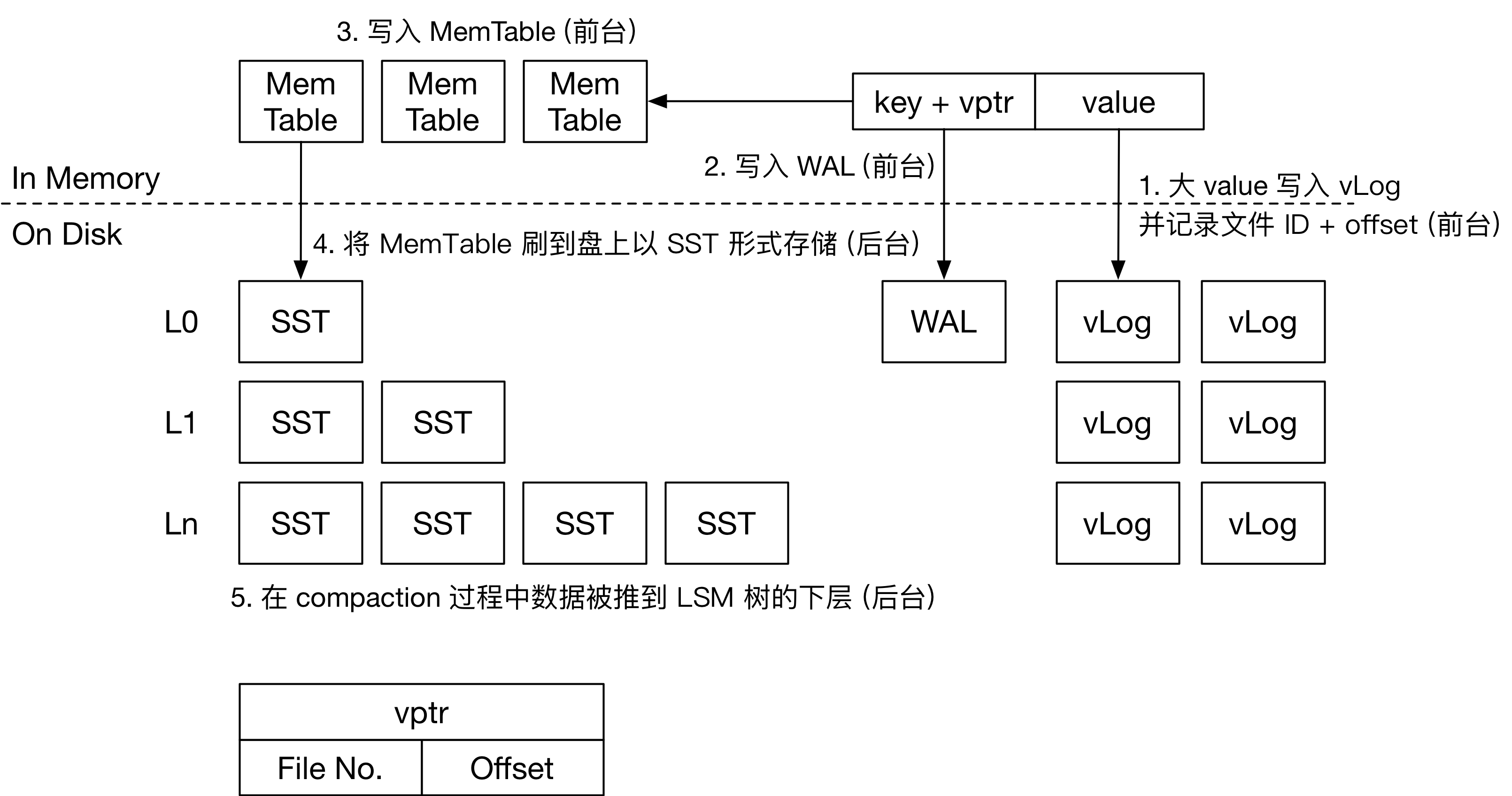
|
|
@ -11,7 +11,9 @@ |
|
|
#include <set>
|
|
|
#include <set>
|
|
|
#include <string>
|
|
|
#include <string>
|
|
|
#include <vector>
|
|
|
#include <vector>
|
|
|
|
|
|
#include <iostream>
|
|
|
|
|
|
|
|
|
|
|
|
#include "fields.h"
|
|
|
#include "db/builder.h"
|
|
|
#include "db/builder.h"
|
|
|
#include "db/db_iter.h"
|
|
|
#include "db/db_iter.h"
|
|
|
#include "db/dbformat.h"
|
|
|
#include "db/dbformat.h"
|
|
|
@ -35,8 +37,12 @@ |
|
|
#include "util/logging.h"
|
|
|
#include "util/logging.h"
|
|
|
#include "util/mutexlock.h"
|
|
|
#include "util/mutexlock.h"
|
|
|
|
|
|
|
|
|
|
|
|
#include "db/vlog_reader.h"
|
|
|
|
|
|
|
|
|
namespace leveldb { |
|
|
namespace leveldb { |
|
|
|
|
|
|
|
|
|
|
|
using namespace log; |
|
|
|
|
|
|
|
|
const int kNumNonTableCacheFiles = 10; |
|
|
const int kNumNonTableCacheFiles = 10; |
|
|
|
|
|
|
|
|
// Information kept for every waiting writer
|
|
|
// Information kept for every waiting writer
|
|
|
@ -136,16 +142,25 @@ DBImpl::DBImpl(const Options& raw_options, const std::string& dbname) |
|
|
db_lock_(nullptr), |
|
|
db_lock_(nullptr), |
|
|
shutting_down_(false), |
|
|
shutting_down_(false), |
|
|
background_work_finished_signal_(&mutex_), |
|
|
background_work_finished_signal_(&mutex_), |
|
|
|
|
|
|
|
|
|
|
|
garbage_collection_work_signal_(&mutex_), |
|
|
|
|
|
|
|
|
mem_(nullptr), |
|
|
mem_(nullptr), |
|
|
imm_(nullptr), |
|
|
imm_(nullptr), |
|
|
has_imm_(false), |
|
|
has_imm_(false), |
|
|
logfile_(nullptr), |
|
|
logfile_(nullptr), |
|
|
logfile_number_(0), |
|
|
logfile_number_(0), |
|
|
log_(nullptr), |
|
|
|
|
|
seed_(0), |
|
|
seed_(0), |
|
|
tmp_batch_(new WriteBatch), |
|
|
tmp_batch_(new WriteBatch), |
|
|
|
|
|
|
|
|
background_compaction_scheduled_(false), |
|
|
background_compaction_scheduled_(false), |
|
|
|
|
|
background_GarbageCollection_scheduled_(false), |
|
|
|
|
|
finish_back_garbage_collection_(false), |
|
|
manual_compaction_(nullptr), |
|
|
manual_compaction_(nullptr), |
|
|
|
|
|
|
|
|
|
|
|
vlog_(nullptr), |
|
|
|
|
|
vlog_kv_numbers_(0), |
|
|
|
|
|
garbage_collection_management_(new SeparateManagement(raw_options.garbage_collection_threshold) ), |
|
|
versions_(new VersionSet(dbname_, &options_, table_cache_, |
|
|
versions_(new VersionSet(dbname_, &options_, table_cache_, |
|
|
&internal_comparator_)) {} |
|
|
&internal_comparator_)) {} |
|
|
|
|
|
|
|
|
@ -156,6 +171,9 @@ DBImpl::~DBImpl() { |
|
|
while (background_compaction_scheduled_) { |
|
|
while (background_compaction_scheduled_) { |
|
|
background_work_finished_signal_.Wait(); |
|
|
background_work_finished_signal_.Wait(); |
|
|
} |
|
|
} |
|
|
|
|
|
while(background_GarbageCollection_scheduled_){ |
|
|
|
|
|
garbage_collection_work_signal_.Wait(); |
|
|
|
|
|
} |
|
|
mutex_.Unlock(); |
|
|
mutex_.Unlock(); |
|
|
|
|
|
|
|
|
if (db_lock_ != nullptr) { |
|
|
if (db_lock_ != nullptr) { |
|
|
@ -166,7 +184,7 @@ DBImpl::~DBImpl() { |
|
|
if (mem_ != nullptr) mem_->Unref(); |
|
|
if (mem_ != nullptr) mem_->Unref(); |
|
|
if (imm_ != nullptr) imm_->Unref(); |
|
|
if (imm_ != nullptr) imm_->Unref(); |
|
|
delete tmp_batch_; |
|
|
delete tmp_batch_; |
|
|
delete log_; |
|
|
|
|
|
|
|
|
delete vlog_; |
|
|
delete logfile_; |
|
|
delete logfile_; |
|
|
delete table_cache_; |
|
|
delete table_cache_; |
|
|
|
|
|
|
|
|
@ -213,6 +231,14 @@ Status DBImpl::NewDB() { |
|
|
return s; |
|
|
return s; |
|
|
} |
|
|
} |
|
|
|
|
|
|
|
|
|
|
|
Env* DBImpl::GetEnv() const { |
|
|
|
|
|
return env_; |
|
|
|
|
|
} |
|
|
|
|
|
|
|
|
|
|
|
std::string DBImpl::GetDBName() const { |
|
|
|
|
|
return dbname_; |
|
|
|
|
|
} |
|
|
|
|
|
|
|
|
void DBImpl::MaybeIgnoreError(Status* s) const { |
|
|
void DBImpl::MaybeIgnoreError(Status* s) const { |
|
|
if (s->ok() || options_.paranoid_checks) { |
|
|
if (s->ok() || options_.paranoid_checks) { |
|
|
// No change needed
|
|
|
// No change needed
|
|
|
@ -346,11 +372,17 @@ Status DBImpl::Recover(VersionEdit* edit, bool* save_manifest) { |
|
|
uint64_t number; |
|
|
uint64_t number; |
|
|
FileType type; |
|
|
FileType type; |
|
|
std::vector<uint64_t> logs; |
|
|
std::vector<uint64_t> logs; |
|
|
|
|
|
uint64_t max_number = 0; |
|
|
for (size_t i = 0; i < filenames.size(); i++) { |
|
|
for (size_t i = 0; i < filenames.size(); i++) { |
|
|
if (ParseFileName(filenames[i], &number, &type)) { |
|
|
if (ParseFileName(filenames[i], &number, &type)) { |
|
|
|
|
|
// begin 注释: max_number 为要恢复的最新的文件编号
|
|
|
|
|
|
if (number > max_number) max_number = number; |
|
|
|
|
|
// expected 里的文件现在依然存在,可以删除
|
|
|
expected.erase(number); |
|
|
expected.erase(number); |
|
|
if (type == kLogFile && ((number >= min_log) || (number == prev_log))) |
|
|
|
|
|
|
|
|
// 保存当前已有的 vlog 文件,基于它们进行恢复
|
|
|
|
|
|
if (type == kLogFile) |
|
|
logs.push_back(number); |
|
|
logs.push_back(number); |
|
|
|
|
|
// end
|
|
|
} |
|
|
} |
|
|
} |
|
|
} |
|
|
if (!expected.empty()) { |
|
|
if (!expected.empty()) { |
|
|
@ -362,18 +394,34 @@ Status DBImpl::Recover(VersionEdit* edit, bool* save_manifest) { |
|
|
|
|
|
|
|
|
// Recover in the order in which the logs were generated
|
|
|
// Recover in the order in which the logs were generated
|
|
|
std::sort(logs.begin(), logs.end()); |
|
|
std::sort(logs.begin(), logs.end()); |
|
|
for (size_t i = 0; i < logs.size(); i++) { |
|
|
|
|
|
s = RecoverLogFile(logs[i], (i == logs.size() - 1), save_manifest, edit, |
|
|
|
|
|
&max_sequence); |
|
|
|
|
|
if (!s.ok()) { |
|
|
|
|
|
return s; |
|
|
|
|
|
} |
|
|
|
|
|
|
|
|
|
|
|
// The previous incarnation may not have written any MANIFEST
|
|
|
|
|
|
// records after allocating this log number. So we manually
|
|
|
|
|
|
// update the file number allocation counter in VersionSet.
|
|
|
|
|
|
versions_->MarkFileNumberUsed(logs[i]); |
|
|
|
|
|
|
|
|
assert( logs.size() == 0 || logs[logs.size() - 1] >= versions_->ImmLogFileNumber() ); |
|
|
|
|
|
// for (size_t i = 0; i < logs.size(); i++) {
|
|
|
|
|
|
// s = RecoverLogFile(logs[i], (i == logs.size() - 1), save_manifest, edit,
|
|
|
|
|
|
// &max_sequence);
|
|
|
|
|
|
// if (!s.ok()) {
|
|
|
|
|
|
// return s;
|
|
|
|
|
|
// }
|
|
|
|
|
|
|
|
|
|
|
|
// // The previous incarnation may not have written any MANIFEST
|
|
|
|
|
|
// // records after allocating this log number. So we manually
|
|
|
|
|
|
// // update the file number allocation counter in VersionSet.
|
|
|
|
|
|
// versions_->MarkFileNumberUsed(logs[i]);
|
|
|
|
|
|
// }
|
|
|
|
|
|
//注释:逐个恢复日志的内容
|
|
|
|
|
|
bool found_sequence_pos = false; |
|
|
|
|
|
for(int i = 0; i < logs.size(); ++i){ |
|
|
|
|
|
if( logs[i] < versions_->ImmLogFileNumber() ) { |
|
|
|
|
|
continue; |
|
|
|
|
|
} |
|
|
|
|
|
Log(options_.info_log, "RecoverLogFile old log: %06llu \n", static_cast<unsigned long long>(logs[i])); |
|
|
|
|
|
// 重做日志操作
|
|
|
|
|
|
s = RecoverLogFile(logs[i], (i == logs.size() - 1), save_manifest, edit, |
|
|
|
|
|
&max_sequence, found_sequence_pos); |
|
|
|
|
|
if (!s.ok()) { |
|
|
|
|
|
return s; |
|
|
|
|
|
} |
|
|
} |
|
|
} |
|
|
|
|
|
versions_->MarkFileNumberUsed(max_number); |
|
|
|
|
|
|
|
|
if (versions_->LastSequence() < max_sequence) { |
|
|
if (versions_->LastSequence() < max_sequence) { |
|
|
versions_->SetLastSequence(max_sequence); |
|
|
versions_->SetLastSequence(max_sequence); |
|
|
@ -382,9 +430,11 @@ Status DBImpl::Recover(VersionEdit* edit, bool* save_manifest) { |
|
|
return Status::OK(); |
|
|
return Status::OK(); |
|
|
} |
|
|
} |
|
|
|
|
|
|
|
|
|
|
|
/* 恢复内存中的数据,将 VLog 中记录的操作读取出来,重新写入到 memtable */ |
|
|
Status DBImpl::RecoverLogFile(uint64_t log_number, bool last_log, |
|
|
Status DBImpl::RecoverLogFile(uint64_t log_number, bool last_log, |
|
|
bool* save_manifest, VersionEdit* edit, |
|
|
bool* save_manifest, VersionEdit* edit, |
|
|
SequenceNumber* max_sequence) { |
|
|
|
|
|
|
|
|
SequenceNumber* max_sequence, |
|
|
|
|
|
bool& found_sequence_pos) { |
|
|
struct LogReporter : public log::Reader::Reporter { |
|
|
struct LogReporter : public log::Reader::Reporter { |
|
|
Env* env; |
|
|
Env* env; |
|
|
Logger* info_log; |
|
|
Logger* info_log; |
|
|
@ -427,21 +477,52 @@ Status DBImpl::RecoverLogFile(uint64_t log_number, bool last_log, |
|
|
std::string scratch; |
|
|
std::string scratch; |
|
|
Slice record; |
|
|
Slice record; |
|
|
WriteBatch batch; |
|
|
WriteBatch batch; |
|
|
|
|
|
uint64_t record_offset = 0; |
|
|
int compactions = 0; |
|
|
int compactions = 0; |
|
|
MemTable* mem = nullptr; |
|
|
MemTable* mem = nullptr; |
|
|
|
|
|
//注释:设置 imm_last_sequence
|
|
|
|
|
|
uint64_t imm_last_sequence = versions_->ImmLastSequence(); |
|
|
while (reader.ReadRecord(&record, &scratch) && status.ok()) { |
|
|
while (reader.ReadRecord(&record, &scratch) && status.ok()) { |
|
|
if (record.size() < 12) { |
|
|
|
|
|
|
|
|
// if (record.size() < 12) {
|
|
|
|
|
|
if (record.size() < 20) { |
|
|
reporter.Corruption(record.size(), |
|
|
reporter.Corruption(record.size(), |
|
|
Status::Corruption("log record too small")); |
|
|
Status::Corruption("log record too small")); |
|
|
continue; |
|
|
continue; |
|
|
} |
|
|
} |
|
|
|
|
|
// begin 如果 imm_last_sequence == 0 的话,
|
|
|
|
|
|
// 那么整个说明没有进行一次 imm 转 sst的情况,所有的 log 文件都需要进行回收
|
|
|
|
|
|
// 回收编号最大的 log 文件即可
|
|
|
|
|
|
if( !found_sequence_pos && imm_last_sequence != 0 ){ |
|
|
|
|
|
Slice tmp = record; |
|
|
|
|
|
tmp.remove_prefix(8); |
|
|
|
|
|
uint64_t seq = DecodeFixed64(tmp.data()); |
|
|
|
|
|
tmp.remove_prefix(8); |
|
|
|
|
|
uint64_t kv_numbers = DecodeFixed32(tmp.data()); |
|
|
|
|
|
|
|
|
|
|
|
// 解析出来的 seq 不符合要求跳过。恢复时定位 seq 位置一定要大于等于 versions_->LastSequence()
|
|
|
|
|
|
if( ( seq + kv_numbers - 1 ) < imm_last_sequence ) { |
|
|
|
|
|
record_offset += record.size(); |
|
|
|
|
|
continue; |
|
|
|
|
|
}else if( ( seq + kv_numbers - 1 ) == imm_last_sequence ){ |
|
|
|
|
|
// open db 落盘过 sst,再一次打开 db
|
|
|
|
|
|
found_sequence_pos = true; |
|
|
|
|
|
record_offset += record.size(); |
|
|
|
|
|
continue; |
|
|
|
|
|
} else { // open db 之后没有落盘过 sst,然后关闭 db,第二次恢复的时候
|
|
|
|
|
|
found_sequence_pos = true; |
|
|
|
|
|
} |
|
|
|
|
|
} |
|
|
|
|
|
// 去除头部信息 crc 和length
|
|
|
|
|
|
record.remove_prefix(log::vHeaderSize); |
|
|
|
|
|
// end
|
|
|
WriteBatchInternal::SetContents(&batch, record); |
|
|
WriteBatchInternal::SetContents(&batch, record); |
|
|
|
|
|
|
|
|
if (mem == nullptr) { |
|
|
if (mem == nullptr) { |
|
|
mem = new MemTable(internal_comparator_); |
|
|
mem = new MemTable(internal_comparator_); |
|
|
mem->Ref(); |
|
|
mem->Ref(); |
|
|
} |
|
|
} |
|
|
status = WriteBatchInternal::InsertInto(&batch, mem); |
|
|
|
|
|
|
|
|
// status = WriteBatchInternal::InsertInto(&batch, mem);
|
|
|
|
|
|
status = WriteBatchInternal::InsertInto(&batch, mem,log_number,record_offset + 4); |
|
|
MaybeIgnoreError(&status); |
|
|
MaybeIgnoreError(&status); |
|
|
if (!status.ok()) { |
|
|
if (!status.ok()) { |
|
|
break; |
|
|
break; |
|
|
@ -455,6 +536,11 @@ Status DBImpl::RecoverLogFile(uint64_t log_number, bool last_log, |
|
|
if (mem->ApproximateMemoryUsage() > options_.write_buffer_size) { |
|
|
if (mem->ApproximateMemoryUsage() > options_.write_buffer_size) { |
|
|
compactions++; |
|
|
compactions++; |
|
|
*save_manifest = true; |
|
|
*save_manifest = true; |
|
|
|
|
|
|
|
|
|
|
|
// 注释:mem 落盘修改 imm_last_sequence,版本恢复
|
|
|
|
|
|
versions_->SetImmLastSequence(mem->GetTailSequence()); |
|
|
|
|
|
versions_->SetImmLogFileNumber(log_number); |
|
|
|
|
|
|
|
|
status = WriteLevel0Table(mem, edit, nullptr); |
|
|
status = WriteLevel0Table(mem, edit, nullptr); |
|
|
mem->Unref(); |
|
|
mem->Unref(); |
|
|
mem = nullptr; |
|
|
mem = nullptr; |
|
|
@ -464,6 +550,8 @@ Status DBImpl::RecoverLogFile(uint64_t log_number, bool last_log, |
|
|
break; |
|
|
break; |
|
|
} |
|
|
} |
|
|
} |
|
|
} |
|
|
|
|
|
// 前面已经移除了一个头部了,所以偏移位置要个头部
|
|
|
|
|
|
record_offset += record.size() + log::vHeaderSize ; |
|
|
} |
|
|
} |
|
|
|
|
|
|
|
|
delete file; |
|
|
delete file; |
|
|
@ -471,13 +559,13 @@ Status DBImpl::RecoverLogFile(uint64_t log_number, bool last_log, |
|
|
// See if we should keep reusing the last log file.
|
|
|
// See if we should keep reusing the last log file.
|
|
|
if (status.ok() && options_.reuse_logs && last_log && compactions == 0) { |
|
|
if (status.ok() && options_.reuse_logs && last_log && compactions == 0) { |
|
|
assert(logfile_ == nullptr); |
|
|
assert(logfile_ == nullptr); |
|
|
assert(log_ == nullptr); |
|
|
|
|
|
|
|
|
assert(vlog_ == nullptr); |
|
|
assert(mem_ == nullptr); |
|
|
assert(mem_ == nullptr); |
|
|
uint64_t lfile_size; |
|
|
uint64_t lfile_size; |
|
|
if (env_->GetFileSize(fname, &lfile_size).ok() && |
|
|
if (env_->GetFileSize(fname, &lfile_size).ok() && |
|
|
env_->NewAppendableFile(fname, &logfile_).ok()) { |
|
|
env_->NewAppendableFile(fname, &logfile_).ok()) { |
|
|
Log(options_.info_log, "Reusing old log %s \n", fname.c_str()); |
|
|
Log(options_.info_log, "Reusing old log %s \n", fname.c_str()); |
|
|
log_ = new log::Writer(logfile_, lfile_size); |
|
|
|
|
|
|
|
|
vlog_ = new log::VlogWriter(logfile_, lfile_size); |
|
|
logfile_number_ = log_number; |
|
|
logfile_number_ = log_number; |
|
|
if (mem != nullptr) { |
|
|
if (mem != nullptr) { |
|
|
mem_ = mem; |
|
|
mem_ = mem; |
|
|
@ -493,6 +581,10 @@ Status DBImpl::RecoverLogFile(uint64_t log_number, bool last_log, |
|
|
if (mem != nullptr) { |
|
|
if (mem != nullptr) { |
|
|
// mem did not get reused; compact it.
|
|
|
// mem did not get reused; compact it.
|
|
|
if (status.ok()) { |
|
|
if (status.ok()) { |
|
|
|
|
|
|
|
|
|
|
|
//注释: mem 落盘修改 imm_last_sequence,版本恢复
|
|
|
|
|
|
versions_->SetImmLastSequence(mem->GetTailSequence()); |
|
|
|
|
|
versions_->SetImmLogFileNumber(log_number); |
|
|
*save_manifest = true; |
|
|
*save_manifest = true; |
|
|
status = WriteLevel0Table(mem, edit, nullptr); |
|
|
status = WriteLevel0Table(mem, edit, nullptr); |
|
|
} |
|
|
} |
|
|
@ -565,7 +657,13 @@ void DBImpl::CompactMemTable() { |
|
|
if (s.ok()) { |
|
|
if (s.ok()) { |
|
|
edit.SetPrevLogNumber(0); |
|
|
edit.SetPrevLogNumber(0); |
|
|
edit.SetLogNumber(logfile_number_); // Earlier logs no longer needed
|
|
|
edit.SetLogNumber(logfile_number_); // Earlier logs no longer needed
|
|
|
|
|
|
// s = versions_->LogAndApply(&edit, &mutex_);
|
|
|
|
|
|
//注释: 构建新版本,并将其加入到 version_当中
|
|
|
|
|
|
versions_->StartImmLastSequence(true); |
|
|
|
|
|
versions_->SetImmLastSequence(imm_->GetTailSequence()); |
|
|
|
|
|
versions_->SetImmLogFileNumber(imm_->GetLogFileNumber()); |
|
|
s = versions_->LogAndApply(&edit, &mutex_); |
|
|
s = versions_->LogAndApply(&edit, &mutex_); |
|
|
|
|
|
versions_->StartImmLastSequence(false); |
|
|
} |
|
|
} |
|
|
|
|
|
|
|
|
if (s.ok()) { |
|
|
if (s.ok()) { |
|
|
@ -661,6 +759,8 @@ void DBImpl::RecordBackgroundError(const Status& s) { |
|
|
if (bg_error_.ok()) { |
|
|
if (bg_error_.ok()) { |
|
|
bg_error_ = s; |
|
|
bg_error_ = s; |
|
|
background_work_finished_signal_.SignalAll(); |
|
|
background_work_finished_signal_.SignalAll(); |
|
|
|
|
|
// 注释:唤醒后台 GC 线程
|
|
|
|
|
|
garbage_collection_work_signal_.SignalAll(); |
|
|
} |
|
|
} |
|
|
} |
|
|
} |
|
|
|
|
|
|
|
|
@ -681,6 +781,190 @@ void DBImpl::MaybeScheduleCompaction() { |
|
|
} |
|
|
} |
|
|
} |
|
|
} |
|
|
|
|
|
|
|
|
|
|
|
// 注释:获取所有 VLogs
|
|
|
|
|
|
Status DBImpl::GetAllValueLog(std::string dir, std::vector<uint64_t>& logs) { |
|
|
|
|
|
logs.clear(); |
|
|
|
|
|
std::vector<std::string> filenames; |
|
|
|
|
|
// 获取 VLogs 列表
|
|
|
|
|
|
Status s = env_->GetChildren(dir, &filenames); |
|
|
|
|
|
if (!s.ok()) { |
|
|
|
|
|
return s; |
|
|
|
|
|
} |
|
|
|
|
|
uint64_t number; |
|
|
|
|
|
FileType type; |
|
|
|
|
|
for (size_t i = 0; i < filenames.size(); i++) { |
|
|
|
|
|
if (ParseFileName(filenames[i], &number, &type)) { |
|
|
|
|
|
// 获取所有 .log 文件
|
|
|
|
|
|
if (type == kLogFile) |
|
|
|
|
|
logs.push_back(number); |
|
|
|
|
|
} |
|
|
|
|
|
} |
|
|
|
|
|
return s; |
|
|
|
|
|
} |
|
|
|
|
|
|
|
|
|
|
|
// 注释:手动进行离线回收
|
|
|
|
|
|
Status DBImpl::OutLineGarbageCollection(){ |
|
|
|
|
|
MutexLock l(&mutex_); |
|
|
|
|
|
Status s; |
|
|
|
|
|
// map_file_info_ 非空,则根据它进行回收,否则进行所有 VLog 的回收
|
|
|
|
|
|
if (!garbage_collection_management_->EmptyMap()) { |
|
|
|
|
|
garbage_collection_management_->CollectionMap(); |
|
|
|
|
|
uint64_t last_sequence = versions_->LastSequence(); |
|
|
|
|
|
garbage_collection_management_->ConvertQueue(last_sequence); |
|
|
|
|
|
versions_->SetLastSequence(last_sequence); |
|
|
|
|
|
MaybeScheduleGarbageCollection(); |
|
|
|
|
|
return Status(); |
|
|
|
|
|
} |
|
|
|
|
|
return s; |
|
|
|
|
|
} |
|
|
|
|
|
|
|
|
|
|
|
// 注释:在线 GC,读取并回收一个 vlog 文件,
|
|
|
|
|
|
// next_sequence 指的是第一个没有用到的 sequence(由于是在线 GC ,所以需要提前指定)
|
|
|
|
|
|
Status DBImpl::CollectionValueLog(uint64_t fid, uint64_t& next_sequence) { |
|
|
|
|
|
|
|
|
|
|
|
struct LogReporter : public log::VlogReader::Reporter { |
|
|
|
|
|
Status* status; |
|
|
|
|
|
void Corruption(size_t bytes, const Status& s) override { |
|
|
|
|
|
if (this->status->ok()) *this->status = s; |
|
|
|
|
|
} |
|
|
|
|
|
}; |
|
|
|
|
|
LogReporter report; |
|
|
|
|
|
std::string logName = LogFileName(dbname_, fid); |
|
|
|
|
|
SequentialFile* lfile; |
|
|
|
|
|
Status status = env_->NewSequentialFile(logName, &lfile); |
|
|
|
|
|
if (!status.ok()) { |
|
|
|
|
|
Log(options_.info_log, "Garbage Collection Open file error: %s", status.ToString().c_str()); |
|
|
|
|
|
return status; |
|
|
|
|
|
} |
|
|
|
|
|
log::VlogReader reader(lfile, &report); |
|
|
|
|
|
|
|
|
|
|
|
Slice record; |
|
|
|
|
|
std::string scratch; |
|
|
|
|
|
// record_offset 是每条 record 相对 VLog head 的偏移
|
|
|
|
|
|
uint64_t record_offset = 0; |
|
|
|
|
|
uint64_t size_offset = 0; |
|
|
|
|
|
WriteOptions opt(options_.background_garbage_collection_separate_); |
|
|
|
|
|
WriteBatch batch(opt.separate_threshold); |
|
|
|
|
|
batch.setGarbageCollection(true); |
|
|
|
|
|
WriteBatchInternal::SetSequence(&batch, next_sequence); |
|
|
|
|
|
|
|
|
|
|
|
while (reader.ReadRecord(&record, &scratch)) { |
|
|
|
|
|
const char* head_record_ptr = record.data(); |
|
|
|
|
|
record.remove_prefix(log::vHeaderSize + log::wHeaderSize); |
|
|
|
|
|
|
|
|
|
|
|
while (record.size() > 0) { |
|
|
|
|
|
const char* head_kv_ptr = record.data(); |
|
|
|
|
|
uint64_t kv_offset = record_offset + head_kv_ptr - head_record_ptr; |
|
|
|
|
|
ValueType type = static_cast<ValueType>(record[0]); |
|
|
|
|
|
record.remove_prefix(1); |
|
|
|
|
|
Slice key; |
|
|
|
|
|
Slice value; |
|
|
|
|
|
std::string get_value; |
|
|
|
|
|
GetLengthPrefixedSlice(&record,&key); |
|
|
|
|
|
if (type != kTypeDeletion) { |
|
|
|
|
|
GetLengthPrefixedSlice(&record,&value); |
|
|
|
|
|
} |
|
|
|
|
|
if (type != kTypeSeparation) { |
|
|
|
|
|
continue; |
|
|
|
|
|
} |
|
|
|
|
|
|
|
|
|
|
|
status = this->GetLsm(key,&get_value); |
|
|
|
|
|
// 1. 从 LSM-tree 中找不到 key,说明这个 key 被删除了,vlog中要丢弃
|
|
|
|
|
|
// 2. 找到了 key,但是最新的 kv 对不是 KV 分离的情况,也丢弃
|
|
|
|
|
|
if (status.IsNotFound() || !status.IsSeparated()) { |
|
|
|
|
|
continue; |
|
|
|
|
|
} |
|
|
|
|
|
if (!status.ok()) { |
|
|
|
|
|
std::cout<<"read the file error "<<std::endl; |
|
|
|
|
|
return status; |
|
|
|
|
|
} |
|
|
|
|
|
|
|
|
|
|
|
// 判断是否要丢弃旧值
|
|
|
|
|
|
Slice get_slice(get_value); |
|
|
|
|
|
uint64_t lsm_fid; |
|
|
|
|
|
uint64_t lsm_offset; |
|
|
|
|
|
|
|
|
|
|
|
GetVarint64(&get_slice,&lsm_fid); |
|
|
|
|
|
GetVarint64(&get_slice,&lsm_offset); |
|
|
|
|
|
|
|
|
|
|
|
if (fid == lsm_fid && lsm_offset == kv_offset) { |
|
|
|
|
|
batch.Put(key, value); |
|
|
|
|
|
++next_sequence; |
|
|
|
|
|
if (kv_offset - size_offset > config::gcWriteBatchSize) { |
|
|
|
|
|
Write(opt, &batch); |
|
|
|
|
|
batch.Clear(); |
|
|
|
|
|
batch.setGarbageCollection(true); |
|
|
|
|
|
WriteBatchInternal::SetSequence(&batch, next_sequence); |
|
|
|
|
|
uint64_t kv_size; |
|
|
|
|
|
GetVarint64(&get_slice,&kv_size); |
|
|
|
|
|
size_offset = kv_offset + kv_size; |
|
|
|
|
|
} |
|
|
|
|
|
} |
|
|
|
|
|
} |
|
|
|
|
|
record_offset += record.data() - head_record_ptr; |
|
|
|
|
|
} |
|
|
|
|
|
|
|
|
|
|
|
Write(opt, &batch); |
|
|
|
|
|
status = env_->RemoveFile(logName); |
|
|
|
|
|
if (status.ok()) { |
|
|
|
|
|
garbage_collection_management_->RemoveFileFromMap(fid); |
|
|
|
|
|
} |
|
|
|
|
|
return status; |
|
|
|
|
|
} |
|
|
|
|
|
|
|
|
|
|
|
// 注释:后台 GC 任务
|
|
|
|
|
|
void DBImpl::BackGroundGarbageCollection(){ |
|
|
|
|
|
uint64_t fid; |
|
|
|
|
|
uint64_t last_sequence; |
|
|
|
|
|
while( true){ |
|
|
|
|
|
Log(options_.info_log, "garbage collection file number: %lu", fid); |
|
|
|
|
|
if( !garbage_collection_management_->GetGarbageCollectionQueue(fid,last_sequence) ){ |
|
|
|
|
|
return; |
|
|
|
|
|
} |
|
|
|
|
|
// 在线的 gc 回收的 sequence 是要提前就分配好的。
|
|
|
|
|
|
CollectionValueLog(fid,last_sequence); |
|
|
|
|
|
} |
|
|
|
|
|
} |
|
|
|
|
|
|
|
|
|
|
|
// 注释:可能调度后台线程进行 GC
|
|
|
|
|
|
void DBImpl::MaybeScheduleGarbageCollection() { |
|
|
|
|
|
mutex_.AssertHeld(); |
|
|
|
|
|
if (background_GarbageCollection_scheduled_) { |
|
|
|
|
|
// Already scheduled
|
|
|
|
|
|
} else if (shutting_down_.load(std::memory_order_acquire)) { |
|
|
|
|
|
// DB is being deleted; no more background compactions
|
|
|
|
|
|
} else if (!bg_error_.ok()) { |
|
|
|
|
|
// Already got an error; no more changes
|
|
|
|
|
|
} else { |
|
|
|
|
|
// 设置调度变量,通过 detach 线程调度; detach 线程即使主线程退出,依然可以正常执行完成
|
|
|
|
|
|
background_GarbageCollection_scheduled_ = true; |
|
|
|
|
|
env_->ScheduleForGarbageCollection(&DBImpl::GarbageCollectionBGWork, this); |
|
|
|
|
|
} |
|
|
|
|
|
} |
|
|
|
|
|
|
|
|
|
|
|
// 注释:后台 gc 线程中执行的任务
|
|
|
|
|
|
void DBImpl::GarbageCollectionBGWork(void* db) { |
|
|
|
|
|
reinterpret_cast<DBImpl*>(db)->GarbageCollectionBackgroundCall(); |
|
|
|
|
|
} |
|
|
|
|
|
|
|
|
|
|
|
// 注释:后台 gc 线程执行
|
|
|
|
|
|
void DBImpl::GarbageCollectionBackgroundCall() { |
|
|
|
|
|
assert(background_GarbageCollection_scheduled_); |
|
|
|
|
|
if (shutting_down_.load(std::memory_order_acquire)) { |
|
|
|
|
|
// No more background work when shutting down.
|
|
|
|
|
|
} else if (!bg_error_.ok()) { |
|
|
|
|
|
// No more background work after a background error.
|
|
|
|
|
|
} else { |
|
|
|
|
|
BackGroundGarbageCollection(); |
|
|
|
|
|
} |
|
|
|
|
|
|
|
|
|
|
|
background_GarbageCollection_scheduled_ = false; |
|
|
|
|
|
// 再调用 MaybeScheduleGarbageCollection 检查是否需要再次调度
|
|
|
|
|
|
MaybeScheduleGarbageCollection(); |
|
|
|
|
|
garbage_collection_work_signal_.SignalAll(); |
|
|
|
|
|
} |
|
|
|
|
|
// end
|
|
|
|
|
|
|
|
|
void DBImpl::BGWork(void* db) { |
|
|
void DBImpl::BGWork(void* db) { |
|
|
reinterpret_cast<DBImpl*>(db)->BackgroundCall(); |
|
|
reinterpret_cast<DBImpl*>(db)->BackgroundCall(); |
|
|
} |
|
|
} |
|
|
@ -756,6 +1040,13 @@ void DBImpl::BackgroundCompaction() { |
|
|
if (!status.ok()) { |
|
|
if (!status.ok()) { |
|
|
RecordBackgroundError(status); |
|
|
RecordBackgroundError(status); |
|
|
} |
|
|
} |
|
|
|
|
|
// begin 注释: compact 后需要考虑是否将 vlog 文件进行 gc 回收,
|
|
|
|
|
|
// 如果需要则将其加入到 GC 任务队列中
|
|
|
|
|
|
// 不进行后台的 gc 回收,那么也不用更新待分配 sequence 的 vlog
|
|
|
|
|
|
if(!finish_back_garbage_collection_){ |
|
|
|
|
|
garbage_collection_management_->UpdateQueue(versions_->ImmLogFileNumber() ); |
|
|
|
|
|
} |
|
|
|
|
|
|
|
|
CleanupCompaction(compact); |
|
|
CleanupCompaction(compact); |
|
|
c->ReleaseInputs(); |
|
|
c->ReleaseInputs(); |
|
|
RemoveObsoleteFiles(); |
|
|
RemoveObsoleteFiles(); |
|
|
@ -1013,7 +1304,22 @@ Status DBImpl::DoCompactionWork(CompactionState* compact) { |
|
|
break; |
|
|
break; |
|
|
} |
|
|
} |
|
|
} |
|
|
} |
|
|
} |
|
|
|
|
|
|
|
|
} else { |
|
|
|
|
|
// begin 注释:drop 掉 LSM-tree 中的 kv 数值对了,
|
|
|
|
|
|
// 对属于 KV 分离的 kv 数值对进行 GC
|
|
|
|
|
|
Slice drop_value = input->value(); |
|
|
|
|
|
if( ikey.type == kTypeSeparation ){ |
|
|
|
|
|
uint64_t fid = 0; |
|
|
|
|
|
uint64_t offset = 0; |
|
|
|
|
|
uint64_t size = 0; |
|
|
|
|
|
GetVarint64(&drop_value,&fid); |
|
|
|
|
|
GetVarint64(&drop_value,&offset); |
|
|
|
|
|
GetVarint64(&drop_value,&size); |
|
|
|
|
|
mutex_.Lock(); |
|
|
|
|
|
garbage_collection_management_->UpdateMap(fid,size); |
|
|
|
|
|
mutex_.Unlock(); |
|
|
|
|
|
} |
|
|
|
|
|
} // end
|
|
|
|
|
|
|
|
|
input->Next(); |
|
|
input->Next(); |
|
|
} |
|
|
} |
|
|
@ -1117,6 +1423,68 @@ int64_t DBImpl::TEST_MaxNextLevelOverlappingBytes() { |
|
|
return versions_->MaxNextLevelOverlappingBytes(); |
|
|
return versions_->MaxNextLevelOverlappingBytes(); |
|
|
} |
|
|
} |
|
|
|
|
|
|
|
|
|
|
|
/* 从 VlogReader 读取的 VLog kv 数据对中解析出 value */ |
|
|
|
|
|
bool DBImpl::ParseVlogValue(Slice key_value, Slice key, |
|
|
|
|
|
std::string& value, uint64_t val_size) { |
|
|
|
|
|
Slice k_v = key_value; |
|
|
|
|
|
if (k_v[0] != kTypeSeparation) return false; |
|
|
|
|
|
k_v.remove_prefix(1); |
|
|
|
|
|
|
|
|
|
|
|
Slice vlog_key; |
|
|
|
|
|
Slice vlog_value; |
|
|
|
|
|
if (GetLengthPrefixedSlice(&k_v, &vlog_key) |
|
|
|
|
|
&& vlog_key == key |
|
|
|
|
|
&& GetLengthPrefixedSlice(&k_v, &vlog_value) |
|
|
|
|
|
&& vlog_value.size() == val_size) { |
|
|
|
|
|
value = vlog_value.ToString(); |
|
|
|
|
|
return true; |
|
|
|
|
|
} else { |
|
|
|
|
|
return false; |
|
|
|
|
|
} |
|
|
|
|
|
} |
|
|
|
|
|
|
|
|
|
|
|
Status DBImpl::GetLsm(const Slice& key, std::string* value) { |
|
|
|
|
|
MutexLock l(&mutex_); |
|
|
|
|
|
ReadOptions options; |
|
|
|
|
|
MemTable* mem = mem_; |
|
|
|
|
|
MemTable* imm = imm_; |
|
|
|
|
|
Version* current = versions_->current(); |
|
|
|
|
|
if( !this->snapshots_.empty() ){ |
|
|
|
|
|
options.snapshot = this->snapshots_.oldest(); |
|
|
|
|
|
} |
|
|
|
|
|
SequenceNumber snapshot; |
|
|
|
|
|
if (options.snapshot != nullptr) { |
|
|
|
|
|
snapshot = static_cast<const SnapshotImpl*>(options.snapshot)->sequence_number(); |
|
|
|
|
|
} else { |
|
|
|
|
|
snapshot = versions_->LastSequence(); |
|
|
|
|
|
} |
|
|
|
|
|
Status s; |
|
|
|
|
|
mem->Ref(); |
|
|
|
|
|
// imm 不一定存在,但是 mem 是一定存在的。
|
|
|
|
|
|
if (imm != nullptr) imm->Ref(); |
|
|
|
|
|
current->Ref(); // Version 读引用计数增一
|
|
|
|
|
|
Version::GetStats stats; |
|
|
|
|
|
// Unlock while reading from files and memtables
|
|
|
|
|
|
{ |
|
|
|
|
|
mutex_.Unlock(); |
|
|
|
|
|
// First look in the memtable, then in the immutable memtable (if any).
|
|
|
|
|
|
LookupKey lkey(key, snapshot); |
|
|
|
|
|
if (mem->Get(lkey, value, &s )) { |
|
|
|
|
|
// Done
|
|
|
|
|
|
} else if (imm != nullptr && imm->Get(lkey, value, &s)) { |
|
|
|
|
|
// Done
|
|
|
|
|
|
} else { |
|
|
|
|
|
//在Version中查找是否包含指定key值
|
|
|
|
|
|
s = current->Get(options, lkey, value, &stats); |
|
|
|
|
|
} |
|
|
|
|
|
mutex_.Lock(); |
|
|
|
|
|
} |
|
|
|
|
|
mem->Unref(); |
|
|
|
|
|
if (imm != nullptr) imm->Unref(); |
|
|
|
|
|
current->Unref(); //Version 读引用计数减一
|
|
|
|
|
|
return s; |
|
|
|
|
|
} |
|
|
|
|
|
|
|
|
Status DBImpl::Get(const ReadOptions& options, const Slice& key, |
|
|
Status DBImpl::Get(const ReadOptions& options, const Slice& key, |
|
|
std::string* value) { |
|
|
std::string* value) { |
|
|
Status s; |
|
|
Status s; |
|
|
@ -1161,6 +1529,56 @@ Status DBImpl::Get(const ReadOptions& options, const Slice& key, |
|
|
mem->Unref(); |
|
|
mem->Unref(); |
|
|
if (imm != nullptr) imm->Unref(); |
|
|
if (imm != nullptr) imm->Unref(); |
|
|
current->Unref(); |
|
|
current->Unref(); |
|
|
|
|
|
|
|
|
|
|
|
/* Vlog 读取 value */ |
|
|
|
|
|
if (s.ok() && s.IsSeparated()) { |
|
|
|
|
|
|
|
|
|
|
|
struct VlogReporter : public VlogReader::Reporter { |
|
|
|
|
|
Status* status; |
|
|
|
|
|
void Corruption(size_t bytes, const Status& s) override { |
|
|
|
|
|
if (this->status->ok()) *this->status = s; |
|
|
|
|
|
} |
|
|
|
|
|
}; |
|
|
|
|
|
|
|
|
|
|
|
VlogReporter reporter; |
|
|
|
|
|
Slice vlog_ptr(*value); |
|
|
|
|
|
uint64_t file_no; |
|
|
|
|
|
uint64_t offset; |
|
|
|
|
|
uint64_t val_size; |
|
|
|
|
|
size_t key_size = key.size(); |
|
|
|
|
|
|
|
|
|
|
|
/* 已知该 value 保存在 VLog,解码出 vlog_ptr(fid, offset, val_size)*/ |
|
|
|
|
|
GetVarint64(&vlog_ptr, &file_no); |
|
|
|
|
|
GetVarint64(&vlog_ptr, &offset); |
|
|
|
|
|
GetVarint64(&vlog_ptr, &val_size); |
|
|
|
|
|
|
|
|
|
|
|
/* VLog 内部 kv 对的编码长度,1B 为 type */ |
|
|
|
|
|
uint64_t encoded_len = 1 + VarintLength(key_size) + key.size() + VarintLength(val_size) + val_size; |
|
|
|
|
|
|
|
|
|
|
|
std::string fname = LogFileName(dbname_, file_no); |
|
|
|
|
|
RandomAccessFile* file; |
|
|
|
|
|
s = env_->NewRandomAccessFile(fname,&file); |
|
|
|
|
|
if (!s.ok()) { |
|
|
|
|
|
return s; |
|
|
|
|
|
} |
|
|
|
|
|
|
|
|
|
|
|
VlogReader vlogReader(file, &reporter); |
|
|
|
|
|
Slice key_value; |
|
|
|
|
|
char* scratch = new char[encoded_len]; |
|
|
|
|
|
|
|
|
|
|
|
if (vlogReader.ReadValue(offset, encoded_len, &key_value, scratch)) { |
|
|
|
|
|
value->clear(); |
|
|
|
|
|
if (!ParseVlogValue(key_value, key, *value, val_size)) { |
|
|
|
|
|
s = Status::Corruption("value in vlog isn't match with given key"); |
|
|
|
|
|
} |
|
|
|
|
|
} else { |
|
|
|
|
|
s = Status::Corruption("read vlog error"); |
|
|
|
|
|
} |
|
|
|
|
|
|
|
|
|
|
|
delete file; |
|
|
|
|
|
file = nullptr; |
|
|
|
|
|
} |
|
|
|
|
|
|
|
|
return s; |
|
|
return s; |
|
|
} |
|
|
} |
|
|
|
|
|
|
|
|
@ -1185,14 +1603,38 @@ void DBImpl::RecordReadSample(Slice key) { |
|
|
|
|
|
|
|
|
const Snapshot* DBImpl::GetSnapshot() { |
|
|
const Snapshot* DBImpl::GetSnapshot() { |
|
|
MutexLock l(&mutex_); |
|
|
MutexLock l(&mutex_); |
|
|
|
|
|
// begin 注释:建立快照,对快照之后的信息不用进行 GC
|
|
|
|
|
|
finish_back_garbage_collection_ = true; |
|
|
|
|
|
// end
|
|
|
return snapshots_.New(versions_->LastSequence()); |
|
|
return snapshots_.New(versions_->LastSequence()); |
|
|
} |
|
|
} |
|
|
|
|
|
|
|
|
void DBImpl::ReleaseSnapshot(const Snapshot* snapshot) { |
|
|
void DBImpl::ReleaseSnapshot(const Snapshot* snapshot) { |
|
|
MutexLock l(&mutex_); |
|
|
MutexLock l(&mutex_); |
|
|
snapshots_.Delete(static_cast<const SnapshotImpl*>(snapshot)); |
|
|
snapshots_.Delete(static_cast<const SnapshotImpl*>(snapshot)); |
|
|
|
|
|
// begin 注释:没有快照,重新进行后台 GC
|
|
|
|
|
|
if (snapshots_.empty()) { |
|
|
|
|
|
finish_back_garbage_collection_ = false; |
|
|
|
|
|
} |
|
|
|
|
|
// end
|
|
|
} |
|
|
} |
|
|
|
|
|
|
|
|
|
|
|
/*** DBImpl 类关于 Fields 类的 Put、Get 接口 ***/ |
|
|
|
|
|
Status DBImpl::PutFields(const WriteOptions& o, const Slice& key, const Fields& fields) { |
|
|
|
|
|
return DBImpl::Put(o, key, Slice(fields.SerializeValue())); |
|
|
|
|
|
} |
|
|
|
|
|
|
|
|
|
|
|
Status DBImpl::GetFields(const ReadOptions& o, const Slice& key, Fields& fields) { |
|
|
|
|
|
std::string value_str; |
|
|
|
|
|
|
|
|
|
|
|
Status s = DBImpl::Get(o, key, &value_str); |
|
|
|
|
|
if (!s.ok()) return s; |
|
|
|
|
|
|
|
|
|
|
|
fields = Fields::ParseValue(value_str); |
|
|
|
|
|
return Status::OK(); |
|
|
|
|
|
} |
|
|
|
|
|
/**************************************************/ |
|
|
|
|
|
|
|
|
// Convenience methods
|
|
|
// Convenience methods
|
|
|
Status DBImpl::Put(const WriteOptions& o, const Slice& key, const Slice& val) { |
|
|
Status DBImpl::Put(const WriteOptions& o, const Slice& key, const Slice& val) { |
|
|
return DB::Put(o, key, val); |
|
|
return DB::Put(o, key, val); |
|
|
@ -1221,10 +1663,30 @@ Status DBImpl::Write(const WriteOptions& options, WriteBatch* updates) { |
|
|
Status status = MakeRoomForWrite(updates == nullptr); |
|
|
Status status = MakeRoomForWrite(updates == nullptr); |
|
|
uint64_t last_sequence = versions_->LastSequence(); |
|
|
uint64_t last_sequence = versions_->LastSequence(); |
|
|
Writer* last_writer = &w; |
|
|
Writer* last_writer = &w; |
|
|
|
|
|
|
|
|
if (status.ok() && updates != nullptr) { // nullptr batch is for compactions
|
|
|
if (status.ok() && updates != nullptr) { // nullptr batch is for compactions
|
|
|
WriteBatch* write_batch = BuildBatchGroup(&last_writer); |
|
|
WriteBatch* write_batch = BuildBatchGroup(&last_writer); |
|
|
WriteBatchInternal::SetSequence(write_batch, last_sequence + 1); |
|
|
|
|
|
last_sequence += WriteBatchInternal::Count(write_batch); |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
// begin 注释:GC 流程中写回的 WriteBatch 在 CollectionValueLog 函数中已经设置好了
|
|
|
|
|
|
if (!write_batch->IsGarbageCollection()) { |
|
|
|
|
|
// 判断是否需要进行 GC
|
|
|
|
|
|
// 如需要,空出一块 sequence 区域, 触发 GC 将在 MakeRoomForWrite 里
|
|
|
|
|
|
// 先判断是否要进行 gc 后台回收
|
|
|
|
|
|
// 如果建立了快照,finish_back_garbage_collection_ 就为 true
|
|
|
|
|
|
// 此时不进行 sequence 分配
|
|
|
|
|
|
if (!finish_back_garbage_collection_ |
|
|
|
|
|
&& garbage_collection_management_->ConvertQueue(last_sequence)) { |
|
|
|
|
|
MaybeScheduleGarbageCollection(); |
|
|
|
|
|
} |
|
|
|
|
|
// SetSequence 在 write_batch 中写入本次的 sequence
|
|
|
|
|
|
WriteBatchInternal::SetSequence(write_batch, last_sequence + 1); |
|
|
|
|
|
last_sequence += WriteBatchInternal::Count(write_batch); |
|
|
|
|
|
} |
|
|
|
|
|
// 这里设置 last_sequence 是为了确保离线 GC 的时候,
|
|
|
|
|
|
// 在 map 存在的时候需要调用 ConvertQueue 给回收任务分配 sequence
|
|
|
|
|
|
versions_->SetLastSequence(last_sequence); |
|
|
|
|
|
vlog_kv_numbers_ += WriteBatchInternal::Count(write_batch); |
|
|
|
|
|
// end
|
|
|
|
|
|
|
|
|
// Add to log and apply to memtable. We can release the lock
|
|
|
// Add to log and apply to memtable. We can release the lock
|
|
|
// during this phase since &w is currently responsible for logging
|
|
|
// during this phase since &w is currently responsible for logging
|
|
|
@ -1232,7 +1694,11 @@ Status DBImpl::Write(const WriteOptions& options, WriteBatch* updates) { |
|
|
// into mem_.
|
|
|
// into mem_.
|
|
|
{ |
|
|
{ |
|
|
mutex_.Unlock(); |
|
|
mutex_.Unlock(); |
|
|
status = log_->AddRecord(WriteBatchInternal::Contents(write_batch)); |
|
|
|
|
|
|
|
|
// 先写入vlog再写入memtable
|
|
|
|
|
|
// 写vlog日志 offset 表示这个 write_batch 在vlog中的偏移地址。
|
|
|
|
|
|
uint64_t offset = 0; |
|
|
|
|
|
status = vlog_->AddRecord(WriteBatchInternal::Contents(write_batch),offset); |
|
|
|
|
|
// status = log_->AddRecord(WriteBatchInternal::Contents(write_batch));
|
|
|
bool sync_error = false; |
|
|
bool sync_error = false; |
|
|
if (status.ok() && options.sync) { |
|
|
if (status.ok() && options.sync) { |
|
|
status = logfile_->Sync(); |
|
|
status = logfile_->Sync(); |
|
|
@ -1241,7 +1707,7 @@ Status DBImpl::Write(const WriteOptions& options, WriteBatch* updates) { |
|
|
} |
|
|
} |
|
|
} |
|
|
} |
|
|
if (status.ok()) { |
|
|
if (status.ok()) { |
|
|
status = WriteBatchInternal::InsertInto(write_batch, mem_); |
|
|
|
|
|
|
|
|
status = WriteBatchInternal::InsertInto(write_batch, mem_, logfile_number_, offset); |
|
|
} |
|
|
} |
|
|
mutex_.Lock(); |
|
|
mutex_.Lock(); |
|
|
if (sync_error) { |
|
|
if (sync_error) { |
|
|
@ -1299,11 +1765,15 @@ WriteBatch* DBImpl::BuildBatchGroup(Writer** last_writer) { |
|
|
++iter; // Advance past "first"
|
|
|
++iter; // Advance past "first"
|
|
|
for (; iter != writers_.end(); ++iter) { |
|
|
for (; iter != writers_.end(); ++iter) { |
|
|
Writer* w = *iter; |
|
|
Writer* w = *iter; |
|
|
if (w->sync && !first->sync) { |
|
|
|
|
|
|
|
|
// begin 注释:写队列中如果遍历到是 gc 的 WriteBatch,停止合并
|
|
|
|
|
|
if (w->sync && !first->sync |
|
|
|
|
|
|| first->batch->IsGarbageCollection() |
|
|
|
|
|
|| w->batch->IsGarbageCollection()) { |
|
|
|
|
|
// 当前 Writer要求 Sync ,而第一个 Writer 不要求 Sync,两个磁盘写入策略不一致。不做合并操作
|
|
|
// Do not include a sync write into a batch handled by a non-sync write.
|
|
|
// Do not include a sync write into a batch handled by a non-sync write.
|
|
|
break; |
|
|
break; |
|
|
} |
|
|
} |
|
|
|
|
|
|
|
|
|
|
|
// end
|
|
|
if (w->batch != nullptr) { |
|
|
if (w->batch != nullptr) { |
|
|
size += WriteBatchInternal::ByteSize(w->batch); |
|
|
size += WriteBatchInternal::ByteSize(w->batch); |
|
|
if (size > max_size) { |
|
|
if (size > max_size) { |
|
|
@ -1332,6 +1802,23 @@ Status DBImpl::MakeRoomForWrite(bool force) { |
|
|
assert(!writers_.empty()); |
|
|
assert(!writers_.empty()); |
|
|
bool allow_delay = !force; |
|
|
bool allow_delay = !force; |
|
|
Status s; |
|
|
Status s; |
|
|
|
|
|
|
|
|
|
|
|
if (logfile_->GetSize() > options_.max_value_log_size) { |
|
|
|
|
|
uint64_t new_log_number = versions_->NewFileNumber(); |
|
|
|
|
|
WritableFile* lfile = nullptr; |
|
|
|
|
|
s = env_->NewWritableFile(LogFileName(dbname_, new_log_number), &lfile); |
|
|
|
|
|
if (!s.ok()) { |
|
|
|
|
|
versions_->ReuseFileNumber(new_log_number); |
|
|
|
|
|
} |
|
|
|
|
|
garbage_collection_management_->WriteFileMap(logfile_number_, vlog_kv_numbers_, logfile_->GetSize()); |
|
|
|
|
|
vlog_kv_numbers_ = 0; |
|
|
|
|
|
delete vlog_; |
|
|
|
|
|
delete logfile_; |
|
|
|
|
|
logfile_ = lfile; |
|
|
|
|
|
logfile_number_ = new_log_number; |
|
|
|
|
|
vlog_ = new log::VlogWriter(lfile); |
|
|
|
|
|
} |
|
|
|
|
|
|
|
|
while (true) { |
|
|
while (true) { |
|
|
if (!bg_error_.ok()) { |
|
|
if (!bg_error_.ok()) { |
|
|
// Yield previous error
|
|
|
// Yield previous error
|
|
|
@ -1365,33 +1852,9 @@ Status DBImpl::MakeRoomForWrite(bool force) { |
|
|
} else { |
|
|
} else { |
|
|
// Attempt to switch to a new memtable and trigger compaction of old
|
|
|
// Attempt to switch to a new memtable and trigger compaction of old
|
|
|
assert(versions_->PrevLogNumber() == 0); |
|
|
assert(versions_->PrevLogNumber() == 0); |
|
|
uint64_t new_log_number = versions_->NewFileNumber(); |
|
|
|
|
|
WritableFile* lfile = nullptr; |
|
|
|
|
|
s = env_->NewWritableFile(LogFileName(dbname_, new_log_number), &lfile); |
|
|
|
|
|
if (!s.ok()) { |
|
|
|
|
|
// Avoid chewing through file number space in a tight loop.
|
|
|
|
|
|
versions_->ReuseFileNumber(new_log_number); |
|
|
|
|
|
break; |
|
|
|
|
|
} |
|
|
|
|
|
|
|
|
|
|
|
delete log_; |
|
|
|
|
|
|
|
|
|
|
|
s = logfile_->Close(); |
|
|
|
|
|
if (!s.ok()) { |
|
|
|
|
|
// We may have lost some data written to the previous log file.
|
|
|
|
|
|
// Switch to the new log file anyway, but record as a background
|
|
|
|
|
|
// error so we do not attempt any more writes.
|
|
|
|
|
|
//
|
|
|
|
|
|
// We could perhaps attempt to save the memtable corresponding
|
|
|
|
|
|
// to log file and suppress the error if that works, but that
|
|
|
|
|
|
// would add more complexity in a critical code path.
|
|
|
|
|
|
RecordBackgroundError(s); |
|
|
|
|
|
} |
|
|
|
|
|
delete logfile_; |
|
|
|
|
|
|
|
|
mem_->SetLogFileNumber(logfile_number_); |
|
|
|
|
|
|
|
|
logfile_ = lfile; |
|
|
|
|
|
logfile_number_ = new_log_number; |
|
|
|
|
|
log_ = new log::Writer(lfile); |
|
|
|
|
|
imm_ = mem_; |
|
|
imm_ = mem_; |
|
|
has_imm_.store(true, std::memory_order_release); |
|
|
has_imm_.store(true, std::memory_order_release); |
|
|
mem_ = new MemTable(internal_comparator_); |
|
|
mem_ = new MemTable(internal_comparator_); |
|
|
@ -1486,7 +1949,7 @@ void DBImpl::GetApproximateSizes(const Range* range, int n, uint64_t* sizes) { |
|
|
// Default implementations of convenience methods that subclasses of DB
|
|
|
// Default implementations of convenience methods that subclasses of DB
|
|
|
// can call if they wish
|
|
|
// can call if they wish
|
|
|
Status DB::Put(const WriteOptions& opt, const Slice& key, const Slice& value) { |
|
|
Status DB::Put(const WriteOptions& opt, const Slice& key, const Slice& value) { |
|
|
WriteBatch batch; |
|
|
|
|
|
|
|
|
WriteBatch
batch(opt.separate_threshold); |
|
|
batch.Put(key, value); |
|
|
batch.Put(key, value); |
|
|
return Write(opt, &batch); |
|
|
return Write(opt, &batch); |
|
|
} |
|
|
} |
|
|
@ -1508,6 +1971,13 @@ Status DB::Open(const Options& options, const std::string& dbname, DB** dbptr) { |
|
|
// Recover handles create_if_missing, error_if_exists
|
|
|
// Recover handles create_if_missing, error_if_exists
|
|
|
bool save_manifest = false; |
|
|
bool save_manifest = false; |
|
|
Status s = impl->Recover(&edit, &save_manifest); |
|
|
Status s = impl->Recover(&edit, &save_manifest); |
|
|
|
|
|
|
|
|
|
|
|
// begin 注释: Recover 之后,获取所有 VLogs
|
|
|
|
|
|
std::vector<uint64_t> logs; |
|
|
|
|
|
s = impl->GetAllValueLog(dbname, logs); |
|
|
|
|
|
sort(logs.begin(),logs.end()); |
|
|
|
|
|
// end
|
|
|
|
|
|
|
|
|
if (s.ok() && impl->mem_ == nullptr) { |
|
|
if (s.ok() && impl->mem_ == nullptr) { |
|
|
// Create new log and a corresponding memtable.
|
|
|
// Create new log and a corresponding memtable.
|
|
|
uint64_t new_log_number = impl->versions_->NewFileNumber(); |
|
|
uint64_t new_log_number = impl->versions_->NewFileNumber(); |
|
|
@ -1518,7 +1988,7 @@ Status DB::Open(const Options& options, const std::string& dbname, DB** dbptr) { |
|
|
edit.SetLogNumber(new_log_number); |
|
|
edit.SetLogNumber(new_log_number); |
|
|
impl->logfile_ = lfile; |
|
|
impl->logfile_ = lfile; |
|
|
impl->logfile_number_ = new_log_number; |
|
|
impl->logfile_number_ = new_log_number; |
|
|
impl->log_ = new log::Writer(lfile); |
|
|
|
|
|
|
|
|
impl->vlog_ = new log::VlogWriter(lfile); |
|
|
impl->mem_ = new MemTable(impl->internal_comparator_); |
|
|
impl->mem_ = new MemTable(impl->internal_comparator_); |
|
|
impl->mem_->Ref(); |
|
|
impl->mem_->Ref(); |
|
|
} |
|
|
} |
|
|
@ -1526,12 +1996,38 @@ Status DB::Open(const Options& options, const std::string& dbname, DB** dbptr) { |
|
|
if (s.ok() && save_manifest) { |
|
|
if (s.ok() && save_manifest) { |
|
|
edit.SetPrevLogNumber(0); // No older logs needed after recovery.
|
|
|
edit.SetPrevLogNumber(0); // No older logs needed after recovery.
|
|
|
edit.SetLogNumber(impl->logfile_number_); |
|
|
edit.SetLogNumber(impl->logfile_number_); |
|
|
|
|
|
// s = impl->versions_->LogAndApply(&edit, &impl->mutex_);
|
|
|
|
|
|
// begin 注释:把 imm_last_sequence 设置到新的 manifest 当中,
|
|
|
|
|
|
// 即 RecoverLogFile 中判断上一次断电时的数据库状态的 imm -> sst 的情况,
|
|
|
|
|
|
// 表示一次成功的全盘恢复
|
|
|
|
|
|
impl->versions_->StartImmLastSequence(true); |
|
|
s = impl->versions_->LogAndApply(&edit, &impl->mutex_); |
|
|
s = impl->versions_->LogAndApply(&edit, &impl->mutex_); |
|
|
|
|
|
impl->versions_->StartImmLastSequence(false); |
|
|
|
|
|
// end
|
|
|
} |
|
|
} |
|
|
if (s.ok()) { |
|
|
if (s.ok()) { |
|
|
impl->RemoveObsoleteFiles(); |
|
|
impl->RemoveObsoleteFiles(); |
|
|
impl->MaybeScheduleCompaction(); |
|
|
impl->MaybeScheduleCompaction(); |
|
|
} |
|
|
} |
|
|
|
|
|
|
|
|
|
|
|
// begin 开始全盘回收
|
|
|
|
|
|
|
|
|
|
|
|
if (s.ok() && impl->options_.start_garbage_collection) { |
|
|
|
|
|
if( s.ok() ){ |
|
|
|
|
|
int size = logs.size(); |
|
|
|
|
|
for( int i = 0; i < size ; i++){ |
|
|
|
|
|
uint64_t fid = logs[i]; |
|
|
|
|
|
uint64_t next_sequence = impl->versions_->LastSequence() + 1; |
|
|
|
|
|
std::cout<<" collection file : "<<fid<<std::endl; |
|
|
|
|
|
impl->mutex_.Unlock(); |
|
|
|
|
|
Status stmp = impl->CollectionValueLog(fid, next_sequence); |
|
|
|
|
|
impl->mutex_.Lock(); |
|
|
|
|
|
if (!stmp.ok()) s = stmp; |
|
|
|
|
|
impl->versions_->SetLastSequence(next_sequence - 1); |
|
|
|
|
|
} |
|
|
|
|
|
} |
|
|
|
|
|
} |
|
|
|
|
|
// end
|
|
|
impl->mutex_.Unlock(); |
|
|
impl->mutex_.Unlock(); |
|
|
if (s.ok()) { |
|
|
if (s.ok()) { |
|
|
assert(impl->mem_ != nullptr); |
|
|
assert(impl->mem_ != nullptr); |
|
|
|

 VirgilZhu
VirgilZhu
 GUJIEJASON
GUJIEJASON
{kind=link}
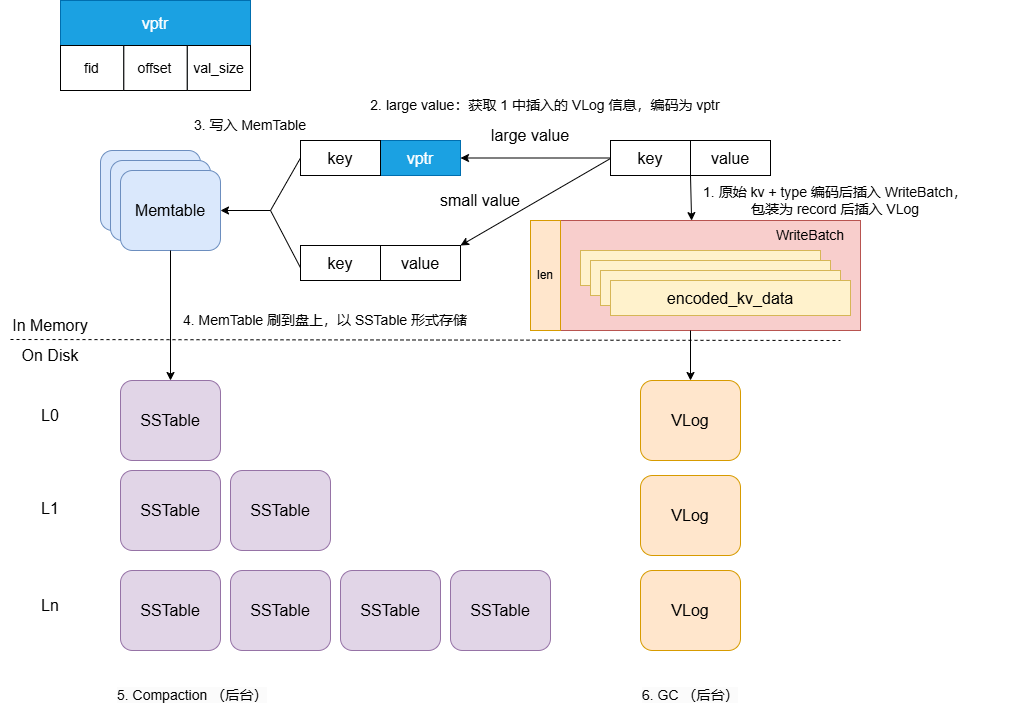
{kind=link}

{kind=link}
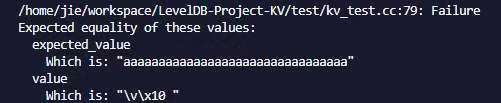
{kind=link}
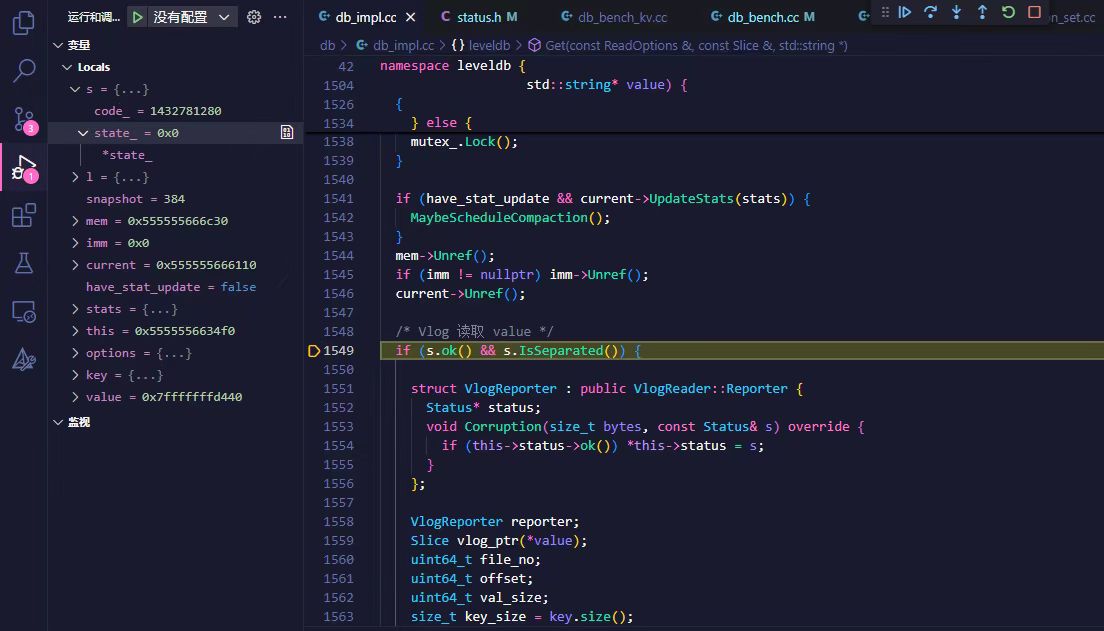
{kind=link}

{kind=link}
{kind=link}

{kind=link}
{kind=link}
{kind=link}