|
|
|
@ -197,7 +197,7 @@ |
|
|
|
|
|
|
|
#### 统计词频 |
|
|
|
|
|
|
|
- 创建目录,并上传测试数据 |
|
|
|
- 创建目录,并上传测试数据(`所有操作在集群的master节点执行`) |
|
|
|
|
|
|
|
``` |
|
|
|
hadoop fs -mkdir /input |
|
|
|
@ -218,5 +218,15 @@ hadoop jar /home/hadoop/hadoop-examples.jar wordcount /input /output 如果/ou |
|
|
|
|
|
|
|
`**************作业4:统计/home/hadoop/etc/hadoop目录下所有文件的词频并截图,插入实验报告中***************` |
|
|
|
|
|
|
|
*<!--(还需设计单线程对比实验,待完成......)-->* |
|
|
|
#### WordCount 实现原理 |
|
|
|
|
|
|
|
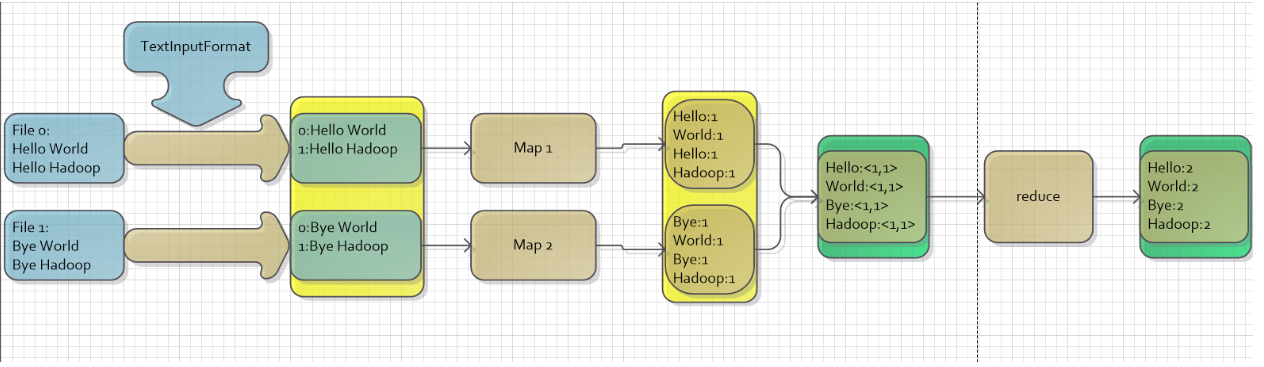
> MapReduce主要分为两步Map步和Reduce步,引用网上流传很广的一个故事来解释,现在你要统计一个图书馆里面有多少本书,为了完成这个任务,你可以指派小明去统计书架1,指派小红去统计书架2,这个指派的过程就是Map步,最后,每个人统计完属于自己负责的书架后,再对每个人的结果进行累加统计,这个过程就是Reduce步。下图是WordCount的实现原理图,[WordCount实现](https://hadoop.apache.org/docs/r1.0.4/cn/mapred_tutorial.html#用法)。 |
|
|
|
|
|
|
|
 |
|
|
|
|
|
|
|
`**************作业5:用任何语言实现单线程的wordcount,然后给出运行时间截图,插入实验报告中***************` |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
`******特别注意,实验结束后请删除UHadoop集群、EIP 和UHost主机******` |
|
|
|
|

 hxlong
4 年之前
hxlong
4 年之前
{kind=link}