妙地存入LevelDB的数据结构中。
Phase 2
由于插入数据时调用的Put接口只有三个参数,其中opt是写入时的系统配置,实际插入的数据只有key/value,因此存储ttl信息时,最简单的方法就是存入key或value中。
在这样的方法中,可以调用原有的Put函数,将含义ttl信息的key/value数据存入数据库。
经过讨论后,本小组选择将ttl信息存入value中。
这样做的优缺点是:
-
优点:由于LevelDB在合并数据的过程中,需要根据
SSTable的key对数据进行有序化处理,将ttl信息存储在value中不会影响key的信息,因此对已有的合并过程不产生影响 -
缺点:在获取到
SSTable的key时,无法直接判断该文件是否因为ttl而成为过期数据,仍然需要读取对应的value才能判断,多了一步读取开销。但是,实际上在读取数据以及合并数据的过程中,其代码实际上都读取了对应SSTable中存储的value信息,因此获取ttl信息时必要的读取value过程并不是多余的,实际几乎不造成额外的读取开销影响
Phase 3
在确定插入数据时选用的方法后,读取和合并的操作只需要在获取数据文件的value后解读其包含的ttl信息,并判断是否过期就可以了。
1.2 实现过程
1.2.1 写入 Put
首先需要实现的是将ttl信息存入value的方法。Put中获取的ttl参数是该数据文件的生存时间(单位:秒)。本小组对此进行处理方法是通过ttl计算过期时间的时间戳,转码为字符串类型后存入value的最前部,并用|符号与原来的值分隔开。
对于不使用ttl的数据文件,存入0作为ttl,在读取数据时若读到0则表示不使用TTL功能。
将此功能封装为编码和解码文件过期时间(DeadLine)的函数,存储在/util/coding.h文件中:
inline std::string EncodeDeadLine(uint64_t ddl, const Slice& value) { // 存储ttl信息
return std::to_string(ddl) + "|" + value.ToString();
}
inline void DecodeDeadLineValue(std::string* value, uint64_t& ddl) { // 解读ttl信息
auto separator = value->find_first_of("|");
std::string ddl_str = value->substr(0, separator);
ddl = std::atoll(ddl_str.c_str());
*value = value->substr(separator + 1);
}
在写入数据调用Put接口时,分别启用EncodeDeadLine函数存储ttl信息:
// Default implementations of convenience methods that subclasses of DB
// can call if they wish
// TTL: Update TTL Encode
Status DB::Put(const WriteOptions& opt, const Slice& key, const Slice& value) { // 不使用TTL
WriteBatch batch;
batch.Put(key, EncodeDeadLine(0, value));
return Write(opt, &batch);
}
// TTL: Put methods for ttl
Status DB::Put(const WriteOptions& options, const Slice& key,
const Slice& value, uint64_t ttl) { // 使用TTL
WriteBatch batch;
auto dead_line = std::time(nullptr) + ttl; // 计算过期时间的时间戳
batch.Put(key, EncodeDeadLine(dead_line, value));
return Write(options, &batch);
}
1.2.2 读取 Get
LevelDB在读取数据时,调用Get接口,获取文件的key/value,因此只需要在Get函数中加入使用TTL功能的相关代码:
Status DBImpl::Get(const ReadOptions& options, const Slice& key,
std::string* value) {
(......)
// Unlock while reading from files and memtables
{
mutex_.Unlock();
// First look in the memtable, then in the immutable memtable (if any).
LookupKey lkey(key, snapshot);
if (mem->Get(lkey, value, &s)) {
// Done
} else if (imm != nullptr && imm->Get(lkey, value, &s)) {
// Done
} else {
s = current->Get(options, lkey, value, &stats);
have_stat_update = true;
}
// TTL: Get the true value and make sure the data is still living
if(!value->empty()) {
uint64_t dead_line;
DecodeDeadLineValue(value, dead_line);
if (dead_line != 0) {
// use TTL
if (std::time(nullptr) >= dead_line) {
// data expired
*value = "";
s = Status::NotFound("Data expired");
}
} else {
// TTL not set
}
}
mutex_.Lock();
}
(......)
}
若使用了TTL功能,则当文件过期时,返回NotFound("Data expired")的信息,即“数据已清除”。
注意:由于LevelDB对于数据的读取是只读ReadOnly的,因此只能返回NotFound的信息,而无法真正清理过期数据。
1.2.3 合并 Compaction
在合并的过程中,需要做到清理掉过期的数据,释放空间。
在大合并的过程中,需要调用DoCompactionWorks函数实现合并的操作,也是在这个过程中,LevelDB得以真正完成清理旧版本数据、已删除数据并释放空间的过程。
其实现逻辑是在该函数的过程中引入一个布尔变量drop,对于需要清理的数据设置drop为True,而需要保留的数据则是drop为False,最后根据drop的值清理过期数据,并将需要保留的数据合并写入新的SSTable。
因此,我们只需要在判断drop为True的条件中加入对过期时间(DeadLine)的判断就可以实现TTL功能的清理过期数据了:
Status DBImpl::DoCompactionWork(CompactionState* compact) {
(......)
while (input->Valid() && !shutting_down_.load(std::memory_order_acquire)) {
(......)
// Handle key/value, add to state, etc.
bool drop = false;
if (!ParseInternalKey(key, &ikey)) {
// Do not hide error keys
current_user_key.clear();
has_current_user_key = false;
last_sequence_for_key = kMaxSequenceNumber;
} else {
if (!has_current_user_key ||
user_comparator()->Compare(ikey.user_key, Slice(current_user_key)) !=
0) {
// First occurrence of this user key
current_user_key.assign(ikey.user_key.data(), ikey.user_key.size());
has_current_user_key = true;
last_sequence_for_key = kMaxSequenceNumber;
}
std::string value = input->value().ToString();
uint64_t ddl;
DecodeDeadLineValue(&value, ddl);
if (last_sequence_for_key <= compact->smallest_snapshot) {
(......)
} else if (ddl <= std::time(nullptr)) { // 根据ttl判断是否为过期数据
// TTL: data expired
drop = true;
}
last_sequence_for_key = ikey.sequence;
}
(......)
input->Next();
}
(......)
}
理论上,Compaction相关的代码也实现了,但实际上还会存在一些问题。具体问题和解决方法详见 问题和解决方案。
2. 测试用例和测试结果
TestTTL.ReadTTL
TestTTL中第一个测试样例,检测插入和读取数据时,读取过期数据能够正确返回NotFound。

TestTTL.CompactionTTL
TestTTL中第二个测试样例,检测插入和合并数据,能够在触发合并时清除所有过期数据。

然而,当数据库的设定的level过小时,仍然会出现错误。
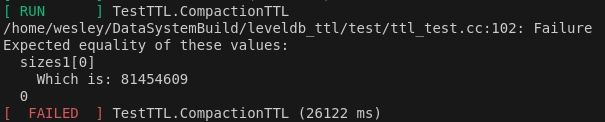
具体问题和解决方法见 问题和解决方案。
TestTTL.LastLevelCompaction
在解决了上面遇到的问题之后,本小组添加了一个测试样例,用来检测在含义SSTable的最大层能否正确检测文件数量和合并、清理过期数据。

最后,展示三个测试样例一起运行的结果:

3. 问题和解决方案
3.1 无法合并和清理所有数据文件
本实验的问题和合并Compaction有关。
LevelDB中Compaction的逻辑是选中特定层(level)合并,假设为level n。在level n中找目标文件SSTable A(假设该次触发的合并从文件A开始),并确定level n以及level n+1中与SSTable A包含的数据(key/value)有key发生重复(overlap)的所有文件,合并后产生新的SSTable B放入level n+1层中。
这样引发的问题是:由DoCompactionWorks代码可知,不参与合并的文件无法被获取信息,因而即使过期了也无法被清理。在此例子中,若level n+1层中有含有过期数据的SSTable C,但SSTable C与SSTable A发生合并时触及的所有文件都没有overlap的话,则在该次合并中并没有被触及,因而无法被清理。
再次强调,合并过程必须清理所有已经过期的数据(尽管这听起来有些让人困惑,因为正常使用时,没有被合并的过期数据即使未被清理也不影响正常使用),而无法被清理的SSTable C明显是个例外,是个错误。
而在LevelDB提供的CompactRange(nullptr,nullptr)这个“合并所有数据”的功能中,同样会发生这样的错误,导致有部分数据文件并没有在合并过程中被触及——即使它声称合并了所有数据。
从代码层面可以理解导致该错误的原因。原来的代码:
void DBImpl::CompactRange(const Slice* begin, const Slice* end) {
int max_level_with_files = 1;
{
MutexLock l(&mutex_);
Version* base = versions_->current();
for (int level = 1; level < config::kNumLevels; level++) {
if (base->OverlapInLevel(level, begin, end)) {
max_level_with_files = level;
}
}
}
TEST_CompactMemTable(); // TODO(sanjay): Skip if memtable does not overlap
for (int level = 0; level < max_level_with_files; level++) {
TEST_CompactRange(level, begin, end);
}
}
void DBImpl::TEST_CompactRange(int level, const Slice* begin,
const Slice* end) {
assert(level >= 0);
assert(level + 1 < config::kNumLevels);
(......)
}
这里注意两个数:config::kNumLevels和max_level_with_files:
-
config::kNumLevels:是LevelDB在启动时设定的数,表示总共使用的
level层数。默认值为7 -
max_level_with_files:表示含有
SSTable文件的最高层的编号。注意,这里的level编号是从0开始的,因此max_level_with_files理论最大值是config::kNumLevels - 1
在原来的代码中,DBImpl::CompactRange函数中的最后一个循环,选择的level无法到达max_level_with_files,因此即使“合并所有数据”,也没法触及max_level_with_files中的所有文件,而是对max_level_with_files - 1层的所有文件做了大合并。
修改后的代码如下:
void DBImpl::CompactRange(const Slice* begin, const Slice* end) {
int max_level_with_files = 1;
{
MutexLock l(&mutex_);
Version* base = versions_->current();
for (int level = 1; level < config::kNumLevels; level++) {
if (base->OverlapInLevel(level, begin, end)) {
max_level_with_files = level;
}
}
}
TEST_CompactMemTable(); // TODO(sanjay): Skip if memtable does not overlap
for (int level = 0; level < max_level_with_files + 1; level++) {
TEST_CompactRange(level, begin, end);
}
}
void DBImpl::TEST_CompactRange(int level, const Slice* begin,
const Slice* end) {
assert(level >= 0);
assert(level < config::kNumLevels);
(......)
}
简单的方法是直接修改了循环的条件和相关函数TEST_CompactRange的判断条件,使得level可以到达max_level_with_files,这样就可以真正地合并所有文件并清理过期数据。
3.2 最后一层文件堆积且无法清理
在上一个问题中的解决方法在遇到最后一层(MaxLevel),即level == config::kNumLevels - 1时失效,因为这个时候的Compaction无法再找到level + 1的文件合并了,因为level + 1层根本不存在。
在测试样例中,由于存入的文件到达不了MaxLevel,并不会遇到这种情况,因此可以顺利通过样例。为了制造出现错误的情况,可以将config::kNumLevels设置为较小值(如:3)再运行测试。这种情况放在git仓库的light_ver分支的修改里了。
这同时引发了另一个问题的思考:当存储的数据文件(SSTable)已经存放在最高层MaxLevel中时,无法被合并和清除,因此本小组决定对涉及MaxLevel的合并做优化。
我们选择的优化方式基于以下思考:
- 通常情况下,
MaxLevel仅在手动触发的大合并即Manual Compaction中使用到,而自动合并Size Compaction和Seek Compaction几乎不会发生在MaxLevel,理由是:- Seek Compaction的情况:由于
MaxLevel没有“下一层”,当在该层的seek查找不到文件时则返回NotFound,不可能触发Seek Compaction - Size Compaction的情况:由于数据库的
SSTable通常按层顺序存储,若MaxLevel的存储文件大小达到上限,说明数据库的存储容量已经满了
- Seek Compaction的情况:由于
- 在大合并中,由于针对上个问题的修改方案,当
level到达max_level_with_files时,会和下一层(此时为空)合并,导致合并后的文件会存入下一层,然而这个操作的目的仅仅是清理max_level_with_files的过期数据而已,并不需要移动文件,且这样做更早地使用了更高的level
优化方案:修改Manual Compaction相关的函数CompactRange、TEST_CompactRange和InstallCompactionResults,以及Manual Compaction类、Compaction类,向它们引入布尔类型变量is_last_level,判断当前层是否是max_level_with_files。
主要修改的函数:
void VersionSet::SetupOtherInputs(Compaction* c) {
const int level = c->level();
InternalKey smallest, largest;
AddBoundaryInputs(icmp_, current_->files_[level], &c->inputs_[0]);
GetRange(c->inputs_[0], &smallest, &largest);
// TTL: manual compaction for last level shouldn't have inputs[1]
if (!c->is_last_level()) {
current_->GetOverlappingInputs(level + 1, &smallest, &largest,
&c->inputs_[1]);
AddBoundaryInputs(icmp_, current_->files_[level + 1], &c->inputs_[1]);
}
(......)
if (!c->inputs_[1].empty()) {
(......)
}
(......)
}
若当前合并的level是max_level_with_files,则Compaction* c不需要inputs_[1],相当于和一个空的level进行合并。
Status DBImpl::InstallCompactionResults(CompactionState* compact) {
(......)
for (size_t i = 0; i < compact->outputs.size(); i++) {
const CompactionState::Output& out = compact->outputs[i];
if (!compact->compaction->is_last_level()) {
compact->compaction->edit()->AddFile(level + 1, out.number, out.file_size, out.smallest, out.largest);
} else {
// TTL: outputs of last level compaction should be writen to last level itself
compact->compaction->edit()->AddFile(level, out.number, out.file_size, out.smallest, out.largest);
}
}
return versions_->LogAndApply(compact->compaction->edit(), &mutex_);
}
添加判断条件,若当前层是最高层,则合并后的文件仍然放在本层。
修改后,可以同时解决提到的两个问题,成功清理最高层的过期数据文件。