
You can not select more than 25 topics
Topics must start with a letter or number, can include dashes ('-') and can be up to 35 characters long.
6.5 KiB
6.5 KiB
Assignment 7 指南
******注意,实验结束请立即删除云主机、UFS文件存储和UAI Train交互式训练任务,节省费用******
******注意2,实验未结束且短期内不会继续实验,也请删除所有上述资源。下次实验时重新创建******
实验内容
- 创建文件存储:
实验步骤 一) - 创建云主机,并挂载文件存储:
实验步骤 二) - 创建UAI Train交互式训练任务,启动并切换成编辑模式:
实验步骤 三) - 使用交互式训练任务训练一个能够识别MNIST手写数字的神经网络:
实验步骤 四)
实验要求
- 完成所有步骤,并在实验报告(模板下载)中完成穿插在本指南中的作业1~作业4)。实验报告转成“学号-实验七.pdf”,并上传至http://113.31.104.68:3389/index.htm
- 实验报告上传deadline:
12月4日
使用UCloud产品
云主机UHost、文件存储UFS、镜像库UHub、AI训练UAI Train、私有网络VPC、基础网络UNet
需要权限
云主机UHost、文件存储UFS、镜像库UHub、AI训练UAI Train、基础网络UNet
基础知识
MNIST: MNIST是一个手写数字数据库,包含60000个训练样本和10000个测试样本,是一个能够快速上手的、用于尝试机器学习和模式识别技术的数据集。以下是部分MNIST中的样本。

实验步骤
一)创建一个文件存储
1)在产品->存储中选择“文件存储UFS”,然后点击创建文件系统。
2)如下图,存储类型选择SSD性能型,100GB,按时付费。
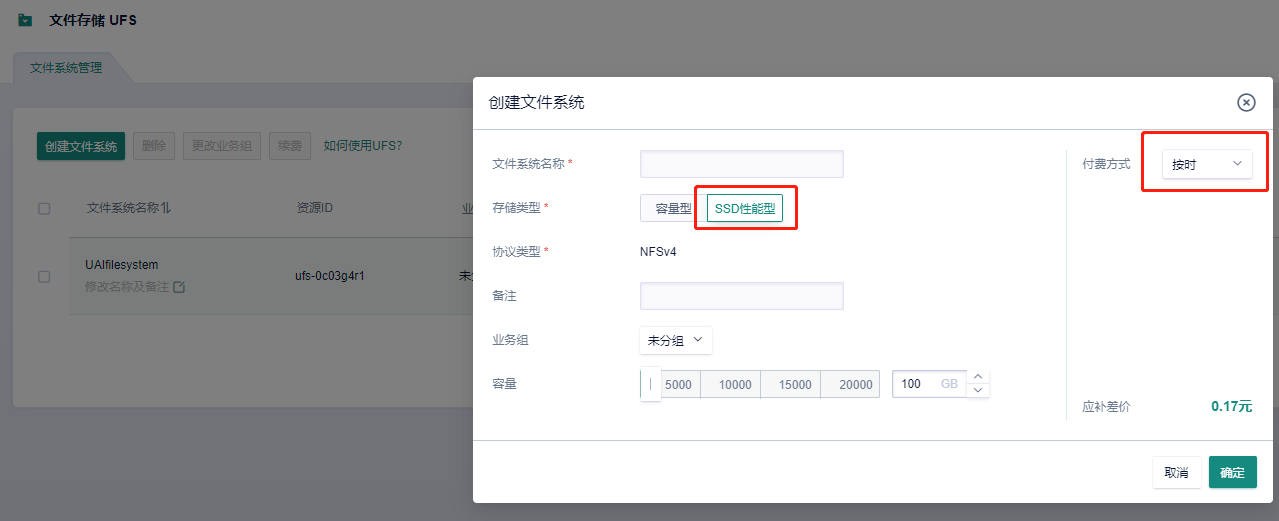
3)创建完毕后,点击添加挂载点,如下图所示选择一个VPC网络,使得相应的子网是DefaultNetwork,点击确定。这样我们等一下在DefaultNetwork下面创建一个云主机,就能把这个文件存储挂载到云主机上。
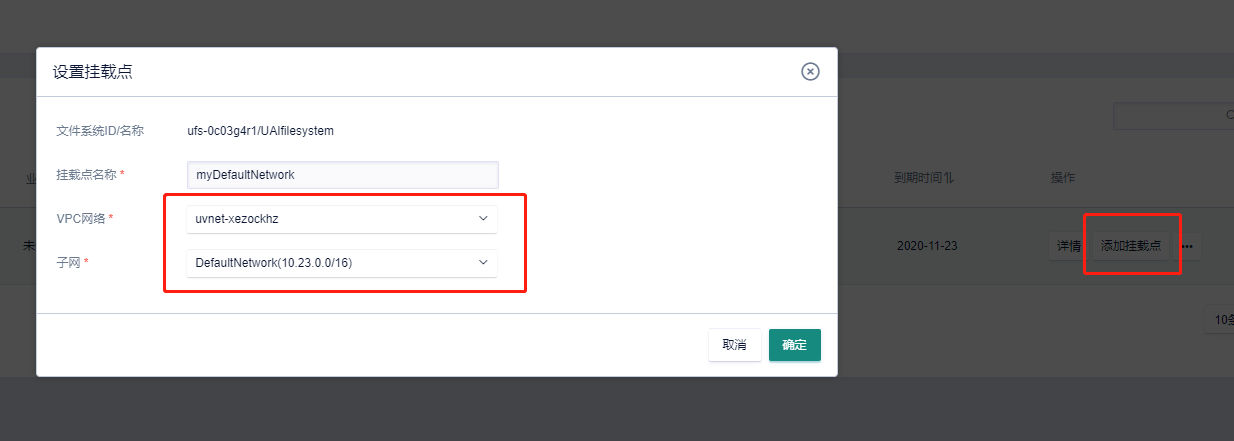
4)点击“管理挂载”,查看挂载信息,记住文件存储所在的ip地址

二)使用云主机创建Flask App服务实例,并连接负载均衡器。
1)创建一个1核1G的云主机,绑定弹性IP,选择web型防火墙,按时付费(已经很熟练了吧 🐶 🐶)
2)使用docker file创建一个Flask App的image(比如实验2中的hello world),并且暴露docker容器的5000端口(因为Flask开发模式默认端口就是5000)。创建完毕之后运行docker,将5000端口映射到云主机的80端口。
docker run -d --rm -p 80:5000 -name myflask luxuesong/myflaskapp
请同学们复习一下docker的安装和使用,以及通过dockerfile创建镜像。如果你意外保存了实验二的镜像,可以从镜像创建云主机,然后直接启动并docker run。
3)打开浏览器,输入 http://你的云主机外网ip,测试app是否正常运行。正常则进入下一步。

4)将云主机连到负载均衡器。回到前面添加服务节点的界面,输入端口80,则所有可添加的节点都会出现(以内网ip形式)。将你的云主机对应的内网ip,转移到待添加节点,点击确定。这时候显示健康检查“失败”,不用管它,我们在浏览器中输入 http://你的负载均衡器ip,奇迹发生了!我们也能访问flask app!!并且这时候健康检查也变成“正常”。
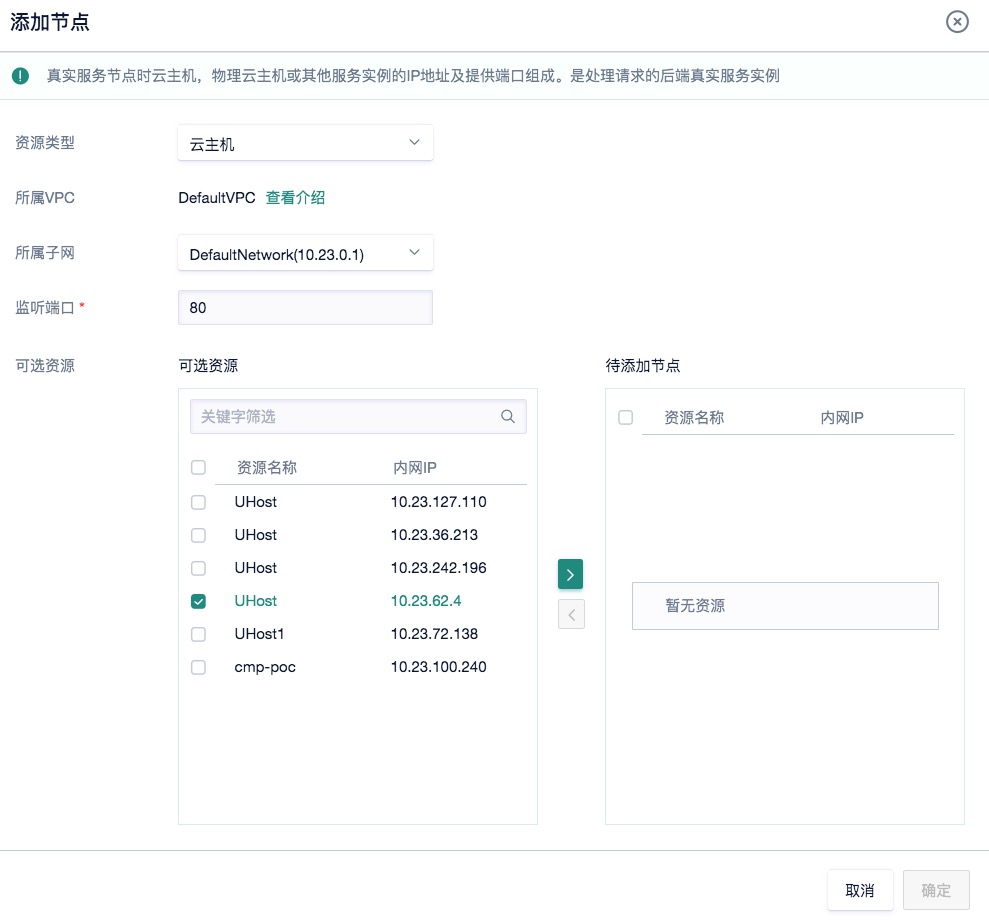
**************作业1:请将浏览器中通过负载均衡ip访问flask app的界面,以及负载均衡器中服务节点界面截图,并插入实验报告***************
5)此时负载均衡器只连接了一个服务实例,等同于单机访问。为步骤三做准备,请在这一步制作当前云主机的镜像。
三)使用ab进行http服务器压力测试
1)使用步骤二)中制作的镜像,创建三个最低配置的云主机(和之前一样,只是在云主机创建界面用“自制镜像”,并且不需要弹性ip),可以选择三台主机一次性创建

2)创建完毕后,使用有外网ip的那台云主机,逐个ssh到三台内网机器上(通过内网ip),然后每台机器直接启动docker服务,并运行flask app容器(因为已经全都安装并且build好了 😺 😺 😺)


3)现在让我们把这三个云主机连接到负载均衡器,并且从负载均衡器中删除刚才的具有外网ip的节点(接下来我们要用外网ip节点做压测)。首先我们禁用掉其中的两个节点,只保留一个节点在启用状态。如下图所示。
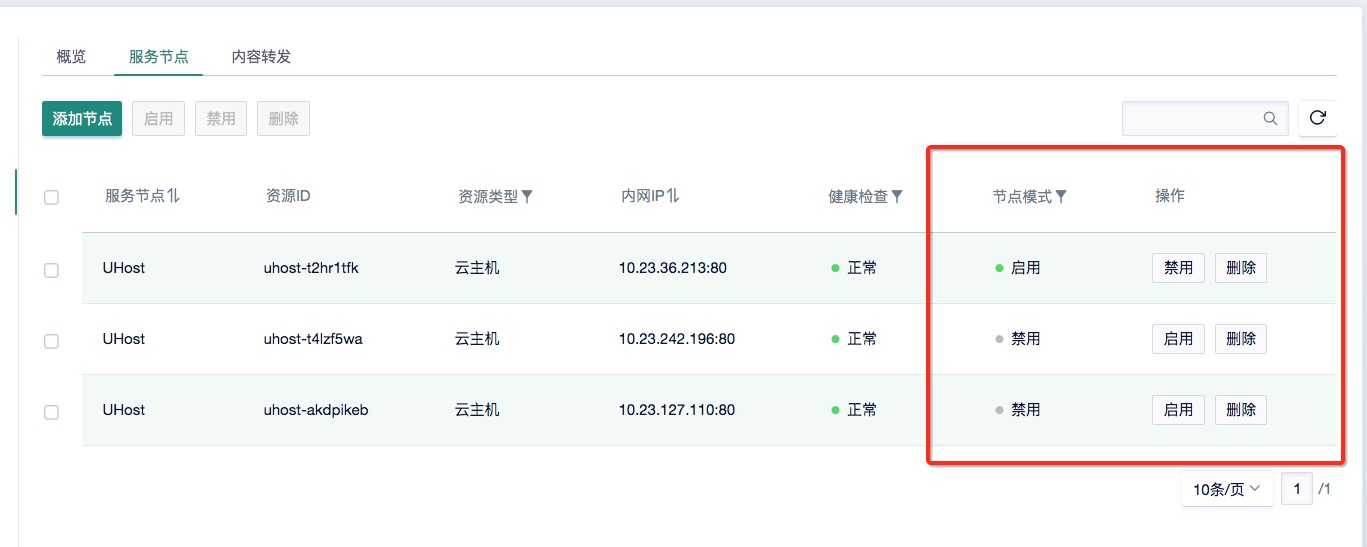
**************作业2:请将此时连接到负载均衡的服务节点(三个)截图,并插入实验报告***************
4)登录具有外网ip的云主机,安装ApacheBench
sudo yum -y install httpd
5)运行压测命令。-c表示并发数,即同时发生的请求数,-n表示请求总数,http://106.75.216.169/替换成你的负载均衡器ip。所以这里对我们的flask app并发1000个请求,总共发出10000个请求。结果如下图所示。
ab -c 1000 -n 10000 http://106.75.216.169/

这里我们关注几个重要结果
- Time taken for tests:压测总时间
- Requests per second: 平均每秒处理请求数
- Time per request: 平均每个请求处理时间
6)接下来,请逐渐启用第2和第3个服务器节点,然后再运行上面的压测命令。
**************作业3:请将启用一个节点、两个节点、三个节点时的压测结果分别截图,并插入实验报告***************
注意,由于有网络因素干扰,每个实验你可以多进行几次压测,得到比较正常的结果再截图。