|
|
|
@ -195,7 +195,7 @@ std::vector FindKeysByField(leveldb::DB* db, const Field& field) { |
|
|
|
|
|
|
|
##### 设计思路: |
|
|
|
1. value的分离式存储 |
|
|
|
我们使用若干个vlog文件,为每一个vlog文件设置容量上限(比如16MiB),并在内存中为每一个vlog维护一个discard计数器,表示这个vlog中当前有多少value已经在lsm tree中被标记为删除。 |
|
|
|
我们使用若干个vlog文件,为每一个vlog文件设置容量上限,并在内存中为每一个vlog维护一个discard计数器,表示这个vlog中当前有多少value已经在lsm tree中被标记为删除。 |
|
|
|
2. 存储value所在vlog和偏移量的元数据 |
|
|
|
我们在 memtable 和vlog中添加一个slot_page的中间层,这一层存储每一个key对应的value所在的vlog文件和文件内偏移,而lsm tree中的key包含的实际上是这个中间层的slot下标,而每一个slot中存储的是key所对应的vlog文件号以及value在vlog中的偏移。这样,我们就可以在不修改lsm tree的基础上,完成对vlog的compaction,并将vlog的gc结果只反映在这个中间层slot_page中。这个slot_page实际上也是一个线性增长的log文件,作用类似于os中的页表,负责维护lsm tree中存储的slot下标到vlog和vlog内偏移量的一个映射。这样,通过slot_page我们就可以找到具体的vlog文件和其文件内偏移量。对于vlog的GC过程,我们不需要修改lsm tree中的内容,我们只需要修改slot_page中的映射即可。 |
|
|
|
3. slot_page文件和vlog文件的GC |
|
|
|
@ -296,11 +296,6 @@ struct executor_param { |
|
|
|
- |
|
|
|
- [`CMakeLists.txt`](CMakeLists.txt):添加可执行文件 |
|
|
|
|
|
|
|
|
|
|
|
对于每一次读取,用户线程先读取lsm tree中key的slot_num下标,然后到slot_page中读取对应的slot内容(**每一个slot都是定长的**),之后再在这个slot中读取value所在的vlog文件号和偏移量offset,之后到对应的vlog文件中读取value。 |
|
|
|
|
|
|
|
但是这又带来了一个问题,我们该如何管理slot_page这个文件?当插入新的kv时,我们需要在这个slot_page中分配新的slot,在GC删除某个kv时,我们需要将对应的slot进行释放。这里我们选择在内存中维护一个可线性扩展的bitmap。这个bitmap中每一个bit标识了当前slot_page文件中对应slot是否被使用,是为1,不是为0。这样一来,在插入新kv时,我们可以用bitmap来分配一个新的slot(将bitmap中第一个为0的bit设置为1),将内容进行写入;在GC删除某个kv时,我们将这个slot对应的bitmap中的bit重置为0即可。 |
|
|
|
|
|
|
|
**数据结构设计:** |
|
|
|
|
|
|
|
`sstable 中:| key | slot_num | ` |
|
|
|
@ -743,40 +738,17 @@ void VlogSet::del_value(const struct slot_content &sc) { |
|
|
|
**功能:** 标记 slot_content 对应的条目为删除并判断是否需要调用 GC |
|
|
|
|
|
|
|
**实现步骤:** |
|
|
|
1. 获取日志信息:根据传入的槽内容(slot_content),获取对应的日志文件信息和名称 |
|
|
|
2. 读取并检查日志项:打开日志文件,读取指定偏移量的日志项数据,检查是否已被删除。如果已被删除,则直接返回 |
|
|
|
3. 标记删除:如果没有被删除,则设置删除标志位,并更新日志文件中的数据 |
|
|
|
4. 更新统计信息:增加丢弃计数,减少值的数量和当前大小 |
|
|
|
5. 触发垃圾回收:如果需要进行垃圾回收且未在处理中,则创建新的日志文件并启动垃圾回收过程 |
|
|
|
1. 根据 sc.vlog_num 获取 vlog 文件信息; |
|
|
|
2. 调用 delete_vlog_value 函数删除 vlog 中的条目,并返回被删除的日志项的大小; |
|
|
|
3. 更新信息; |
|
|
|
4. 判断是否需要 GC |
|
|
|
**具体实现如下:** |
|
|
|
```` |
|
|
|
void VlogSet::mark_del_value(const struct slot_content &sc) { |
|
|
|
// 根据 sc.vlog_num 获取 vlog 文件信息和名称 |
|
|
|
// 根据 sc.vlog_num 获取 vlog 文件信息 |
|
|
|
auto vinfo = get_vlog_info(sc.vlog_num); |
|
|
|
auto vlog_name = get_vlog_name(sc.vlog_num); |
|
|
|
// 打开日志文件并读取头部信息 |
|
|
|
auto handler = std::fstream(vlog_name, std::ios::in | std::ios::out); |
|
|
|
handler.seekp(sc.value_offset); |
|
|
|
char value_buff[VALUE_BUFF_SIZE]; |
|
|
|
handler.read(value_buff, VALUE_BUFF_SIZE); |
|
|
|
// 判断标志位是否为删除 |
|
|
|
uint16_t value_size; |
|
|
|
memcpy(&value_size, value_buff, sizeof(uint16_t)); |
|
|
|
if (value_size & VALUE_DELE_MASK) { |
|
|
|
// case when value has been deleted |
|
|
|
handler.close(); |
|
|
|
return ; |
|
|
|
} |
|
|
|
// 如果未被设置为删除,则设置删除标志位 |
|
|
|
assert(!(value_size & VALUE_DELE_MASK)); |
|
|
|
uint16_t masked_value_size = value_size | (uint16_t)VALUE_DELE_MASK; |
|
|
|
// 写回更新后的 value_size |
|
|
|
memcpy(value_buff, &masked_value_size, sizeof(uint16_t)); |
|
|
|
handler.seekp(sc.value_offset); |
|
|
|
handler.write(value_buff, sizeof(uint16_t)); |
|
|
|
handler.flush(); |
|
|
|
handler.close(); |
|
|
|
|
|
|
|
// 调用 delete_vlog_value 函数删除 vlog 中的条目,并返回被删除的项的大小 |
|
|
|
auto value_size = delete_vlog_value(sc); |
|
|
|
// handle gc, mtx is locked outside, vlog_info_latch and vlog hard lock is locked outside too |
|
|
|
// 更新统计信息,包括 增加丢弃计数 discard, 减少值的数量 value_nums, 减少当前大小 curr_size,减去被删除的日志项的大小 value_size |
|
|
|
vinfo->discard ++; |
|
|
|
@ -793,6 +765,185 @@ void VlogSet::mark_del_value(const struct slot_content &sc) { |
|
|
|
} |
|
|
|
} |
|
|
|
```` |
|
|
|
|
|
|
|
`void VlogGC::do_gc(size_t old_vlog_num, size_t new_vlog_num)` |
|
|
|
|
|
|
|
**功能:** 启动垃圾回收过程 |
|
|
|
|
|
|
|
**实现步骤:** |
|
|
|
|
|
|
|
1. 首先检查 old_vlog_num 是否正在进行GC,如果是则直接返回;否则将其标记为正在GC; |
|
|
|
2. 增加全局GC计数器,并获取当前的GC编号; |
|
|
|
3. 准备执行参数:创建一个结构体 executor_param,包含当前对象指针、旧日志编号和新日志编号; |
|
|
|
4. 添加执行参数和GC记录:将上述参数和当前对象添加到执行器参数列表和GC记录中; |
|
|
|
5. 启动GC线程:创建并启动一个独立线程来执行GC任务。该线程会调用exec_gc方法进行实际的GC操作,并在完成后减少全局GC计数器; |
|
|
|
6. 分离线程:将线程分离,使其独立运行。 |
|
|
|
|
|
|
|
**具体实现如下:** |
|
|
|
```` |
|
|
|
void VlogGC::do_gc(size_t old_vlog_num, size_t new_vlog_num) { |
|
|
|
// 判断old_vlog_num是否正在进行gc,如果是,直接返回 |
|
|
|
if (vlog_in_gc(old_vlog_num)) { |
|
|
|
return ; |
|
|
|
} |
|
|
|
// 否则将当前old_vlog_num设置为正在gc |
|
|
|
add_vlog_in_gc(old_vlog_num); |
|
|
|
// 增加全局GC计数器,并获取当前的GC编号 |
|
|
|
gc_counter_increment(); |
|
|
|
size_t _gc_num_ = get_gc_num(); |
|
|
|
// 创建一个结构体 executor_param,包含当前对象指针、旧日志编号和新日志编号 |
|
|
|
struct executor_param ep = {this, old_vlog_num, new_vlog_num}; |
|
|
|
add_executor_params(_gc_num_, ep); |
|
|
|
add_vlog_gc(_gc_num_, this); |
|
|
|
|
|
|
|
// FIXME: 线程的信息必须被保存在函数栈之外,否则函数栈销毁之后,线程会报错exc_bad_access, 这里需要有一个gc_hanlder线程一直运行并处理各个gc请求 |
|
|
|
std::thread gc_thread([_gc_num_, this]() mutable { |
|
|
|
auto _vlog_gc_ = get_vlog_gc(_gc_num_); |
|
|
|
assert(_vlog_gc_ != nullptr); |
|
|
|
_vlog_gc_->exec_gc(_gc_num_); |
|
|
|
gc_counter_decrement(); |
|
|
|
}); |
|
|
|
|
|
|
|
gc_thread.detach(); |
|
|
|
|
|
|
|
} |
|
|
|
```` |
|
|
|
|
|
|
|
`void VlogGC::exec_gc(size_t gc_num_)` |
|
|
|
|
|
|
|
**功能:** 执行GC任务 |
|
|
|
|
|
|
|
**实现步骤:** |
|
|
|
|
|
|
|
1. 增加当前线程数量,并判断是否需要等待其他线程完成GC任务; |
|
|
|
2. 获取执行参数,包括 GC编号、旧日志编号和新日志编号; |
|
|
|
3. 调用 gc_executor::exec_gc 方法开始执行GC任务; |
|
|
|
4. 检查当前线程数是否仍然大于等于最大线程数; |
|
|
|
5. 减少线程数; |
|
|
|
6. 清理资源。 |
|
|
|
**具体实现如下:** |
|
|
|
```` |
|
|
|
void VlogGC::exec_gc(size_t gc_num_) { |
|
|
|
// FIXME: might break, due to unknown concurrency problem |
|
|
|
// 线程数控制 |
|
|
|
curr_thread_nums_latch_.lock(); |
|
|
|
curr_thread_nums_ ++; |
|
|
|
if (curr_thread_nums_ >= max_thread_nums_) { |
|
|
|
full_latch_.lock(); |
|
|
|
} |
|
|
|
curr_thread_nums_latch_.unlock(); |
|
|
|
|
|
|
|
|
|
|
|
// start gc process |
|
|
|
auto ep = get_executor_params(gc_num_); |
|
|
|
gc_executor::exec_gc(ep.vg, ep.old_vlog_num, ep.new_vlog_num); |
|
|
|
// test_func(ep.vg, ep.old_vlog_num, ep.new_vlog_num); |
|
|
|
|
|
|
|
curr_thread_nums_latch_.lock(); |
|
|
|
if (curr_thread_nums_ >= max_thread_nums_) { |
|
|
|
full_latch_.unlock(); |
|
|
|
} |
|
|
|
curr_thread_nums_ --; |
|
|
|
curr_thread_nums_latch_.unlock(); |
|
|
|
|
|
|
|
// std::cout << "vlog_gc.cpp line 138" << std::endl; |
|
|
|
del_executor_params(gc_num_); |
|
|
|
// std::cout << "vlog_gc.cpp line 140" << std::endl; |
|
|
|
del_vlog_gc(gc_num_); |
|
|
|
// std::cout << "vlog_gc.cpp line 142" << std::endl; |
|
|
|
|
|
|
|
del_vlog_in_gc(ep.old_vlog_num); |
|
|
|
|
|
|
|
// FIXME: dead lock here (fixed, i think) |
|
|
|
// FIXME: remove vlog physically |
|
|
|
vlog_set->remove_old_vlog(ep.old_vlog_num); |
|
|
|
} |
|
|
|
```` |
|
|
|
|
|
|
|
`void gc_executor::exec_gc(VlogGC *vlog_gc_, size_t old_vlog_num, size_t new_vlog_num)` |
|
|
|
|
|
|
|
**功能:** 执行GC任务 |
|
|
|
|
|
|
|
**具体实现如下:** |
|
|
|
```` |
|
|
|
void gc_executor::exec_gc(VlogGC *vlog_gc_, size_t old_vlog_num, size_t new_vlog_num) { |
|
|
|
// 从 vlog_gc_ 对象中提取旧 vlog 和新 vlog 的相关信息,这些信息用于后续的操作 |
|
|
|
auto vlog_set = vlog_gc_->vlog_set; |
|
|
|
auto slot_page_ = vlog_gc_->slot_page_; |
|
|
|
// 锁定互斥锁 |
|
|
|
vlog_set->mtx.lock(); |
|
|
|
// 获取旧 vlog 和新 vlog 的信息 |
|
|
|
auto old_vlog_name = vlog_set->get_vlog_name(old_vlog_num); |
|
|
|
auto new_vlog_name = vlog_set->get_vlog_name(new_vlog_num); |
|
|
|
auto old_vlog_info = vlog_set->get_vlog_info(old_vlog_num); |
|
|
|
auto new_vlog_info = vlog_set->get_vlog_info(new_vlog_num); |
|
|
|
auto old_vlog_handler = vlog_set->get_vlog_handler(old_vlog_num); |
|
|
|
auto new_vlog_handler = vlog_set->get_vlog_handler(new_vlog_num); |
|
|
|
// 锁机制 |
|
|
|
old_vlog_info->vlog_info_latch_.lock(); |
|
|
|
old_vlog_handler->vlog_latch_.soft_lock(); |
|
|
|
new_vlog_info->vlog_info_latch_.lock(); |
|
|
|
new_vlog_handler->vlog_latch_.hard_lock(); |
|
|
|
vlog_set->mtx.unlock(); |
|
|
|
// 打开旧 vlog 和新 vlog 文件 |
|
|
|
auto old_vlog = std::fstream(old_vlog_name, std::ios::in | std::ios::out); |
|
|
|
auto new_vlog = std::fstream(new_vlog_name, std::ios::in | std::ios::out); |
|
|
|
|
|
|
|
// char old_vlog_buff[VLOG_SIZE]; |
|
|
|
// char new_vlog_buff[VLOG_SIZE]; |
|
|
|
// 动态分配内存用于存储旧 vlog 和新 vlog 的内容,可以在内存中高效地处理日志数据 |
|
|
|
char *old_vlog_buff = static_cast<char*>(malloc(VLOG_SIZE)); |
|
|
|
char *new_vlog_buff = static_cast<char*>(malloc(VLOG_SIZE)); |
|
|
|
// 读取旧日志文件内容 |
|
|
|
old_vlog.seekp(0); |
|
|
|
old_vlog.read(old_vlog_buff, VLOG_SIZE); |
|
|
|
// 初始化参数:初始化偏移量和新 vlog 中的条目计数,为遍历做准备 |
|
|
|
size_t value_nums = old_vlog_info->value_nums; |
|
|
|
size_t ovb_off = 2 * sizeof(size_t); |
|
|
|
size_t nvb_off = 2 * sizeof(size_t); |
|
|
|
size_t new_vlog_value_nums = 0; |
|
|
|
// 遍历旧 vlog 中的 value 并逐个处理 |
|
|
|
for (auto i = 0; i < value_nums; i++) { |
|
|
|
char *value = &old_vlog_buff[ovb_off]; |
|
|
|
uint16_t value_len = get_value_len(value); |
|
|
|
size_t slot_num = get_value_slotnum(value); |
|
|
|
// 如果当前 value 未被设置为删除,则将其复制到新 vlog 的缓冲区中,并更新相关参数 |
|
|
|
if (!value_deleted(value_len)) { |
|
|
|
memcpy(&new_vlog_buff[nvb_off], &old_vlog_buff[ovb_off], value_len); |
|
|
|
memcpy(&new_vlog_buff[nvb_off+sizeof(uint16_t)], &(new_vlog_info->vlog_num), sizeof(size_t)); |
|
|
|
struct slot_content scn(new_vlog_info->vlog_num, nvb_off); |
|
|
|
slot_page_->set_slot(slot_num, &scn); |
|
|
|
nvb_off += value_len; |
|
|
|
new_vlog_value_nums ++; |
|
|
|
} |
|
|
|
ovb_off += value_len; |
|
|
|
} |
|
|
|
// 更新新 vlog 信息, 包括条目数量和当前大小 |
|
|
|
new_vlog_info->value_nums = new_vlog_value_nums; |
|
|
|
new_vlog_info->curr_size = nvb_off; |
|
|
|
// 写入将新 vlog 缓冲区中的内容写入新 vlog 文件 |
|
|
|
memcpy(new_vlog_buff, &nvb_off, sizeof(size_t)); |
|
|
|
memcpy(&new_vlog_buff[sizeof(size_t)], &new_vlog_value_nums, sizeof(size_t)); |
|
|
|
new_vlog.seekp(0); |
|
|
|
new_vlog.write(new_vlog_buff, VLOG_SIZE); |
|
|
|
new_vlog.flush(); |
|
|
|
|
|
|
|
free(old_vlog_buff); |
|
|
|
free(new_vlog_buff); |
|
|
|
|
|
|
|
old_vlog.close(); |
|
|
|
new_vlog.close(); |
|
|
|
|
|
|
|
old_vlog_info->vlog_valid_ = false; |
|
|
|
|
|
|
|
old_vlog_info->vlog_info_latch_.unlock(); |
|
|
|
old_vlog_handler->vlog_latch_.soft_unlock(); |
|
|
|
new_vlog_info->vlog_info_latch_.unlock(); |
|
|
|
new_vlog_handler->vlog_latch_.hard_unlock(); |
|
|
|
|
|
|
|
// vlog_gc_->gc_counter_decrement(); |
|
|
|
} |
|
|
|
```` |
|
|
|
`void SlotPage::dealloc_slot(size_t slot_num)` |
|
|
|
**功能:** 释放 slot_num 中对应的 slot |
|
|
|
|
|
|
|
@ -830,6 +981,8 @@ void VlogSet::mark_del_value(const struct slot_content &sc) { |
|
|
|
6. 通过4中的字段值查询对应的 key,查找到的数目比4中少一个。 |
|
|
|
|
|
|
|
**测试代码:** |
|
|
|
|
|
|
|
代码文件为 [`/test/db_test3.cc`](./test/db_test3.cc) |
|
|
|
```` |
|
|
|
TEST(TestSchema, Basic) { |
|
|
|
DB* db; |
|
|
|
@ -901,25 +1054,79 @@ int main(int argc, char** argv) { |
|
|
|
**测试结果:** |
|
|
|
 |
|
|
|
### 3.2 测试并发插入和读取数据 |
|
|
|
### 3.3 测试 GC |
|
|
|
**测试流程:** |
|
|
|
创建 10 个线程,5 个线程为写线程,5 个线程为读线程,每个写线程写入 100 条数据,每个读线程读取 100 条数据。 |
|
|
|
|
|
|
|
代码文件为 [`/test/db_test6.cc`](./test/db_test6.cc) |
|
|
|
|
|
|
|
**测试结果:** |
|
|
|
 |
|
|
|
## 4. 性能测试: |
|
|
|
### 4.1 测试吞吐量和延迟 |
|
|
|
#### |
|
|
|
#### 测试内容: |
|
|
|
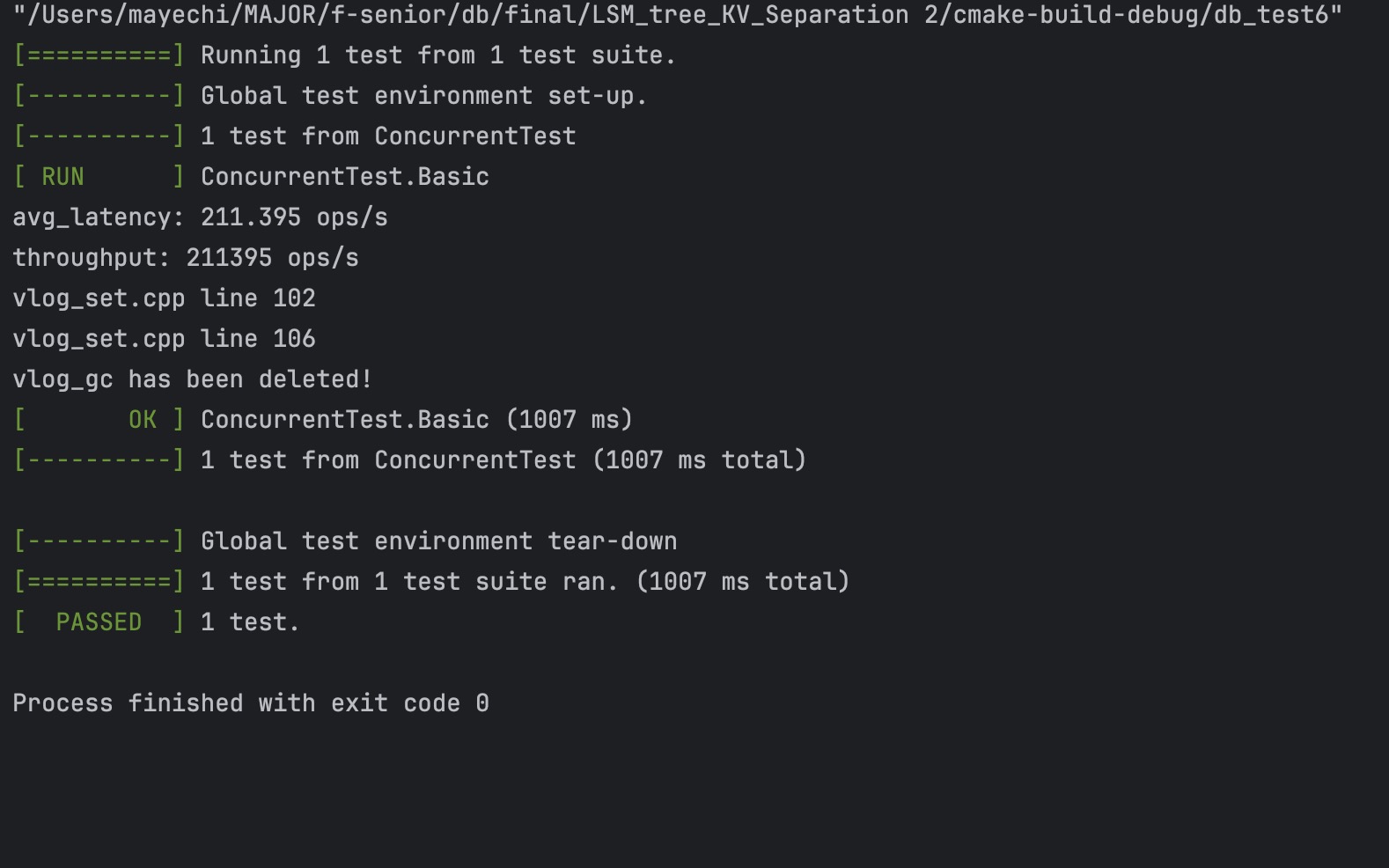
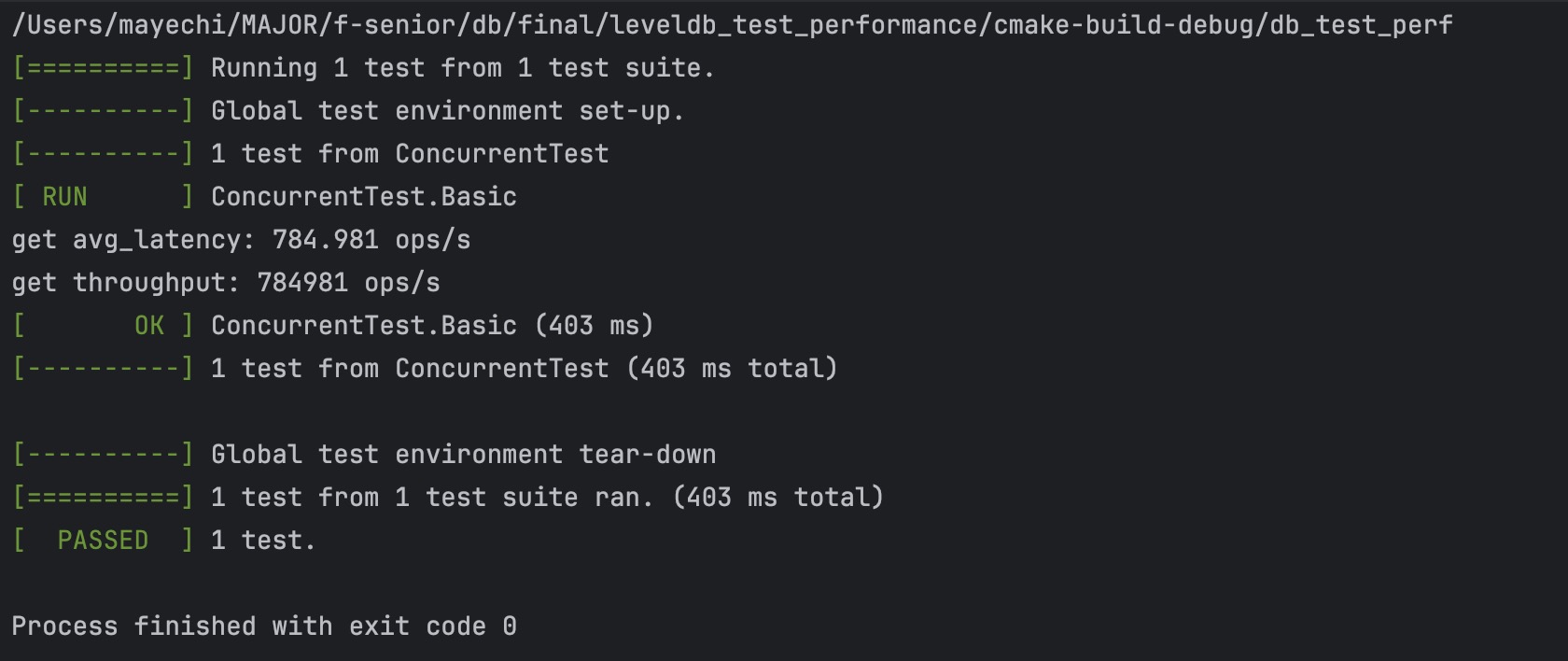
1. 并发,10个线程,全部读 |
|
|
|
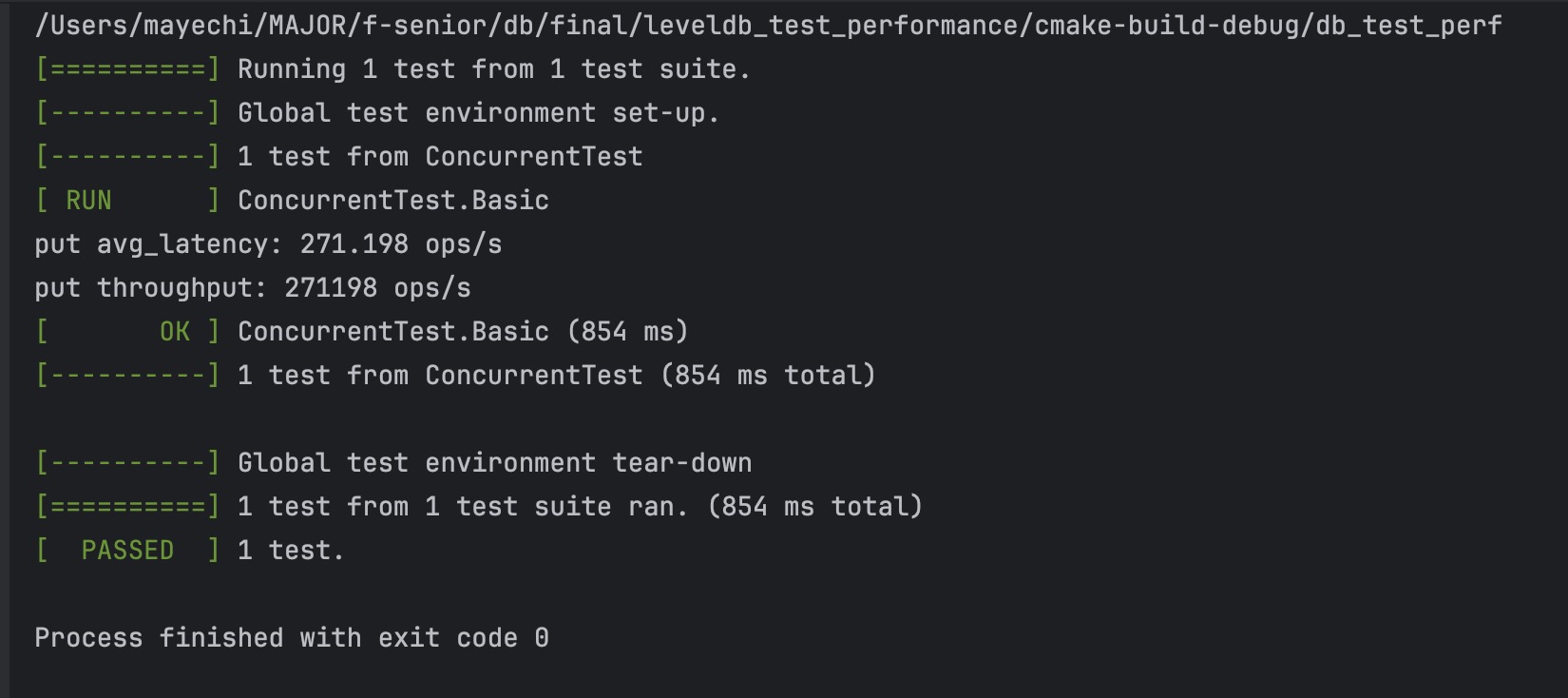
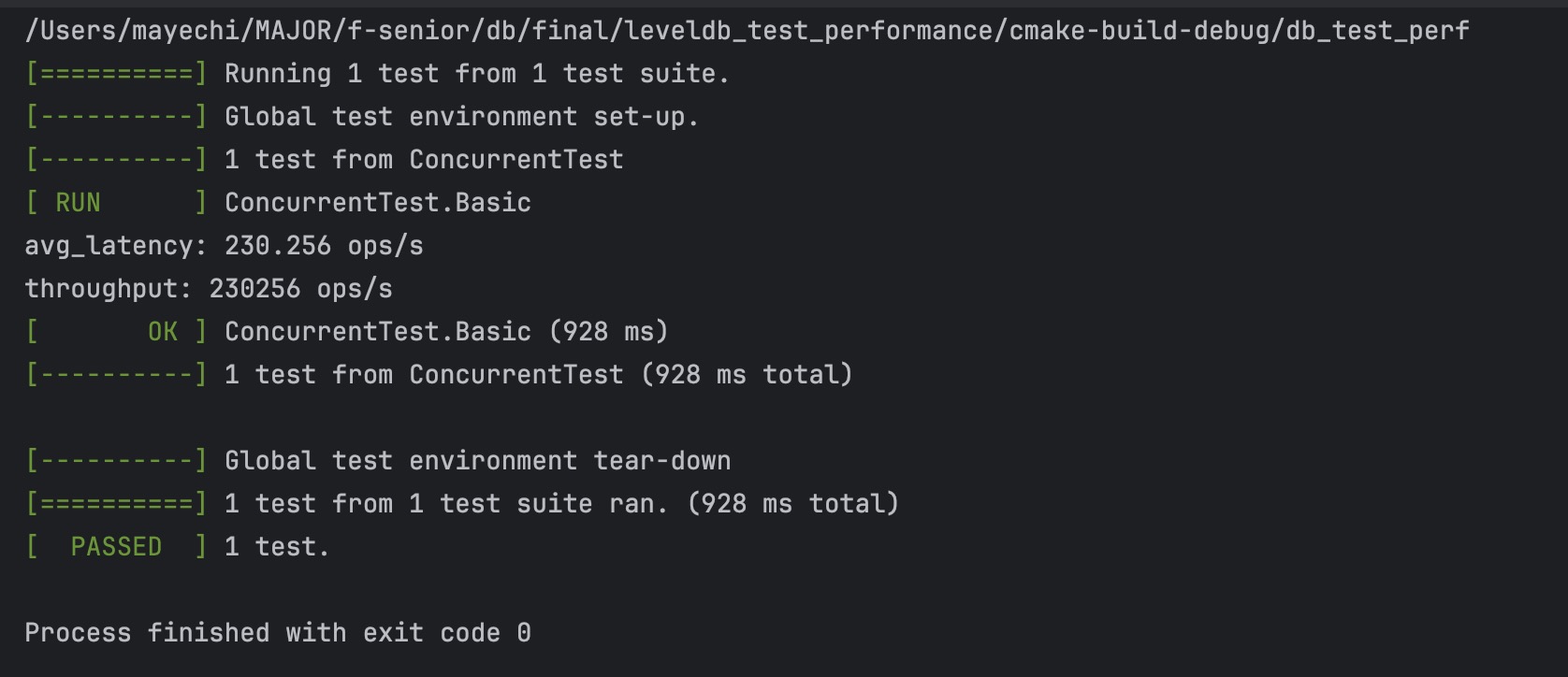
leveldb结果: |
|
|
|
 |
|
|
|
|
|
|
|
KV 分离结果: |
|
|
|
 |
|
|
|
|
|
|
|
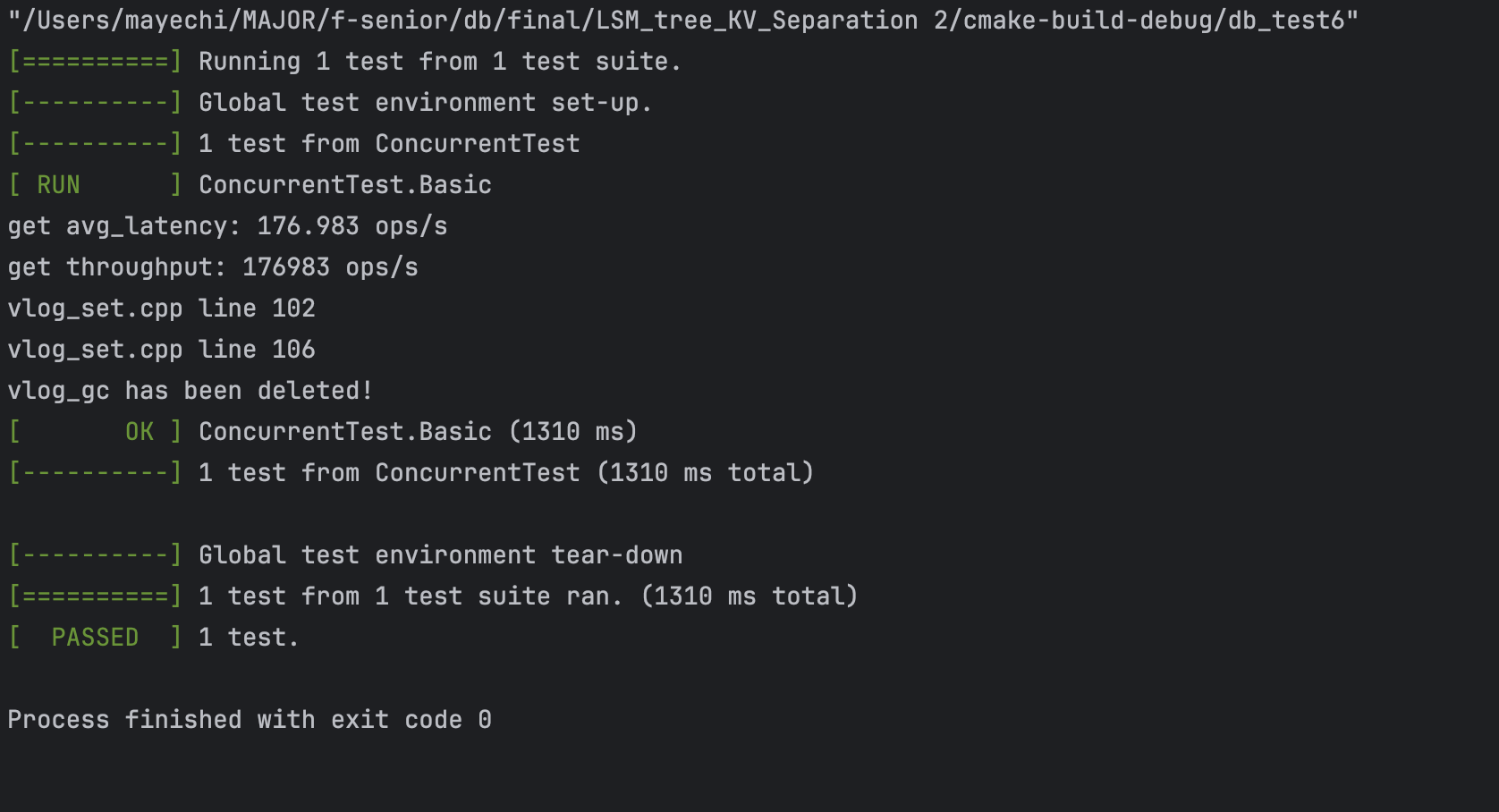
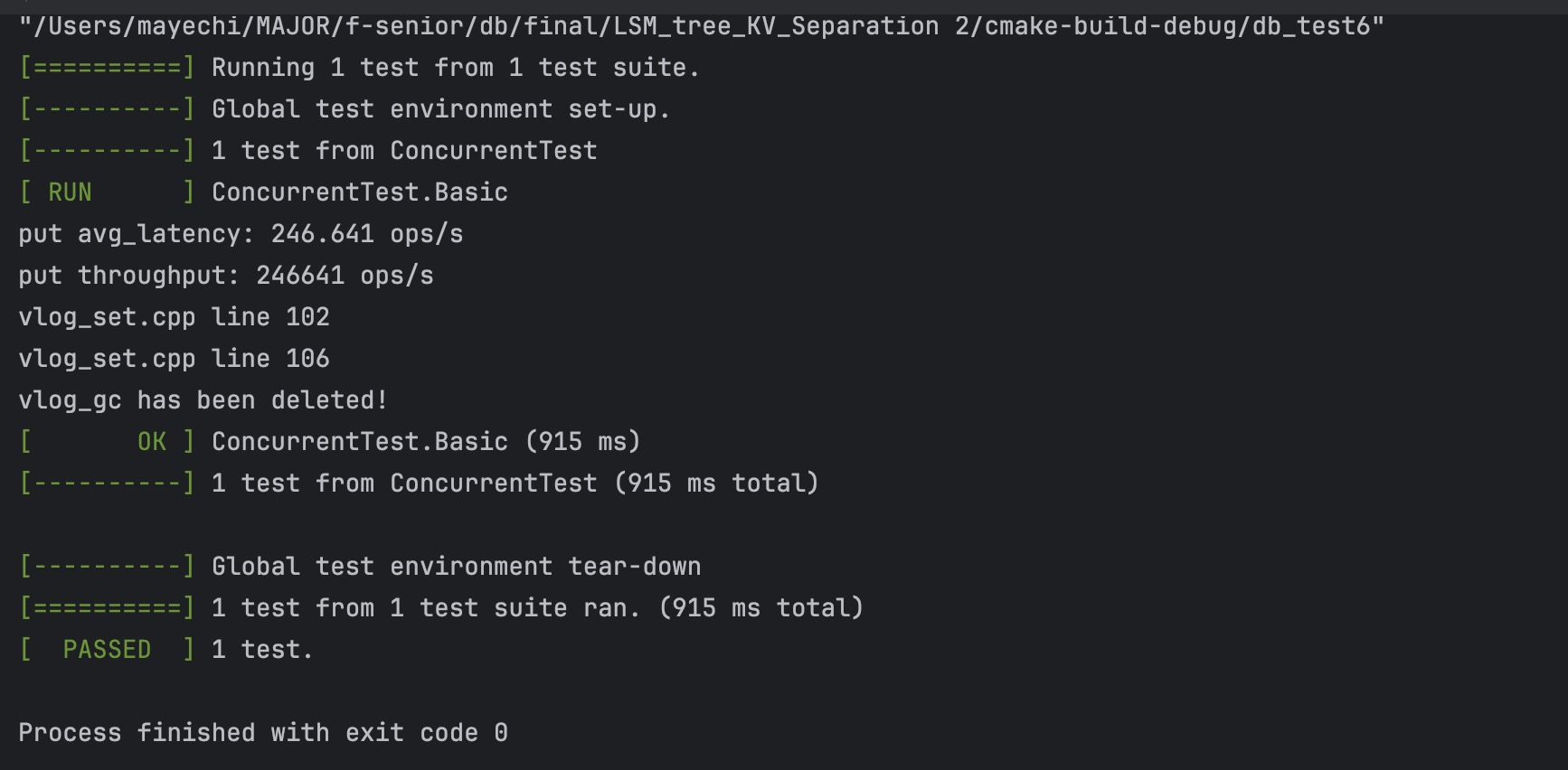
2. 并发,10个线程,全部写 |
|
|
|
|
|
|
|
leveldb结果: |
|
|
|
 |
|
|
|
|
|
|
|
KV 分离结果: |
|
|
|
 |
|
|
|
|
|
|
|
3. 并发,10个线程,一半读,一半写 |
|
|
|
|
|
|
|
leveldb结果: |
|
|
|
|
|
|
|
 |
|
|
|
|
|
|
|
KV 分离结果: |
|
|
|
|
|
|
|
 |
|
|
|
### 4.2 测试写放大 |
|
|
|
参数设置为: |
|
|
|
```` |
|
|
|
constexpr int value_size = 2048; |
|
|
|
constexpr int data_size = 512 << 20;` |
|
|
|
```` |
|
|
|
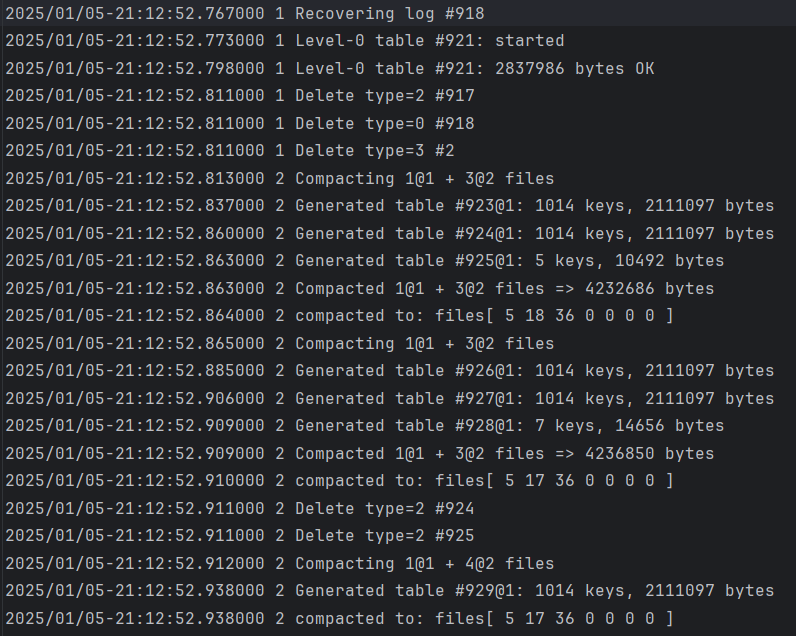
1. 初始版本的leveldb: |
|
|
|
|
|
|
|
CURRENT 内容为: MANIFEST-000920 |
|
|
|
|
|
|
|
写放大为:4232686 + 4236850 = 8465426 |
|
|
|
 |
|
|
|
|
|
|
|
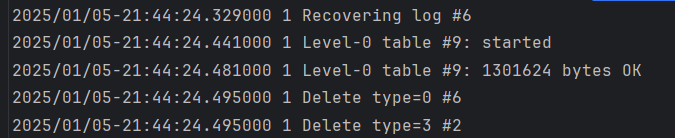
2. KV 分离版本: |
|
|
|
|
|
|
|
CURRENT 内容为: MANIFEST-000008 |
|
|
|
|
|
|
|
写放大为: |
|
|
|
 |
|
|
|
|
|
|
|
**总结:** |
|
|
|
虽然我们的 KV 分离实现与原本的 leveldb 相比读写性能提升不大,甚至有一定幅度的下降,但我们的实现能大幅度降低数据库的写放大。 |
|
|
|
### 5. 实验中遇到的问题和解决方案 |
|
|
|
### 6. 现有优化手段的分析与可能的优化 |
|
|
|
|
|
|
|
### 7. 分工和进度安排 |
|
|
|
|
|
|
|
| 功能 | 完成日期 | 分工 | |
|
|
|
|----------------------|-------|----------| |
|
|
|
| Field相关接口实现 | 12.8 | 王雪飞 | |
|
|
|
| value_log中value的存储格式 | 12.8 | 王雪飞 | |
|
|
|
| slot_page 相关接口 | 12.8 | 马也驰 | |
|
|
|
| slot_page实现 | 12.8 | 马也驰 | |
|
|
|
| 修改leveldb的接口实现字段功能 | 12.17 | 王雪飞 | |
|
|
|
| vlog的GC实现 | 12.29 | 马也驰 | |
|
|
|
| 性能测试 | 1.5 | 王雪飞, 马也驰 | |
|
|
|
| 功能测试 | 1.5 | 王雪飞, 马也驰 | |
|
|
|
1. 对于每一次读取,用户线程先读取lsm tree中key的slot_num下标,然后到slot_page中读取对应的slot内容(**每一个slot都是定长的**),之后再在这个slot中读取value所在的vlog文件号和偏移量offset,之后到对应的vlog文件中读取value。 但是这又带来了一个问题,我们该如何管理slot_page这个文件?当插入新的kv时,我们需要在这个slot_page中分配新的slot,在GC删除某个kv时,我们需要将对应的slot进行释放。 |
|
|
|
|
|
|
|
这里我们选择在内存中维护一个可线性扩展的bitmap。这个bitmap中每一个bit标识了当前slot_page文件中对应slot是否被使用,是为1,不是为0。这样一来,在插入新kv时,我们可以用bitmap来分配一个新的slot(将bitmap中第一个为0的bit设置为1),将内容进行写入;在GC删除某个kv时,我们将这个slot对应的bitmap中的bit重置为0即可。 |
|
|
|
2. KV 分离的最初版本,我们没有实现 vlog_cache,读写性能很差,于是我们就考虑能不能再实现一个 vlog_cache,来优化读写性能。 |
|
|
|
在经过尝试之后,发现确实能提高读写性能,我们便在原本的实现之上添加了 vlog_cache。 |
|
|
|
### 6. 分工和进度安排 |
|
|
|
|
|
|
|
| 功能 | 完成日期 | 分工 | |
|
|
|
|------------------------|-------|----------| |
|
|
|
| Field相关接口实现 | 12.8 | 王雪飞 | |
|
|
|
| value_log中value的存储格式 | 12.8 | 王雪飞 | |
|
|
|
| slot_page 相关接口 | 12.8 | 马也驰 | |
|
|
|
| slot_page 实现 | 12.8 | 马也驰 | |
|
|
|
| 修改leveldb的接口实现字段功能 | 12.17 | 王雪飞 | |
|
|
|
| vlog的GC实现 | 12.29 | 马也驰 | |
|
|
|
| vlog_cache 实现 | 12.29 | 马也驰 | |
|
|
|
| 性能测试 | 1.5 | 王雪飞, 马也驰 | |
|
|
|
| 功能测试 | 1.5 | 王雪飞, 马也驰 | |
|
|
|
| 写实验报告 | 1.5 | 王雪飞, 马也驰 | |


{kind=link}

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

{kind=link}
{kind=link}
{kind=link}
{kind=link}