
 ArcueidType
6c2151942a
ArcueidType
6c2151942a
|
10 maanden geleden | ||
|---|---|---|---|
| .github/workflows | 删除 | 2 jaren geleden | |
| Report | 删除 | 10 maanden geleden | |
| benchmarks | 删除 | 2 jaren geleden | |
| cmake | 删除 | 5 jaren geleden | |
| db | 删除 | 10 maanden geleden | |
| doc | 删除 | 3 jaren geleden | |
| helpers/memenv | 删除 | 3 jaren geleden | |
| img | 删除 | 10 maanden geleden | |
| include/leveldb | 删除 | 11 maanden geleden | |
| issues | 删除 | 3 jaren geleden | |
| port | 删除 | 2 jaren geleden | |
| table | 删除 | 2 jaren geleden | |
| test | 删除 | 10 maanden geleden | |
| third_party | 删除 | 2 jaren geleden | |
| util | 删除 | 10 maanden geleden | |
| .clang-format | 6 jaren geleden | ||
| .gitignore | 11 maanden geleden | ||
| .gitmodules | 4 jaren geleden | ||
| AUTHORS | 12 jaren geleden | ||
| CMakeLists.txt | 10 maanden geleden | ||
| CONTRIBUTING.md | 3 jaren geleden | ||
| LICENSE | 14 jaren geleden | ||
| NEWS | 14 jaren geleden | ||
| README.md | 10 maanden geleden | ||
| TODO | 13 jaren geleden | ||
README.md
在LevelDB中实现TTL功能
10225102463 李畅
10225101440 韩晨旭@ArcueidType
实验要求
-
在LevelDB中实现键值对的
TTL(Time-To-Live)功能,使得过期的数据在读取时自动失效,并在适当的时候被合并清理。 -
修改LevelDB的源码,实现对
TTL的支持,包括数据的写入、读取和过期数据的清理。 -
编写测试用例,验证
TTL功能的正确性和稳定性。
1. 设计思路和实现过程
1.1 设计思路
Phase 0
在LevelDB中实现TTL功能主要涉及数据的读、写、合并。
在写入数据时,TTL功能是个可选项。从代码层面来说,LevelDB数据的写入调用了Put函数接口:
// 假设增加一个新的Put接口,包含TTL参数, 单位(秒)
Status DB::Put(const WriteOptions& opt, const Slice& key,
const Slice& value, uint64_t ttl);
// 如果调用的是原本的Put接口,那么就不会失效
Status DB::Put(const WriteOptions& opt, const Slice& key,
const Slice& value);
这段代码中,如果存入TTL参数,则调用本实验中新实现的Put函数接口;否则直接调用原有的Put接口。
Phase 1
本小组的思路很简明:
- 直接将
TTL信息在写入阶段添加到原有的数据结构中 - 在读取和合并时从得到的数据中 解读 出其存储的
TTL信息,判断是否过期 - 在手动合并中对最后有文件的层(max_level_with_files)进行扫描,清除其中的过期数据
因此,接下来需要思考的是如何将TTL信息巧妙地存入LevelDB的数据结构中。
Phase 2
由于插入数据时调用的Put接口只有三个参数,其中opt是写入时的系统配置,实际插入的数据只有key/value,因此存储ttl信息时,最简单的方法就是存入key或value中。
在这样的方法中,可以调用原有的Put函数,将含义ttl信息的key/value数据存入数据库。
经过讨论后,本小组选择将ttl信息存入value中。
这样做的优缺点是:
-
优点:由于LevelDB在合并数据的过程中,需要根据
SSTable的key对数据进行有序化处理,将ttl信息存储在value中不会影响key的信息,因此对已有的合并过程不产生影响 -
缺点:在获取到
SSTable的key时,无法直接判断该文件是否因为ttl而成为过期数据,仍然需要读取对应的value才能判断,多了一步读取开销。但是,实际上在读取数据以及合并数据的过程中,其代码实际上都读取了对应SSTable中存储的value信息,因此获取ttl信息时必要的读取value过程并不是多余的,实际几乎不造成额外的读取开销影响
Phase 3
在确定插入数据时选用的方法后,读取和合并的操作只需要在获取数据文件的value后解读其包含的ttl信息,并判断是否过期就可以了。
1.2 实现过程
1.2.1 写入 Put
首先需要实现的是将ttl信息存入value的方法。Put中获取的ttl参数是该数据文件的生存时间(单位:秒)。本小组对此进行处理方法是通过ttl计算过期时间的时间戳,转码为字符串类型后存入value的最前部,并用|符号与原来的值分隔开。
对于不使用ttl的数据文件,存入0作为ttl,在读取数据时若读到0则表示不使用TTL功能。
将此功能封装为编码和解码文件过期时间(DeadLine)的函数,存储在/util/coding.h文件中:
inline std::string EncodeDeadLine(uint64_t ddl, const Slice& value) { // 存储ttl信息
return std::to_string(ddl) + "|" + value.ToString();
}
inline void DecodeDeadLineValue(std::string* value, uint64_t& ddl) { // 解读ttl信息
auto separator = value->find_first_of("|");
std::string ddl_str = value->substr(0, separator);
ddl = std::atoll(ddl_str.c_str());
*value = value->substr(separator + 1);
}
在写入数据调用Put接口时,分别启用EncodeDeadLine函数存储ttl信息:
// Default implementations of convenience methods that subclasses of DB
// can call if they wish
// TTL: Update TTL Encode
Status DB::Put(const WriteOptions& opt, const Slice& key, const Slice& value) { // 不使用TTL
WriteBatch batch;
batch.Put(key, EncodeDeadLine(0, value));
return Write(opt, &batch);
}
// TTL: Put methods for ttl
Status DB::Put(const WriteOptions& options, const Slice& key,
const Slice& value, uint64_t ttl) { // 使用TTL
WriteBatch batch;
auto dead_line = std::time(nullptr) + ttl; // 计算过期时间的时间戳
batch.Put(key, EncodeDeadLine(dead_line, value));
return Write(options, &batch);
}
1.2.2 读取 Get
LevelDB在读取数据时,调用Get接口,获取文件的key/value,因此只需要在Get函数中加入使用TTL功能的相关代码:
Status DBImpl::Get(const ReadOptions& options, const Slice& key,
std::string* value) {
(......)
// Unlock while reading from files and memtables
{
mutex_.Unlock();
// First look in the memtable, then in the immutable memtable (if any).
LookupKey lkey(key, snapshot);
if (mem->Get(lkey, value, &s)) {
// Done
} else if (imm != nullptr && imm->Get(lkey, value, &s)) {
// Done
} else {
s = current->Get(options, lkey, value, &stats);
have_stat_update = true;
}
// TTL: Get the true value and make sure the data is still living
if(!value->empty()) {
uint64_t dead_line;
DecodeDeadLineValue(value, dead_line);
if (dead_line != 0) {
// use TTL
if (std::time(nullptr) >= dead_line) {
// data expired
*value = "";
s = Status::NotFound("Data expired");
}
} else {
// TTL not set
}
}
mutex_.Lock();
}
(......)
}
若使用了TTL功能,则当文件过期时,返回NotFound("Data expired")的信息,即“数据已清除”。
注意:由于LevelDB对于数据的读取是只读ReadOnly的,因此只能返回NotFound的信息,而无法真正清理过期数据。
1.2.3 合并 Compaction
在合并的过程中,需要做到清理掉过期的数据,释放空间。
在大合并的过程中,需要调用DoCompactionWorks函数实现合并的操作,也是在这个过程中,LevelDB得以真正完成清理旧版本数据、已删除数据并释放空间的过程。
其实现逻辑是在该函数的过程中引入一个布尔变量drop,对于需要清理的数据设置drop为True,而需要保留的数据则是drop为False,最后根据drop的值清理过期数据,并将需要保留的数据合并写入新的SSTable。
因此,我们只需要在判断drop为True的条件中加入对过期时间(DeadLine)的判断就可以实现TTL功能的清理过期数据了:
Status DBImpl::DoCompactionWork(CompactionState* compact) {
(......)
while (input->Valid() && !shutting_down_.load(std::memory_order_acquire)) {
(......)
// Handle key/value, add to state, etc.
bool drop = false;
if (!ParseInternalKey(key, &ikey)) {
// Do not hide error keys
current_user_key.clear();
has_current_user_key = false;
last_sequence_for_key = kMaxSequenceNumber;
} else {
if (!has_current_user_key ||
user_comparator()->Compare(ikey.user_key, Slice(current_user_key)) !=
0) {
// First occurrence of this user key
current_user_key.assign(ikey.user_key.data(), ikey.user_key.size());
has_current_user_key = true;
last_sequence_for_key = kMaxSequenceNumber;
}
std::string value = input->value().ToString();
uint64_t ddl;
DecodeDeadLineValue(&value, ddl);
if (last_sequence_for_key <= compact->smallest_snapshot) {
(......)
} else if (ddl <= std::time(nullptr)) { // 根据ttl判断是否为过期数据
// TTL: data expired
drop = true;
}
last_sequence_for_key = ikey.sequence;
}
(......)
input->Next();
}
(......)
}
理论上,Compaction已经实现了合并中清除过期数据的功能,但由于原本leveldb是按照没有TTL功能的逻辑设计的,因此其对数据的清除并不完全,也会造成测试不通过。
LevelDB中Compaction的逻辑是选中特定层(level)合并,假设为level n。在level n中找目标文件SSTable A(假设该次触发的合并从文件A开始),并确定level n以及level n+1中与SSTable A包含的数据(key/value)有key发生重复(overlap)的所有文件,合并后产生新的SSTable B放入level n+1层中。
然而由DoCompactionWorks代码可知,不参与合并的文件即使过期了也无法被清理。
例如,level n+1层中有含有过期数据的SSTable C,但由于level n+1是最后一个含有文件的层,即使是CompactRange(nullptr, nullptr),对所有数据合并,其只将level n的所有文件与level n+1中与上层有重叠的文件合并,因此SSTable C不会被清理。
CompactRange(nullptr, nullptr)应该能够合并所有数据,也就是可以清除所有过期数据,而无法被清理的SSTable C明显是个例外,是个错误。
从代码层面看导致该错误的原因。原来的代码:
void DBImpl::CompactRange(const Slice* begin, const Slice* end) {
int max_level_with_files = 1;
{
MutexLock l(&mutex_);
Version* base = versions_->current();
for (int level = 1; level < config::kNumLevels; level++) {
if (base->OverlapInLevel(level, begin, end)) {
max_level_with_files = level;
}
}
}
TEST_CompactMemTable(); // TODO(sanjay): Skip if memtable does not overlap
for (int level = 0; level < max_level_with_files; level++) {
TEST_CompactRange(level, begin, end);
}
}
void DBImpl::TEST_CompactRange(int level, const Slice* begin,
const Slice* end) {
assert(level >= 0);
assert(level + 1 < config::kNumLevels);
(......)
}
这里注意两个数:config::kNumLevels和max_level_with_files:
-
config::kNumLevels:是LevelDB在启动时设定的数,表示总共使用的
level层数。默认值为7 -
max_level_with_files:表示含有
SSTable文件的最高层的编号。注意,这里的level编号是从0开始的,因此max_level_with_files理论最大值是config::kNumLevels - 1
可以看出与上述例子相符,对最后有文件的那一层不会进行全范围的合并,因此产生漏网之鱼,而最直接想到的解决办法就是让手动合并时也对这最后一层做一次全范围的合并,就可以清除所有的过期数据。
这样只需要让循环多走一层:
for (int level = 0; level < max_level_with_files + 1; level++) {
TEST_CompactRange(level, begin, end);
}
但是这种方法仍然存在两个问题:
-
最后有文件的一层(max_level_with_files)可能并没有达到合并的条件,也就是说其不应该被合并到下一层中,这也同样符合leveldb原本的逻辑,但是这样的做法会导致其合并至下一层。
-
当存储数据已经堆积到整个leveldb的最底层时(即已达到
kNumLevels),按照上述代码执行会导致致命错误并使数据库崩溃。
防止最底层的数据被合并的函数调用是唯一的解决办法,但是这个做法又回到了上一个问题,最底层的过期数据可能始终无法被完全清除。
1.2.4 合并的最终解决方案
为了完全解决这个问题并让CompactRange正常工作,我们提出了一个新的方案:
对于最后有文件的一层(即max_level_with_files),我们进行单独的处理,去除掉其中的过期数据,但不将其推向下一层。
实现上,去除一层(e.g. level n)中的过期数据,实际上等价于将level n与一个空的层合并,再将合并的结果输出回level n。
因此,我们可以直接利用leveldb中被我们修改过的合并功能(合并中drop过期数据)来实现清除一层中的过期数据。
CompactRange函数用于手动合并,对于leveldb的自动合并,我们并不需要强迫其清除其触碰不到的数据,因此只需要修改手动合并的部分
在实现上,引入参数is_last_level表示当前是否在处理max_level_with_files,如果是则按照上述逻辑清除该层过期数据,反之按照原本的合并正常进行
在结构体ManualCompaction和类Compaction中引入新的成员is_max_level:
struct ManualCompaction {
int level;
bool is_last_level; // TTL: Used to check if last level with files
bool done;
const InternalKey* begin; // null means beginning of key range
const InternalKey* end; // null means end of key range
InternalKey tmp_storage; // Used to keep track of compaction progress
};
class Compaction {
public:
(...)
bool is_last_level() const {return is_last_level_; }
(...)
private:
(...)
bool is_last_level_;
(...)
}
给方法TEST_CompactRange和VersionSet::CompactRange增加一个参数is_last_level,用来传递构造结构体ManualCompaction和类Compaction的相应值。
在CompactRange的上述循环中调用TEST_CompactRange时,会将is_last_level传给该方法
for (int level = 0; level < max_level_with_files + 1; level++) {
TEST_CompactRange(level, begin, end, level == max_level_with_files);
}
在清除当前层过期数据的操作中,compaction中的inputs[1]应该为空,因此在VersionSet::SetupOtherInputs方法中,跳过对inputs[1]的填写:
if (!c->is_last_level()) {
current_->GetOverlappingInputs(level + 1, &smallest, &largest,
&c->inputs_[1]);
AddBoundaryInputs(icmp_, current_->files_[level + 1], &c->inputs_[1]);
}
接下来我们要做的是让合并的结果输出到当前层level而不是level+1
需要修改两处:
- DBImpl::DoCompactionWork中,stats_应该add在当前level上
- DBImpl::InstallCompactionResults中,将结果写入当前level中
代码:
Status DBImpl::DoCompactionWork(CompactionState* compact) {
(...)
if (!compact->compaction->is_last_level()) {
stats_[compact->compaction->level() + 1].Add(stats);
} else {
// TTL: compaction for last level
stats_[compact->compaction->level()].Add(stats);
}
(...)
}
Status DBImpl::InstallCompactionResults(CompactionState* compact) {
(...)
if (!compact->compaction->is_last_level()) {
compact->compaction->edit()->AddFile(level + 1, out.number, out.file_size,
out.smallest, out.largest);
} else {
// TTL: outputs of last level compaction should be writen to last level itself
compact->compaction->edit()->AddFile(level, out.number, out.file_size,
out.smallest, out.largest);
}
(...)
}
通过以上修改后即解决了CompactRange的问题,使其能够正常工作
2. 测试用例和测试结果
TestTTL.ReadTTL
TestTTL中第一个测试样例,检测插入和读取数据时,读取过期数据能够正确返回NotFound。

TestTTL.CompactionTTL
TestTTL中第二个测试样例,检测插入和合并数据,能够在手动触发所有数据的合并时清除所有过期数据。

TestTTL.LastLevelCompaction
在解决了上面遇到的问题之后,本小组添加了一个测试样例,用来检测在含义SSTable的最底层能否正确合并、清理过期数据。
在该样例中将kNumLevels设置为3可以保证(同时Assert确认正确性)最后一层中存在数据,我们的实现仍然可以通过测试:
main分支中为原始配置,即kNumLevels = 7, 其层数过大,导致要测试最底层含有数据非常耗时,因此我们在其他分支中提供了kNumLevels = 3配置的实现用于测试
light_ver分支:正确的合并实现,能通过测试
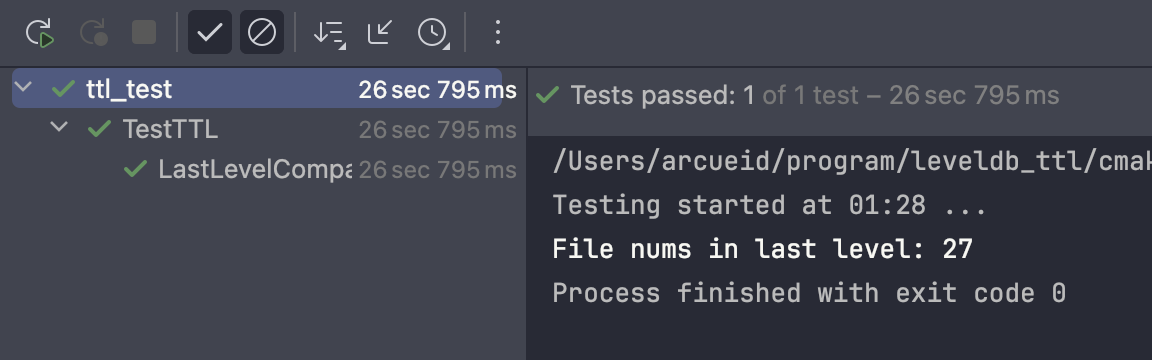
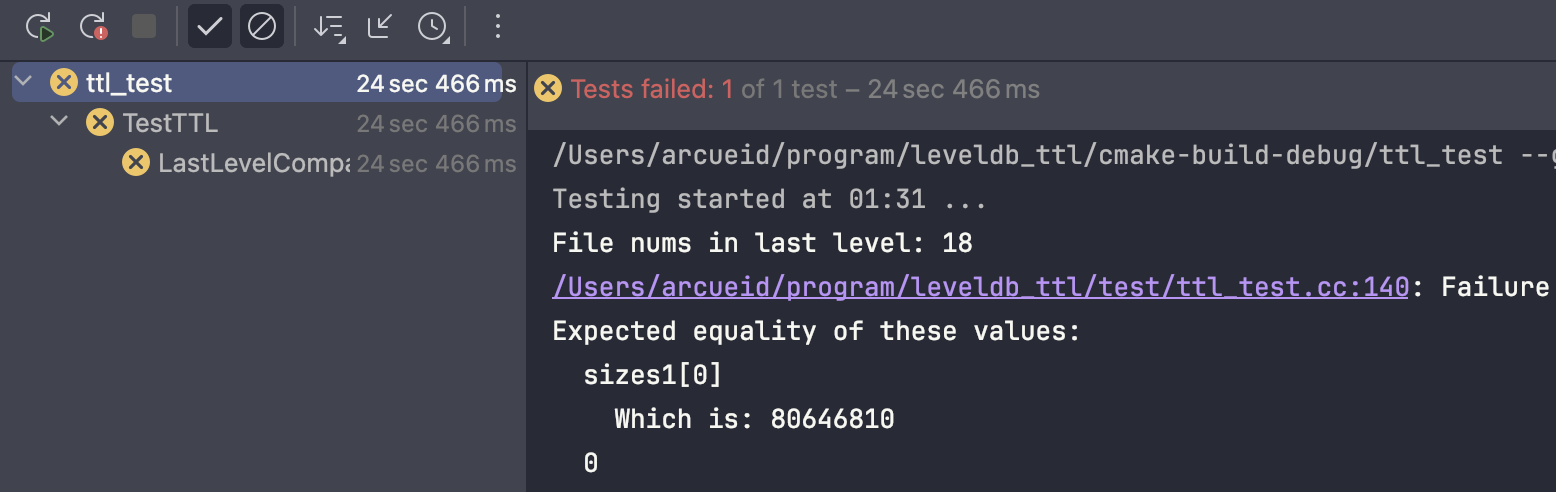
而采用上述直接添加一层循环并且跳过最底层避免崩溃的方法则无法通过测试:
naive_version分支:简单增加一层循环并跳过最底层合并,无法清除最底层过期数据,因此无法通过测试
最后,展示三个测试样例一起运行的结果:
