

1 changed files with 211 additions and 0 deletions
Split View
Diff Options
-
+211 -0实验报告.md
+ 211
- 0
实验报告.md
View File
| @ -0,0 +1,211 @@ | |||
| # 总体设计 | |||
| 使用了 Segregated Fits 算法来管理内存。 | |||
| 将空闲块按照大小分成不同的类,并将每个类的空闲块用链表连接起来。 | |||
| 每个空闲块都有一个 header 和一个 footer,与 Implicit list 算法相同。 | |||
| 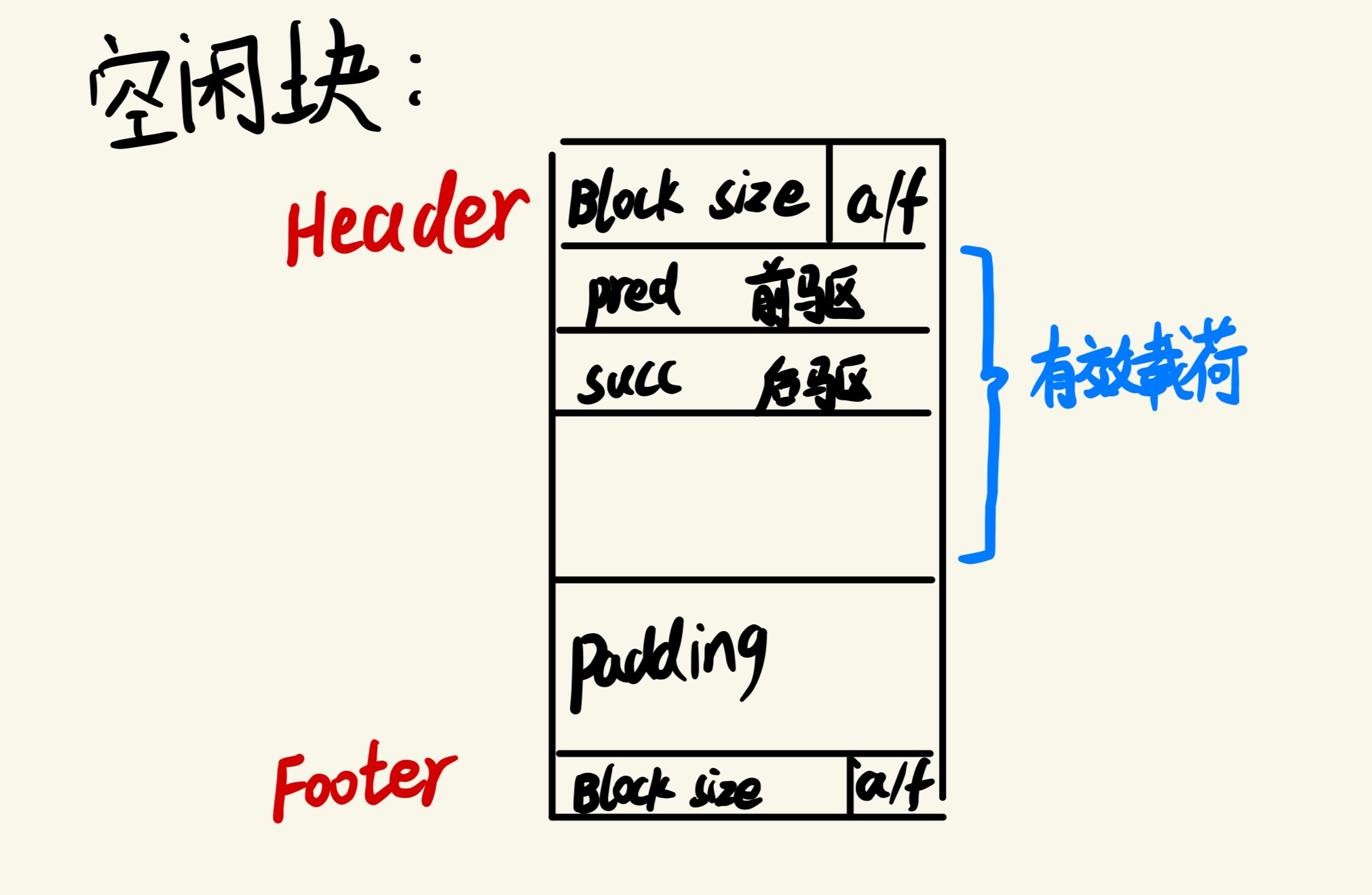 | |||
| 每个 free block 的第一个字保存指向 list 中下一个 free block 的指针,第二个字保存指向前一个 free block 的指针。 | |||
| 因此,每个 block 的最小值为 16 bytes,heap 地址的前 18 个字分别保存 18 个 list 的头指针,平衡了搜索时间和空间利用率. | |||
| 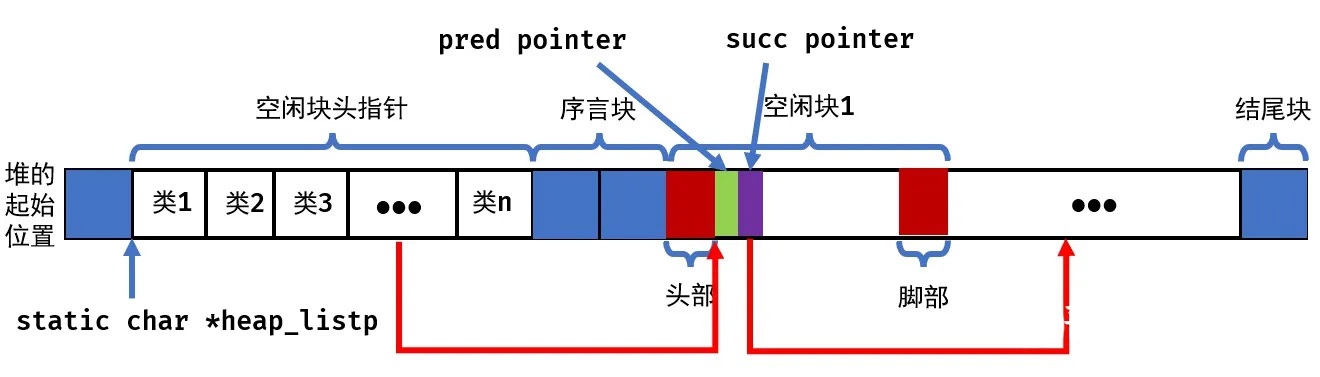 | |||
| ### 功能和算法 | |||
| - **空闲块链表**:将空闲块按照不同的大小类别分组管理,使用链表将相同大小的空闲块连接起来,方便查找合适大小的空闲块。 | |||
| - **合并相邻空闲块**:在释放内存块时,尝试合并相邻的空闲块,以便合理利用空间。 | |||
| - **扩展堆大小**:通过 `mem_sbrk` 来扩展堆的大小,以满足额外的内存需求。 | |||
| - **计算空闲块大小**:使用类似于分级的方式将不同大小的空闲块进行分组管理,便于快速查找合适大小的空闲块。 | |||
| ## 额外的函数设计 | |||
| ### extend_heap | |||
| 作用:扩展heap的大小 | |||
| 流程如下: | |||
| - 定义一个指针变量`bp`和一个大小变量`size`。 | |||
| - 根据参数`words`来计算需要分配的字节大小`size`。并且保证了`size`是一个偶数,以维持对齐。 | |||
| - 调用了一个函数`mem_sbrk`用于增加堆的大小。返回一个指向新分配的内存块的指针`bp`,如果分配失败,就返回-1。 | |||
| - 检查`bp`是否为-1,如果是,就返回`NULL`,表示扩展堆失败。 | |||
| - 调用函数`coalesce`,用于合并相邻的空闲内存块的函数,以减少内存碎片。并且返回一个指向合并后的内存块的指针。 | |||
| ### coalesce | |||
| 作用:合并free block | |||
| 根据前后相邻的内存块的分配状态,进行不同的操作 | |||
| 流程如下: | |||
| - 如果前后都分配了,那么不需要合并,直接返回原来的指针。 | |||
| - 如果前分配,后未分配,那么把后面的空闲块从空闲链表中删除,然后把当前块和后面的块合并成一个更大的块,更新它的头部和尾部的大小和分配位,然后返回当前块的指针。 | |||
| - 如果前未分配,后分配,那么把前面的空闲块从空闲链表中删除,然后把前面的块和当前的块合并成一个更大的块,更新它的头部和尾部的大小和分配位,然后返回前面的块的指针。 | |||
| - 如果前后都未分配,那么把前后的空闲块都从空闲链表中删除,然后把前后的块和当前的块合并成一个更大的块,更新它的头部和尾部的大小和分配位,然后返回前面的块的指针。 | |||
| 最后,把合并后的空闲块插入到空闲链表中,然后返回合并后的块的指针。 | |||
| ### getListOffset | |||
| 作用:得到大小为size的块应该在哪个list中 | |||
| 根据`size`的值,返回一个对应的列表的偏移量。列表的偏移量是一个整数,表示这个数据应该存储在哪个列表中 | |||
| 流程如下: | |||
| * 使用一系列的`if-else`语句,来判断`size`的范围。 | |||
| * 每个`if-else`语句都有一个常量`SIZE1`到`SIZE17`,表示不同的大小的阈值。如果`size`小于等于某个阈值,就返回相应的偏移量。 | |||
| ### insert_list | |||
| 作用:将free block插入到相应大小的free list中, 插入位置为表头 | |||
| 流程如下: | |||
| * 调用`getListOffset`函数,根据内存块的大小`size`,得到一个列表的偏移量`index`。 | |||
| * 使用宏定义的函数,如`GET_PTR`,`PUT_PTR`,`HDRP`等,来操作内存块的头部和指针域。 | |||
| * 如果`heap_listp + WSIZE * index`处的指针为空,表示这个列表还没有任何内存块,那么就将`bp`作为第一个内存块插入到这个列表中,并将它的前驱和后继指针都设为`NULL`。 | |||
| * 如果`heap_listp + WSIZE * index`处的指针不为空,表示这个列表已经有一些内存块,那么就将`bp`作为第一个内存块插入到这个列表的头部,并将它的后继指针指向原来的第一个内存块,同时将原来的第一个内存块的前驱指针指向`bp`。 | |||
| * 最后,将`heap_listp + WSIZE * index`处的指针更新为`bp`。 | |||
| ### delete_list | |||
| 作用:删除链表结点 | |||
| 流程如下: | |||
| 首先,获取结点的大小和位置的偏移量。然后,根据结点在链表中的位置,分为四种情况来处理: | |||
| - 如果结点的前后指针都是NULL,说明这个结点是链表中唯一的结点,那么就把heap_listp数组中对应的头尾指针都设为NULL,表示链表为空。 | |||
| - 如果结点的前指针是NULL,后指针不是NULL,说明这个结点是链表中最后一个结点,但不是唯一一个,那么就把结点的后指针所指向的结点的前指针设为NULL,表示这个结点已经不在链表中了。 | |||
| - 如果结点的前指针不是NULL,后指针是NULL,说明这个结点是链表中第一个结点,但不是唯一一个,那么就把`heap_listp`数组中对应的头指针设为结点的前指针,表示链表的头部移动了,然后把结点的前指针所指向的结点的后指针设为NULL,表示这个结点已经不在链表中了。 | |||
| - 如果结点的前后指针都不是NULL,说明这个结点是链表中的中间结点,那么就把结点的后指针所指向的结点的前指针设为结点的前指针,表示跳过了这个结点,然后把结点的前指针所指向的结点的后指针设为结点的后指针,表示跳过了这个结点。 | |||
| ### find_fit | |||
| 作用:寻找一个合适size的free list | |||
| 函数的具体逻辑如下: | |||
| - 调用一个函数`getListOffset`,根据`asize`的值来确定一个索引`index`,这个索引表示一个内存块的类别,也就是它的大小范围。 | |||
| - 进入一个循环,从`index`开始,一直到`17`为止 | |||
| - 在每次循环中,首先从一个全局变量`heap_listp`中获取一个指针`ptr`,这个指针指向当前类别的内存块链表的头部。 | |||
| - 进入另一个循环,沿着链表遍历所有的内存块,直到`ptr`为空为止。 | |||
| - 在每次遍历中,使用两个宏`HDRP`和`GET_SIZE`来获取当前内存块的头部和大小,然后判断是否满足`asize`的要求,如果是,就返回`ptr`作为结果。 | |||
| - 如果没有找到合适的内存块,就将`ptr`更新为下一个内存块的指针,这个指针是通过宏`GET_PTR`从当前内存块中获取的。 | |||
| - 如果遍历完当前类别的所有内存块,就将`index`加一,进入下一个类别的循环,直到找到合适的内存块或者遍历完所有的类别为止。 | |||
| - 如果最终没有找到合适的内存块,就返回`NULL`作为结果,表示失败。 | |||
| ### place | |||
| 作用:将一个空闲的内存块`bp`分割为两部分,一部分用于分配给用户,另一部分保持空闲 | |||
| 函数的具体逻辑如下: | |||
| - 调用函数`delete_list`,将`bp`从空闲链表中删除 | |||
| - 获取`bp`的当前大小`csize`,并判断是否可以将其分割为两个内存块,一个大小为`asize`,另一个大小为`csize - asize`。这里的条件是`csize - asize`必须大于等于`2 * DSIZE`,也就是最小的内存块大小。 | |||
| - 如果可以分割,就将`bp`的头部和尾部设置为`asize`和已分配的标志,然后将`bp`指向下一个内存块,将其头部和尾部设置为`csize - asize`和未分配的标志,最后将这个新的空闲内存块插入到空闲链表中,调用`insert_list`函数。 | |||
| - 如果不可以分割,就将`bp`的头部和尾部设置为`csize`和已分配的标志,不做其他操作。 | |||
| ## 四个主要函数实现过程 | |||
| ### mm_init | |||
| 1. **分配初始堆空间**: | |||
| - 调用 `mem_sbrk` 分配 `LISTS_NUM + 4` 个字(每个字是 4 字节),作为初始堆空间。 | |||
| - `LISTS_NUM` 是空闲块链表的数量。 | |||
| 2. **初始化空闲块链表**: | |||
| - 在初始化的堆空间中,初始化 `LISTS_NUM` 个空闲块链表头部,并将它们连接到堆的开头。 | |||
| - 每个链表头部是 4 字节的空间(因为用来存储指针),所以需要 `LISTS_NUM * WSIZE` 字节的空间。 | |||
| 3. **设置初始堆的结尾标志**: | |||
| - 设置堆的最后部分为结束标志,表示这是堆的结尾,没有更多可用空间。 | |||
| 4. **扩展堆空间**: | |||
| - 调用 `extend_heap` 函数,将堆的大小扩展为 `CHUNKSIZE` 字节。 | |||
| - `CHUNKSIZE` 是在没有足够空闲块的情况下,用来扩展堆空间的默认大小。 | |||
| ### mm_malloc | |||
| 1. **大小调整(Size Adjustment)**: | |||
| - 根据用户请求的大小,进行调整以满足内存对齐要求和额外的空间开销。在这个实现中,采用了最简单的方式:将请求的大小调整为双字大小的倍数,即 `asize = DSIZE * ((size + (DSIZE) + (DSIZE - 1)) / DSIZE)`。 | |||
| 2. **查找合适的空闲块(Find Fit)**: | |||
| - 在初始化的空闲块链表中查找一个大小合适的空闲块。 | |||
| - 调用 `find_fit` 函数,在空闲块链表中寻找第一个大小大于等于 `asize` 的空闲块。 | |||
| 3. **分配空闲块(Allocate Block)**: | |||
| - 如果找到了合适大小的空闲块,调用 `place` 函数来将其分配出去。 | |||
| - 如果没有找到合适的空闲块,则调用 `extend_heap` 来扩展堆空间,并在新的空间上分配内存块。 | |||
| 4. **返回分配的块地址(Return Allocated Block Address)**: | |||
| - 返回指向已分配内存块的指针。 | |||
| ### mm_free | |||
| 1. **标记内存块为可用状态**: | |||
| - 根据传入的指针 `ptr`,标记对应内存块的头部和尾部为未分配状态。 | |||
| - 这里使用 `PUT` 函数将头部和尾部的标志位设置为未分配状态。 | |||
| 2. **尝试合并相邻的空闲块**: | |||
| - 调用 `coalesce` 函数来尝试合并释放的块与相邻的空闲块。 | |||
| - `coalesce` 函数会检查前后相邻的块是否也是未分配的,如果是,则会合并这些块,以释放更多连续的空间。 | |||
| ### mm_realloc | |||
| 1. **处理零大小的请求**: | |||
| - 如果传入的大小为零,则直接释放先前分配的内存块,并返回 `NULL`。 | |||
| 2. **调整新内存块大小**: | |||
| - 根据传入的大小,重新计算新内存块的大小 `asize`,这个过程与 `mm_malloc` 中的大小调整类似。 | |||
| 3. **比较新旧块大小**: | |||
| - 检查新的大小是否等于旧的块大小,如果相等,则不需要进行任何操作,直接返回旧的块地址。 | |||
| 4. **缩小内存块**: | |||
| - 如果新的大小小于旧的块大小,尝试使用 `mm_malloc` 分配一个新块,并将旧块的内容复制到新块中。 | |||
| - 接着释放旧的块,并返回新分配的块地址。 | |||
| 5. **扩大内存块**: | |||
| - 如果新的大小大于旧的块大小,则分配一个新块。 | |||
| - 将旧块的内容复制到新块中,接着释放旧的块。 | |||
| - 返回新分配的块地址。 | |||
| ## 策略 | |||
| ### 放置策略 | |||
| 首次适配:在 `mm_malloc` 中,采用 `find_fit` 函数来在空闲块链表中寻找第一个合适大小的空闲块。这个函数会顺序查找链表,返回第一个大小满足需求的空闲块。 | |||
| ### 分割策略 | |||
| 立即分割:当找到的空闲块大小大于请求大小时,在 `place` 函数中会立即将其分割成两部分,一部分满足用户请求,剩余部分作为新的空闲块。 | |||
| ### 合并策略 | |||
| 基本合并策略:在 `coalesce`函数中实现了合并相邻的空闲块的逻辑。 | |||
| - 当释放一个块时,会检查其前后相邻的块是否也是未分配状态,如果是,则尝试合并这些块。 | |||
| - 根据前后相邻块的状态,有四种情况: | |||
| 1. 前后均已分配:不做任何合并。 | |||
| 2. 前分配,后未分配:合并当前块与后面的块。 | |||
| 3. 前未分配,后分配:合并前面的块与当前块。 | |||
| 4. 前后均未分配:合并前后两块与当前块 | |||
| ## 时间复杂度 | |||
| ### mm_malloc | |||
| - **时间复杂度**:O(n) | |||
| - **描述**:`mm_malloc` 函数中使用了首次适配策略,需要在空闲块链表中顺序查找第一个满足大小的空闲块。当链表中的空闲块数量增多时,查找所需的时间可能会线性增长。 | |||
| ### mm_free | |||
| - **时间复杂度**:O(1) | |||
| - **描述**:`mm_free` 函数内部主要涉及标记内存块为未分配状态,并尝试进行合并操作。这些操作的时间复杂度主要取决于标记和合并的步骤,而不会随着空闲块链表的大小增加而增加。 | |||
| ### mm_realloc | |||
| - **时间复杂度**:最坏情况下为 O(n) | |||
| - **描述**:`mm_realloc` 函数会在重新分配内存块时,根据新旧大小的比较来决定是缩小、扩大还是重新分配内存块。如果需要重新分配内存块,可能需要调用 `mm_malloc` 和 `mm_free` 函数,其中 `mm_malloc` 的时间复杂度是 O(n)。 | |||